目 录
- 1. 需求背景
- 1.1 大数据可视化面临的挑战
- 1.2 大数据数据可视化的目标架构
- 2. Apache Superset简介
- 2.1 Apache Superset是什么?
- 2.2 为什么选Apache Superset?
- 2.3 对比Metabase
- 3. 快速上手
- 4. 部署安装
- 4.1 部署方式及版本
- 4.2 配置需求
- 4.3 下载安装
- 4.3 安装注意及排错
- 4.4 启动与关闭
- 5. 用户手册(重点)
- 5.1 新建Databases(数据库)
- 5.2 新建Datasets(数据集,老版本也叫Tables)
- 5.3 SQL Lab(SQL实验室)
- 5.4 创建Charts(图表)
- 5.5 创建Dashboards(仪表盘)
- 6. 设置
- 6.1 角色列表及权限
- 6.2 用户列表
- 6.3 操作日志
- 6.4 用户信息、退出、版本信息
- 6.5 语言选择
- 6.6 管理设置
- 6.7 `+ NEW`
1. 需求背景
1.1 大数据可视化面临的挑战
大数据的兴起,关于数据的存储、计算技术层出不穷,但是最终的数据可视化呈现,数据的探索,也成为颇为重要的一环,这一块并没有像存储、计算技术栈那么百花齐放,大家在做大数据可视化时是否也曾有这些困惑呢?
- 传统的可视化对接传统数据库,对大数据组件的hive,spark,presto、elasticsearch、clickhouse等兼容性差,甚至不兼容,每次还需要多一道将大数据集群数据分发到传统数据库的冗余操作;
- 商用产品昂贵、甚至产品设置技术壁垒,很多甚至要求对接该商家的自己的大数据技术方可对接;
- 群众基数大的Excel拖来拽习惯、SQL操作的方便性,排斥自成一派的新技术,网页版账号登录优于用户下载客户端登录;
- 公司开发人员配置紧张,没有多余的人力自研大数据可视化平台,但是决策层希望有一个统一的可视化平台。
诸如此类,确实令人头疼,现在就推荐一款解药Apache Superser——开源的大数据分析探索、可视化报表的神器。
1.2 大数据数据可视化的目标架构

做事还是需要立一个目标架构,最后所有的事情都是围绕目标架构展开,才能越做越轻松,如图1.2,可是架构分为三个梯队;
- 第一梯队:ClickHouse、DorisDB、Kylin等优秀OLAP技术做存储,利用自带的连接引擎,快速响应,同时支持实时数据和离线数据的接入,外接可视化平台,通过权限管控后呈现给用户;
- 第二梯队:数据存在数据仓库Hive内或者NoSQL的Hbase,再通过较为优秀且高效的引擎Presto、Flink、Spark等接入可视化平台,通过权限管控后呈现给用户;
- 剩下就是一个特殊的,如MySQL,临时文件等文件的接入;
