
答案:2653631372
#include
#include
#define ll long long
using namespace std;
ll dp[2022];
int main()
{
memset(dp,0x7f,sizeof(dp));//初始化最大值(7F是127);
dp[0]=0;//根据题意,当子树为空时权值为0;
//dp[i]代表有i个结点来组成这棵树
for(int i=1;i<=2021;i++)//自下而上;
for(int j=0;j<i;j++) //j是枚举所有左子树中结点的个数
dp[i]=min(dp[i],1+2*dp[j]+3*dp[i-1-j]+j*j*(i-1-j));
cout<<dp[2021]<<endl;
return 0;
}
【解析】
知识点----动态规划(树形dp?)
注意事项:动态规划永远要记得给某些子状态进行初始化!注意在循环时从几开始
是求最小权值,下图里写错了!!!




【解析】
法I a的ASCII是97,A是65,所以可以遍历字符串把每一个>=97的值都-32输出
一开始自己写的代码:用的是ASCII码
#include
#include
#include
using namespace std;
//a~97 A~65
int main(){
string myS;
cin>>myS;
for(int i=0;i=97)
myS[i]-=32;
}
cout<<myS;
}法II使用库函数
然后发现还有一个toupper() 函数, int toupper(int c) ,用来将小写字母转换为大写字母。 只有当参数 c 是一个小写字母,并且存在对应的大写字母时,这种转换才会发生。
需要#include
#include
#include
#include
#include
using namespace std;
//a~97 A~65
int main(){
char c;
while(cin>>c){
cout<<(char)toupper(c);
}
return 0;
}
如图,小写转大写的效果
同理,那么大写转小写也有一个库函数那就是tolower()
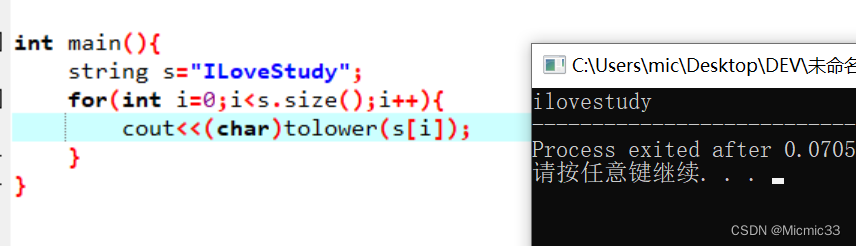
一开始都没有看出这两个就是toUpper和toLower的拼写。。。


【解析】
首先观察这个数列,第一大项是1~1,第二大项是1~2,第n大项就是1~n
题目要求给出左右端点就能算出这一段的和是多少
如何求区间之和呢?用前缀和算,然后右端点和左端点-1的前缀和做个差就行
前缀和怎么算呢?题解是找到规律,我也没想到更合适的法。。
我们现在找到规律后只能算出按规律分块时,到每一块的前缀和,但是询问的区间可能会包含下一个块的一部分。因此我们用二分确定前面有多少个完整的块,就能算出这些块的和S1。后面不完全的从1开始的数用一共有n-(前面分块数)个,用等差数列再算后边这一坨的和S2,答案就是S2+S1

二分代码不太明白,多理解几遍
#include
using namespace std;
typedef long long ll;
//到第n 块 的前缀和
ll cal1(ll n){
return n*(n+1)*(n+2)/6;
}
//在某一个从1开始的块中,前n个数的和
//或者是求从第1个块开始到第n块一个有多少个数
ll cal2(ll n){
return n*(n+1)/2;
}
// 二分 查看第n个数前面有多少个完整的块
ll getSeg(ll n){
ll l=1,r=1e9,mid,ans;
while(l<=r){
mid=l+(r-l)/2;
//块数少了,加起来到不了第n个数
if(cal2(mid)>T;
while(T--){
cin>>l>>r;
cout<<solve(r)-solve(l-1)<<endl;
}
return 0;
}


【思路】
显然这是一道经典的数位dp
数位dp一般用于统计一个区间内满足一些条件的个数。
数位dp的实质就是换一种暴力枚举的方式,使得新的枚举方式满足dp的性质
然后记忆化就可以了
如果我们想求一个区间内满足条件的个数,最简单的暴力是
for(int i=l;i<=r;i++)
if(check(i)) ans++;这太暴力了,毫无状态可言,也毫无记忆化可言,要优化。
新的枚举是控制上界枚举,从最高位开始往下枚举

因此,main函数这样写
int main(){
long long l,r;
while(cin>>l>>r)
cout<<( solve(r)-solve(l-1) );
}数位dp的模板
typedef long long ll;
int a[20];
ll dp[20][state]; //不同题目状态不同,前面代表当前位置,后面代表状态
ll dfs(int pos,bool lead,bool limit){
//参数有state变量,前导零,数位上界变量
if(pos==-1) return 1; //这是递归的边界,因为按位枚举最低位是0,因此pos==-1代表这个数已经 被枚举完了
//一般来说是返回1,表示枚举的这个数是合法的(前边也都是合法的)
//之后就是进行记忆化(在此之前,根据题目的不同,可能还要剪枝)
if(!limit && !lead && dp[pos][state]!=-1) return dp[pos][state];
int up=limit?a[pos]:9; //判断枚举的上界up
ll ans=0;
//开始计数
for(int i=0;i>l>>r){
//初始化dp数组为-1
cout<<solve(r)-solve(l-1);
}
}存疑的地方:为什么记忆化的时候必须要是!limit
举例说明:当前题目的约束是数位上不能出现两个连续的1,我们把区间设为[1,210]
状态:dp[pos][pre]代表枚举到当前pos位,前面一位是pre,的个数
假如,我们不判limit,直接记忆化:那么假设我们第一次枚举了百位是0,显然后面的枚举limit=false,也就是数位上0到9的枚举,然后当我十位枚举了1,此时考虑dp[0][1],就是枚举到个位,前一位是1的个数,显然dp[0][1]=9;(个位只有是1的时候是不满足的),这个状态记录下来,继续dfs,一直到百位枚举了2,十位枚举了1,显然此时递归到了pos=0,pre=1的层,而dp[0][1]的状态已经有了即dp[pos][pre]!=-1;此时程序直接return dp[0][1]了,然而显然是错的,因为此时是有limit的个位只能枚举0,根本没有9个数,这就是状态冲突了。有lead的时候可能出现冲突,这只是两个最基本的不同的题目可能还要加限制,反正宗旨都是让dp状态唯一。
总结一下,要注意的就是前导0出现在两个地方,和与它在那些地方一同出现的limit写法差不多
遇到不符合约束条件的就continue
其次就是solve函数写法记一下。
另外,在调用solve之前,把dp数组初始化为-1
最重要的是这个dp数组的第2维到底放什么(不要62放的是前一位是不是6,windy数放的是前一位的值,这道题放的是当前1的个数)
#include
#include
#include
using namespace std;
typedef long long ll;
ll dp[105][55];
int limit[105];
int k;
ll dfs(int pos,int sum,int limit){
if(pos==-1) return sum==k;//这个return sum==k就很巧妙,如果满足1的个数,才会返回1(而不是像模板一样不管啥,只要枚举完所有就返回1)
if(!limit && dp[pos][sum]!=-1)
return dp[pos][sum];
int up=limit?a[pos]:1;
ll ans=0;
for(int i=0;i>n>>k;
cout<<solve(n);
return 0;
}