注意:常用的也还有其它技术架构,如ELK架构,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。 kibana 也是一个开源和免费的工具,他Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。这个后续再讲,这里书归正传,先讲讲Apache Superser。
2. Apache Superset简介
2.1 Apache Superset是什么?
Apache Superset是一款由Python语言为主开发的开源时髦数据探索分析以及可视化的报表平台;她支持丰富的数据源,且拥有多姿多彩的可视化图表选择。
官网:https://superset.apache.org/github:https://github.com/apache/superset国内支持的镜像站:阿里云:http://mirrors.aliyun.com/pypi/simple/、豆瓣:https://pypi.douban.com/simple/ 等开发语言:Python为主

2.2 为什么选Apache Superset?
- 支持丰富的数据库作为数据源,基本上平时用到的数据库都支持;如图2.2.0,支持的数据源有:
Amazon AthenaAmazon RedshiftApache DrillApache DruidApache HiveApache ImpalaApache KylinApache PinotApache SolrApache Spark SQLAscend.ioAzure MS SQLBig QueryClickHouseCockroachDBDremioElasticsearchExasolGoogle SheetsHologresIBM Db2IBM Netezza Performance ServerMySQLOraclePostgreSQLTrinoPrestoSAP HanaSnowflakeSQLiteSQL ServerTeradataVertica

- 多姿多彩的可视化图表,Apache Superset拥有非常丰富的图表,来实现不同的可视化需求,如图2.2.1。
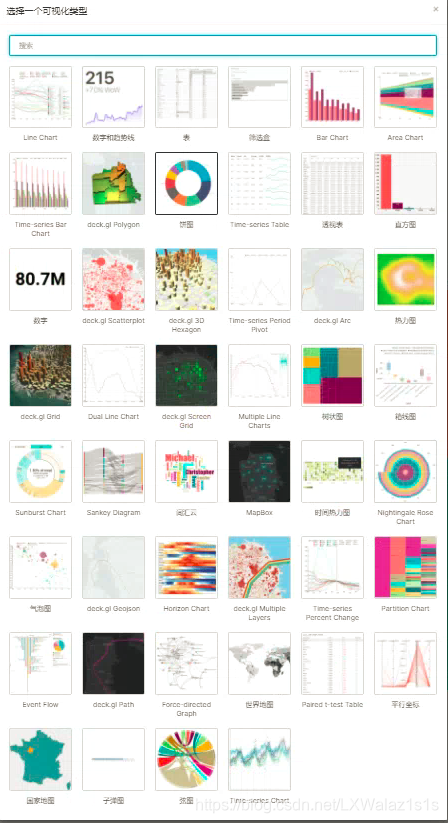
-
轻量级和高度可扩展,利用现有数据基础模型的直接进行数据探索和可视化呈现,而不需要另一个摄取层,如图2.2.2,配置好数据库后,进入
图2.2.2 Apache Superset的SQL LabSQL Lab(SQL实验室),就可以对数据进行探索分析,SQL Lab更像是一个数据库连接查询客户端,当然要更好的数据可视化呈现,还必须结合图表和仪表盘功能。
-
使用简单,如图2.3.3,
Apache Superset使用层面主要分为以下个部分;
Data:主要功能是新增数据源和数据集Dataset(旧版本也叫Table),Dataset作为数据图表可视化的基础;Charts:图表,就是针对准备好的Dataset数据集,选择一款合适的图表呈现;Dashboards:仪表盘,其实就是报表、看板大屏展示,可以将多个Charts组合到一个仪表盘内一起展示。SQL Lab:SQL实验室,其实就是一个类似DBeaver、Navicat、DataGrip等一样的多功能数据库连接客户端,但是只有查询功能,配置驱动和连接后可以进行数据库、表、字段等模型的SQL查询操作。设置:语言选择,登录注销、人员权限,操作日志等设置;
2.3 对比Metabase
之前博主也写过一篇关于Metabase的大数据可视化神器Metabase——开源的大数据分析探索、可视化报表神器的博客,那么对于与Metabase,Apache Superset有哪些优劣呢;
- 天生自带支持的数据源Apache Superset完胜Metabase;
- 数据图表形式Apache Superset完胜Metabase;
- 操作界面美观丝滑度Apache Superset稍逊Metabase;
- 托拉拽操作Apache Superset稍逊Metabase;
向来博主都是鱼与熊掌能兼得就兼得,毕竟小孩才做选择嘛,可以考虑两个都装,Metabase用于专注业务数据需求人员,Apache Superset用于懂SQL的数据需求人员,二者生成的通用仪表盘,则可以利用一个统一的网页超链接到一起,形成一个统一的报表平台。
3. 快速上手
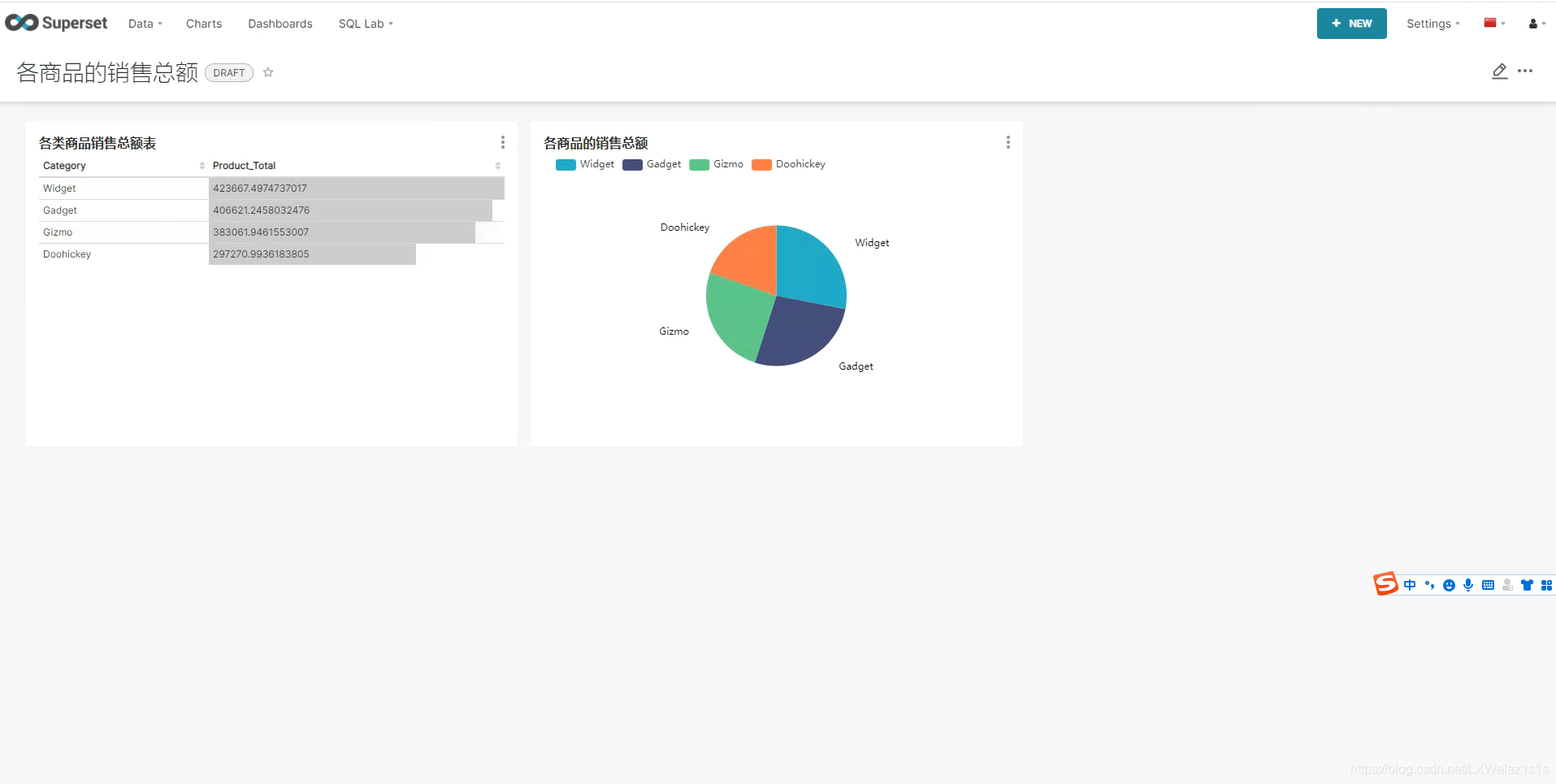
这里先快速上手带大家体验一把,细节后续章节细讲,首先配置好数据库连接(配置方法参考后续的5.1 新建Databases(数据库)),然后打开SQL Lab,选择好配置数据库,写SQL语句分析探索数据,如图3.1.0,然后运行语句,得到数据结果,可以点击保存将常用的探索SQL保存下来,然后点击查询结果上方的EXPLORE按钮,就可以跳转图表分析图3.1.1;
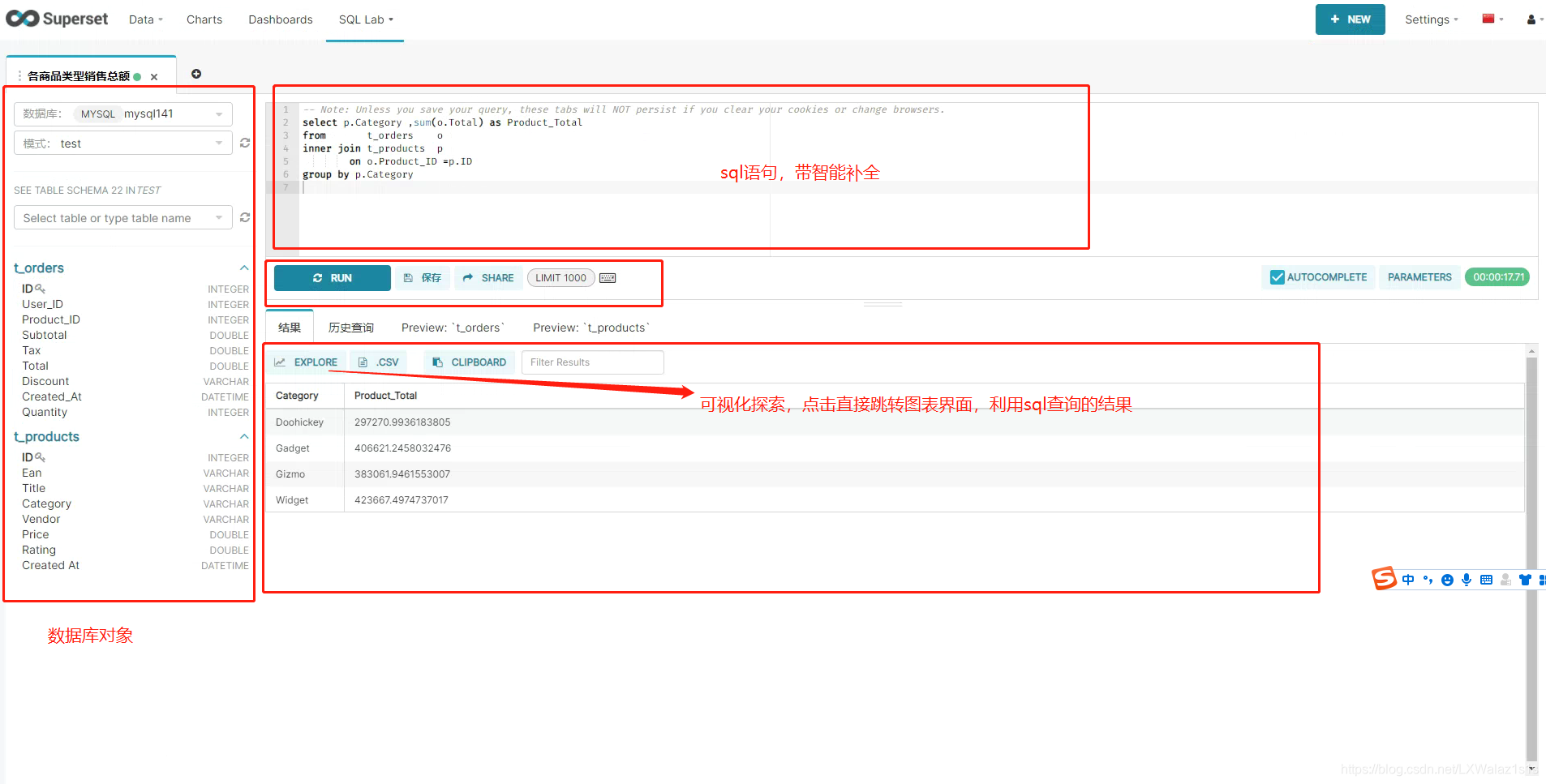
利用SQL Lab探索得到的数据集,选择合适需求的数据图表,选择合适的指标,度量值,点击上方的RUN就可以得到结果,非常的方便,可以直接点击上方的SAVE保存图表;

新建Dashboard,然后编辑Dashboard,将之前生成好的Charts(图表)拖拽到Dashboard,就完成了数据仪表盘的最终呈现,然后就可以分享给需求方,也可以生成访问链接分享。
注意:拖拽时尽量往Dashboard的上面拖拽,会出现一条蓝色的分界线就可以松手,否则可能出现无法拖拽的情况,这个设计很坑。
4. 部署安装
4.1 部署方式及版本
- 支持Linux、Windows、Mac的Docker部署
- 支持Linux、Windows、Mac的Python环境代码部署
- 可以在github,官网、或者国内镜像网站查看版本,但是别先下载,因为Apache Superset依赖包很多,最好能在线安装;
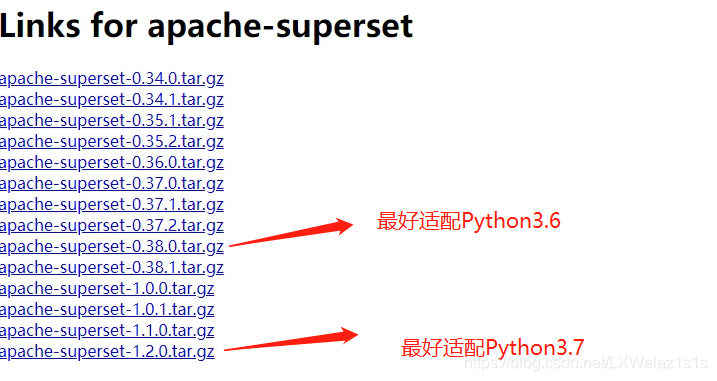
- 博主选的是
apache-superset-0.38.1.tar.gz在Linux上的Python环境代码部署。
4.2 配置需求
apache-superset-0.38.1.tar.gzCentOS 7 16核 32G(非硬性,一般性能的服务器即可)Python 3.6要求服务器网,如果没有,可以使用能联网的代理服务器,依赖很多,采用在线安装的形式
4.3 下载安装
-
下载安装
Python3.6,可以选择安装anaconda集成的python,可以参考博客Linux通过anaconda来安装python,对应的版本是Anaconda3-5.2.0-Linux-x86_64.sh,下载传送门:Anaconda Download;安装好以后,如果老的服务器上存在python2,默认的环境变量启动是python2,没关系,只需要设置一个新的环境变量确保python3启动是刚刚安装的版本即可。 -
安装python虚拟机,并启动,然后安装Apache Superset。
# 切换到自己安装软件的目录,博主的是在/usr/local/tools,并新建superset目录
cd /usr/local/tools
mkdir superset
cd superset
# 安装虚拟机,有网就不需要的代理服务器,配置代理服务器10.212.18.34:3129方法:
# 写入配置文件 /etc/profile里面追加
# export http_proxy=10.212.18.34:3129
# export https_proxy=10.212.18.34:3129
# 然后wq! 保存退出,source /etc/profile刷新配置文件
# 安装完可以删除代理,记得再source /etc/profile
# 如果不想配置/etc/profile或者无权限,可以采用以下命令
# pip install virtualenv --proxy=10.212.18.34:3129,每次都需要,烦
pip install virtualenv
# 配置命名虚拟机
python3 -m venv venv
# 启动虚拟机,会在当前目录下自动创建venv目录
. venv/bin/activate
# 退出虚拟机指令,但是这里不需要退出
# 退出虚拟机指令,但是这里不需要退出
# 退出虚拟机指令,但是这里不需要退出
deactivate
# 安装更新一些依赖
pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/
yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel mysql-devel gcc-devel
# 如果报错:GPG key retrieval failed: [Errno 14] curl#37 - "Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7"
# 解决:
vi /etc/yum.repos.d/epel.repo
gpgcheck=0
# 然后wq!保存再试一次yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel mysql-devel gcc-devel
# 先用官网下载,因为官网的会自动把依赖也给你一起安装了,实在不行再用其他网站的镜像
pip install apache-superset==1.4.2
# 安装superset,指定版本,不指定版本默认是最新版本
pip install superset==0.30.1 -i https://pypi.douban.com/simple
# 安装email_validator
pip3 install email_validator -i https://pypi.douban.com/simple/
# 更新数据库
superset db upgrade
# 创建admin的用户名,用户名随便写,bigdata123,admin都行,写完用户名后会让你输入姓,名,邮箱,这三项可写可不写,不写就直接回车,然后是设置密码,一点要写。
export FLASK_APP=superset
superset fab create-admin
# 加载样例数据,考验网络,如果实在一致加载报错就放弃,不影响后续使用。
superset load_examples
# 初始化
superset init
# 启动,官网是superset run -p 8088 --with-threads --reload --debugger
# 建议用gunicorn启动,方便快速,先直接启动,确保打印在客户端的日志正常
pip install gunicorn
gunicorn -w 5 --timeout 120 -b 10.218.10.290:9089 "superset.app:create_app()"
# gunicorn 是一个Python WEB服务,可以理解为Tomcat
# -w WORKERS:指定线程数
# --timeout:worker进程超时时间,超过会自动重启
# -b BIND:绑定Superset访问地址
# --daemon:后台运行
# 在能访问10.218.10.290:9089的服务器上打开浏览器,输入刚刚登录的用户名,密码即可。
# 如果没开启后台停止,直接ctrl+c关停
# 后台进程停止gunicorn
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
4.3 安装注意及排错
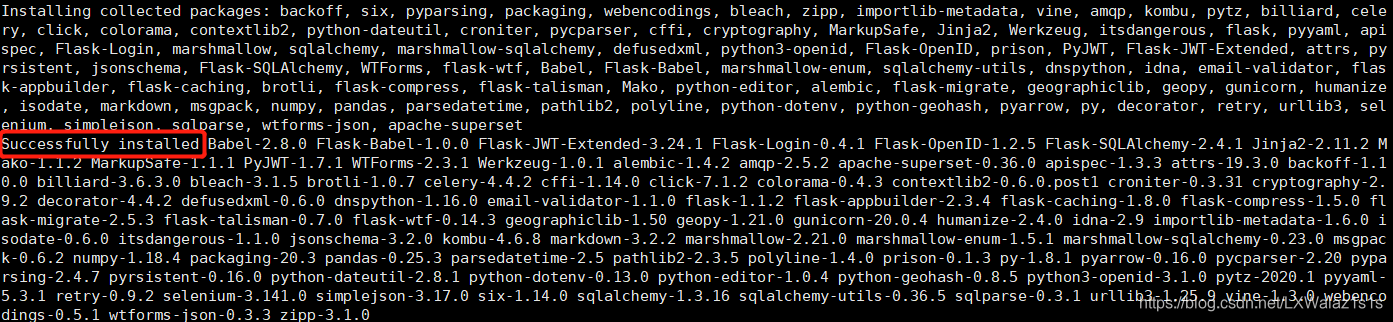
pip install superset步骤时出现关键字眼Successfully installed证明正确安装,如图4.3.0;
superset fab create-admin配置用户名时提示如图4.3.1。

每个人的服务器环境,可能导致缺少的 依赖不同,途中如果遇到bug,可自己百度解决,基本都是python依赖包之类的问题,要耐心。
# 报错
ModuleNotFoundError: No module named 'dataclasses'
# 解决
pip install dataclasses
# 报错
No PIL installation found
# 解决
pip install pillow
一切解决后,网页登录如图4.3.2;
4.4 启动与关闭
官网提供的直接启动的方法不是很好,博主推荐一个采用gunicorn的方法,先关停superset。
#安装好superset后会在venv生成很多文件,切换到venv
cd /usr/local/tools/superset/venv/
#新建日志文件夹
mkdir log
#切换到log目录,新权限 日志,错误日志和启动pid文件
cd log
touch gunicorn_access.log
touch gunicorn_error.log
touch pidfile
chmod 755 ./* #修改权限
#切换到/usr/local/tools/superset/venv/bin,写一个gunicorn配置文件,python语言
cd ./usr/local/tools/superset/venv/bin
vim gunicorn_config.py # 内容如下
#内容开始
import multiprocessing
bind = '10.218.10.290:9089' #绑定ip和端口号
backlog = 512 #监听队列
timeout = 30 #超时
worker_class = 'gevent'
workers = 5
worker_connections = 1000
threads = 2 #指定每个进程开启的线程数
loglevel = 'info' # 日志级别
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' #设置gunicorn访问日志格式,错误日志无法设置
pidfile = '/usr/local/tools/superset/venv/log/pidfile'
errorlog = '/usr/local/tools/superset/venv/log/gunicorn_error.log'
accesslog = '/usr/local/tools/superset/venv/log/gunicorn_access.log'
print("IP and PORT:"+bind)
print("pid_file:"+pidfile)
print("error_log:"+errorlog)
print("access_log:"+accesslog)
#内容结束
#然后 wq! 保存退出
# gunicorn 启动 -c 配置文件启动;--daemon后台启动,日志可以去配置文件指定的路径查看
gunicorn -c ./gunicorn_config.py "superset.app:create_app()" --daemon
# 后台进程查看
ps -ef | grep gunicorn
# 或者通过端口查看
netstata -tunlp | grep 9089
# 或
ss -anp | grep 9089
# 如果没开启后台停止,直接ctrl+c关停
# 后台进程停止gunicorn
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
5. 用户手册(重点)
5.1 新建Databases(数据库)
新建数据库之前,需要先安装该数据库的python驱动包,具体语句可以参考官网Database Drivers,如图5.1.0,一般就是pip install XXX,安装好驱动后,记得重启下Superset服务;
新建数据库连接的作用是为数据集Datasets和SQL实验室SQL Lab提供数据库、表的选择,就是提供数据源,当然Data下还有个Upload CSV(最新版本也支持Upload Excel)也可以直接将本地的CSV文件作为数据源上传到Superset站点,直接进行数据探索分析。
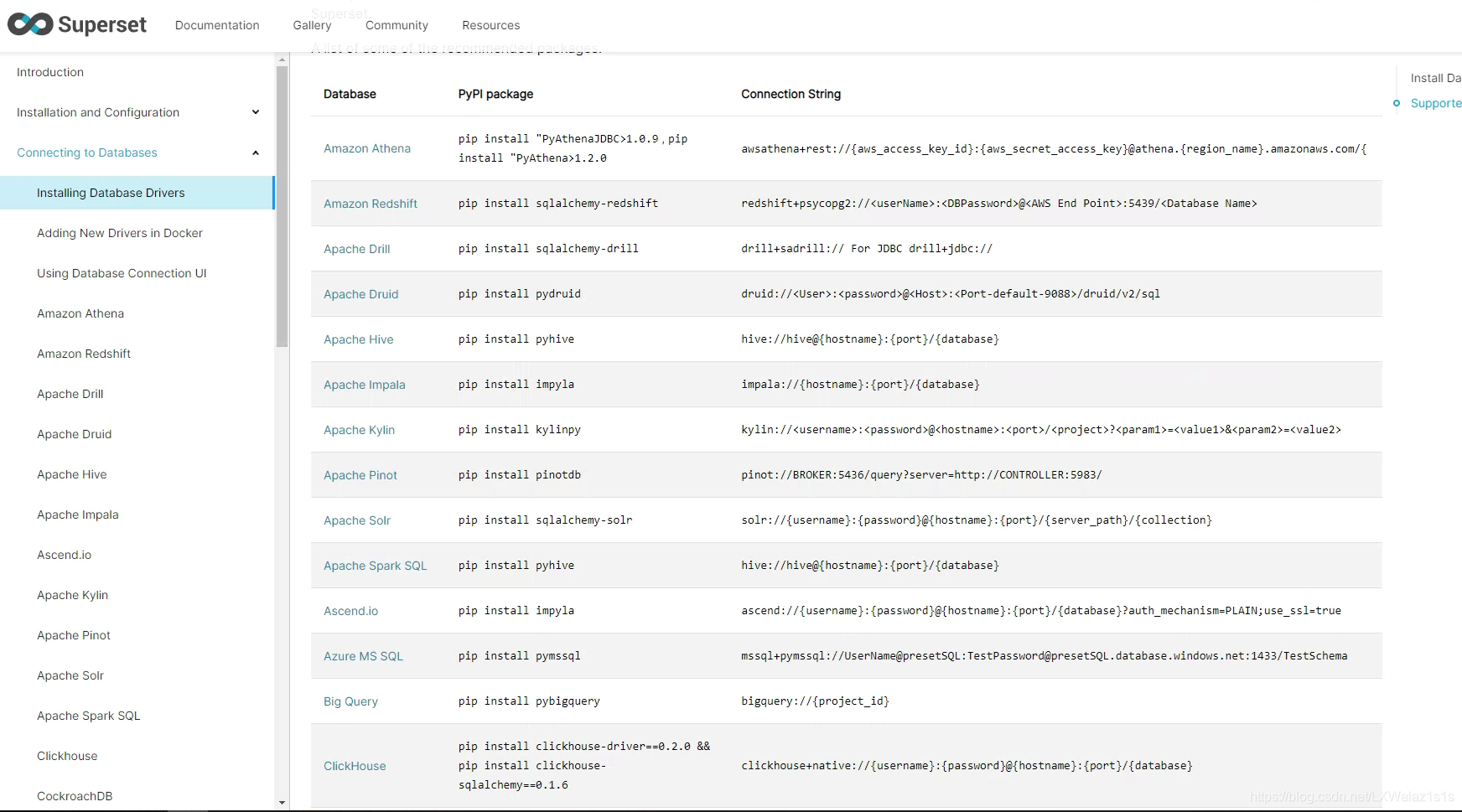
登录进Apache Superset后,点击Data,下来选择Databases,然后跳转到图图5.1.1,点击右上侧的+号就可以跳转图5.1.2的数据新增配置界面。
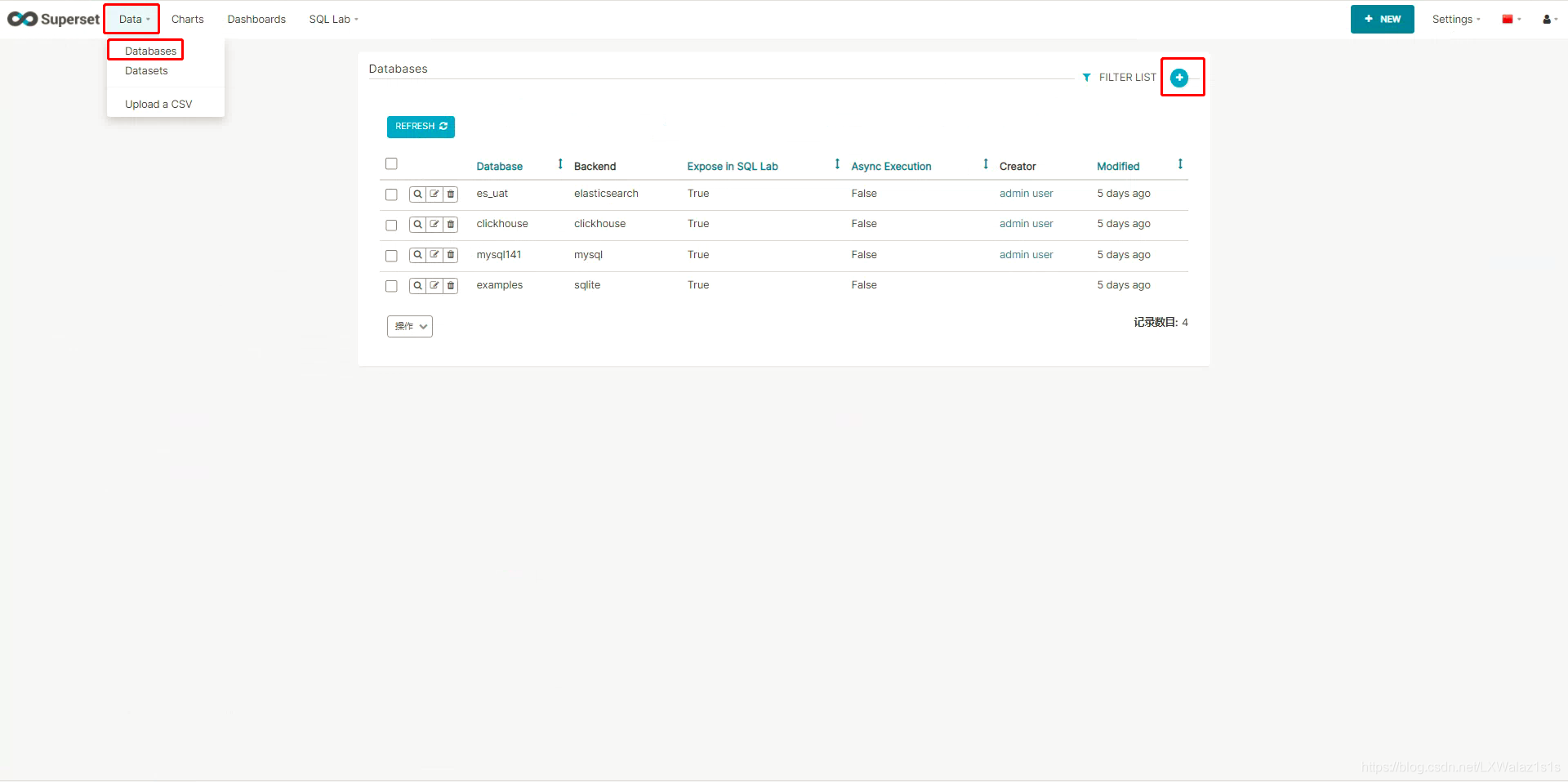
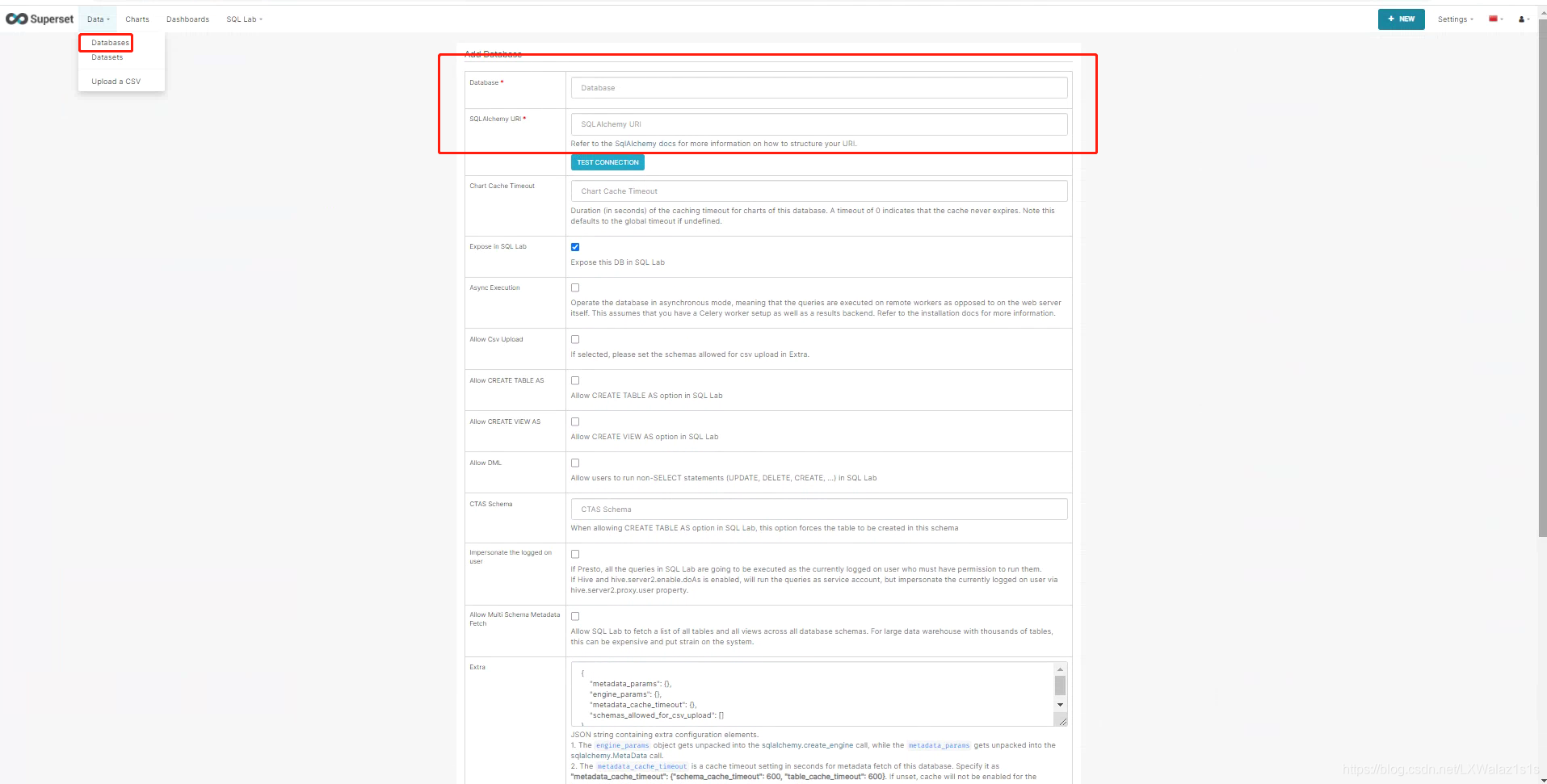
图5.1.2,Database是指的新建这个数据库的显示名称,这个随便取,合理即可,SQLAlchemy URI 这个地方就是之前图5.1.0上的数据库连接字符串,确保和你选择的数据库类型一致。
然后点击TEST CONECTION,连接成功后会跳出Seems OK!的弹出框,记得滑到最下面,点击保存,如果连接不成功,请检查数据库的实例,端口,用户名,密码以及自己部署的Apache Superset的服务器访问数据库的端口网络时是否能通,当然也不要忘记SQLAlchemy URI 填写规范,保存后的数据库连接就会列举在图5.1.1上。
5.2 新建Datasets(数据集,老版本也叫Tables)
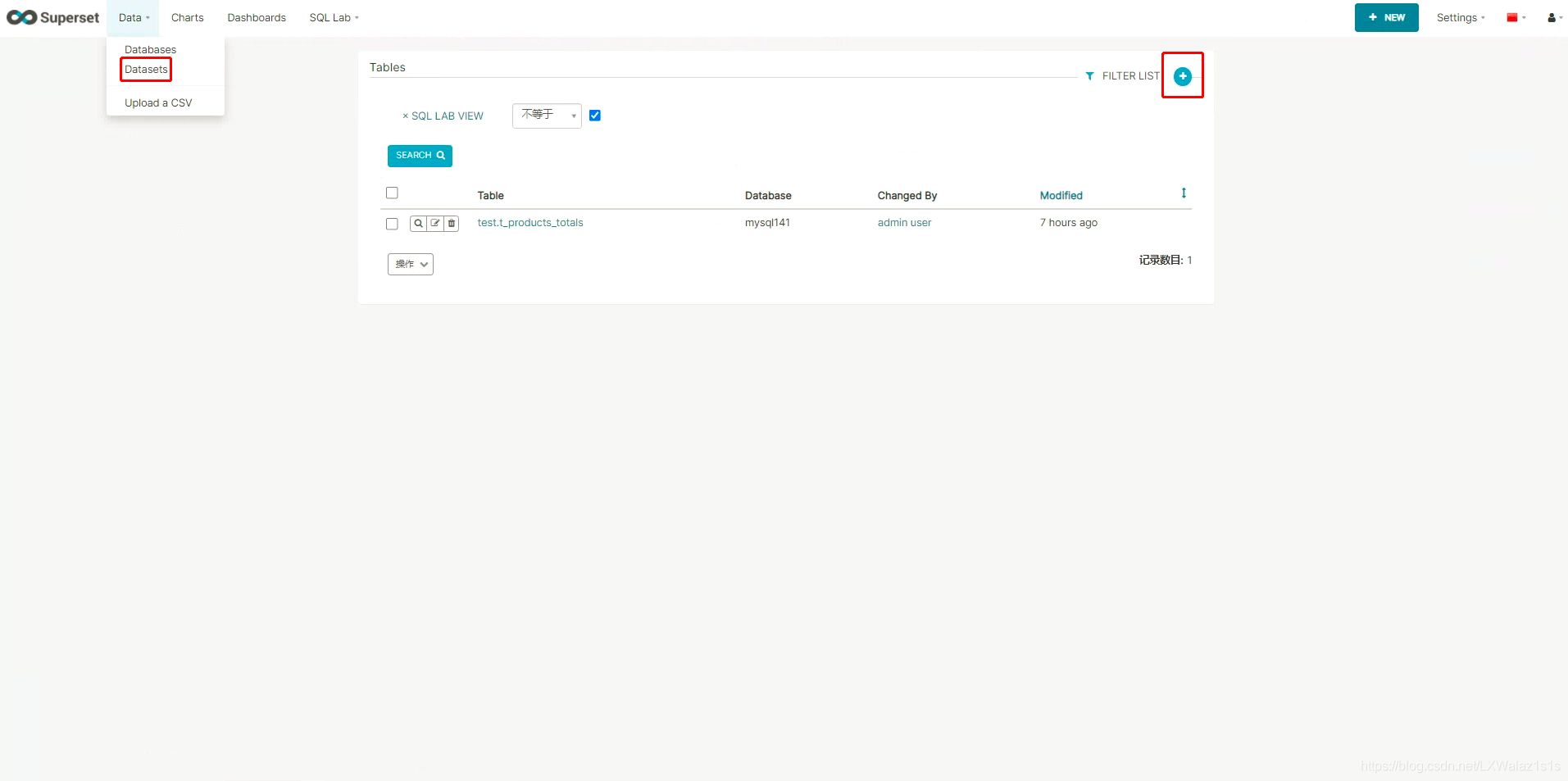
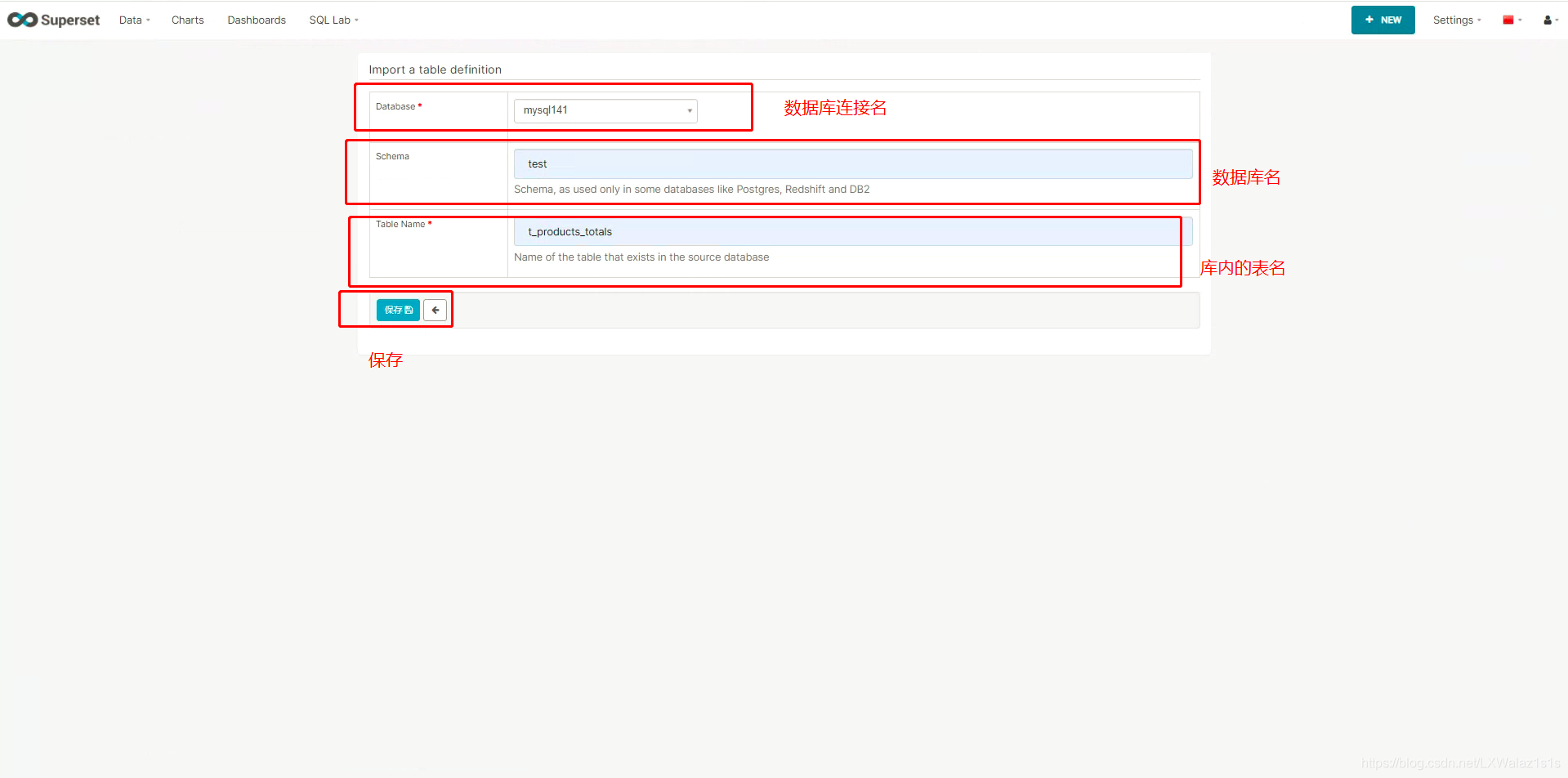
如图5.2.0,点击图中的Data下的Datasets,然后点击+号,跳转到图5.2.1,将配置好的数据库名下拉选出,写一个该连接实例下的数据库,然后选择一张表,点击保存即可,保存好的数据集会列举在图5.2.0中,这些知道为啥老板叫Tabels了吧;
数据集的作用是为后续的Charts(图表)数据可视化作为数据源头。
5.3 SQL Lab(SQL实验室)
SQL Lab其实就是一个数据库查询客户端,利用SQL语句对数据库的表,字段模型进行查询探索,同时支持智能补全,当然SQL Lab的查询结果也可以直接EXPLORE到Charts(图表),作为数据可视化的数据源。
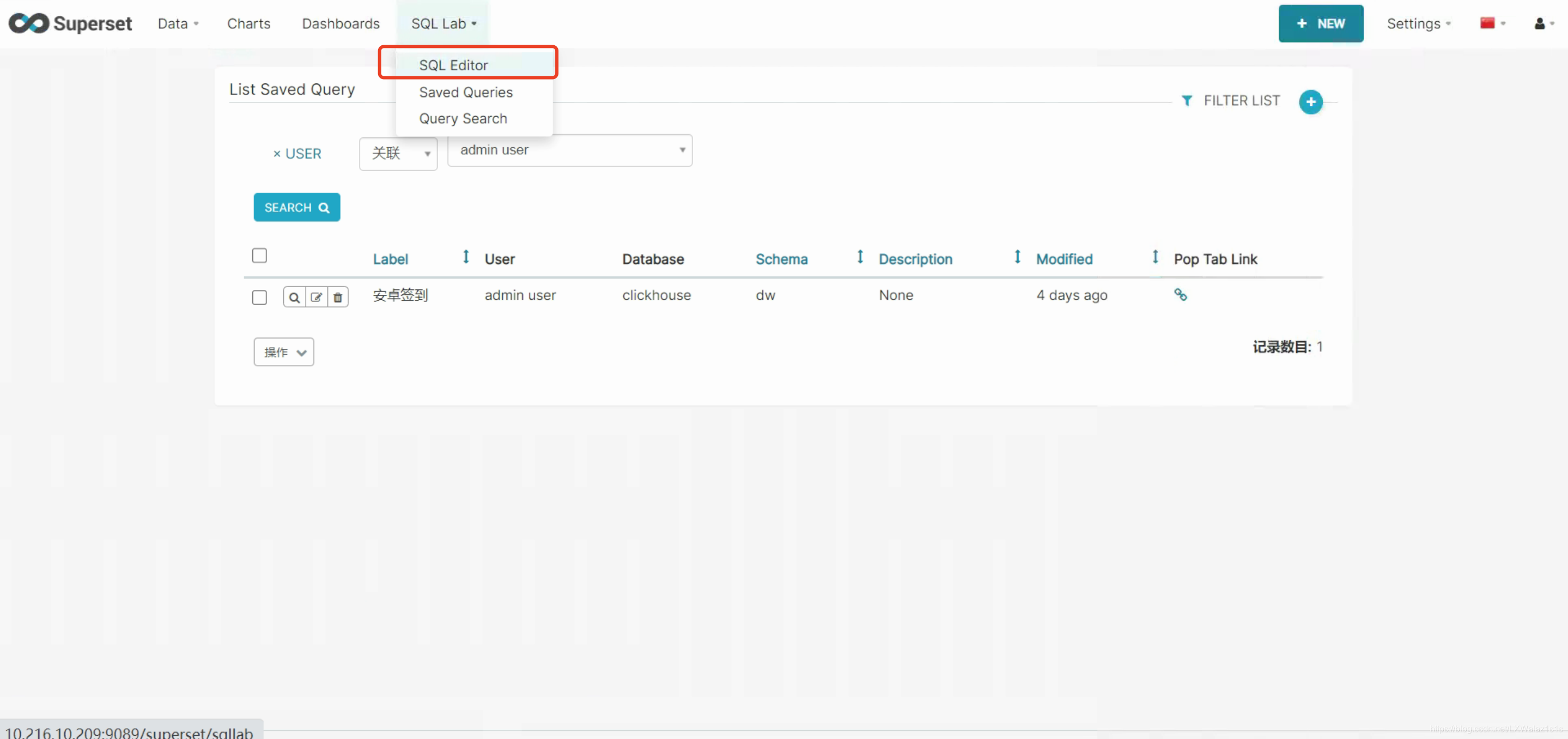
如图5.3.0,SQL Lab有三个选项,三个选项的功能如下:
SQL Editor:进行SQL查询探索Saved Queries:保存的通用查询SQLQuery Search:查询的历史记录
点击SQL Editor进入图5.3.1的SQL查询探索,左侧上方是配置好的数据库连接名和选择的数据库,左侧下方是将要用到的表及字段模型;右侧上方是写SQL语句的地方,支持RUN(查询),RUN SELECTION(查询鼠标选择局部语句),SAVE(保存),SHARE(分享)等,右下方是数据结果,支持EXPLORE到Charts(图表)可视化,.CSV下载,CLIPBOARD(复制到剪贴板)。

5.4 创建Charts(图表)
图表的作用是数据可视化,利不同的图表满足不同的业务需求,图表同时也作为仪表盘的展示的一部分,一个仪表盘内可以展示一个或多个图表。
创建图表的方式有两种:
- 如图5.4.0,点击
Charts,点击+创建新的图表,跳转图5.4.1 - 在
SQL LabSQL语句探索查询的结果直接EXPLORE到Charts(图表)可视化

如图5.4.1,选择合适需求的数据图表(如图5.4.2,支持的图表类型非常丰富,号称最漂亮的可视化图表展示),选择合适的指标,度量值,点击上方的RUN就可以得到结果,非常的方便,可以直接点击上方的SAVE保存图表;
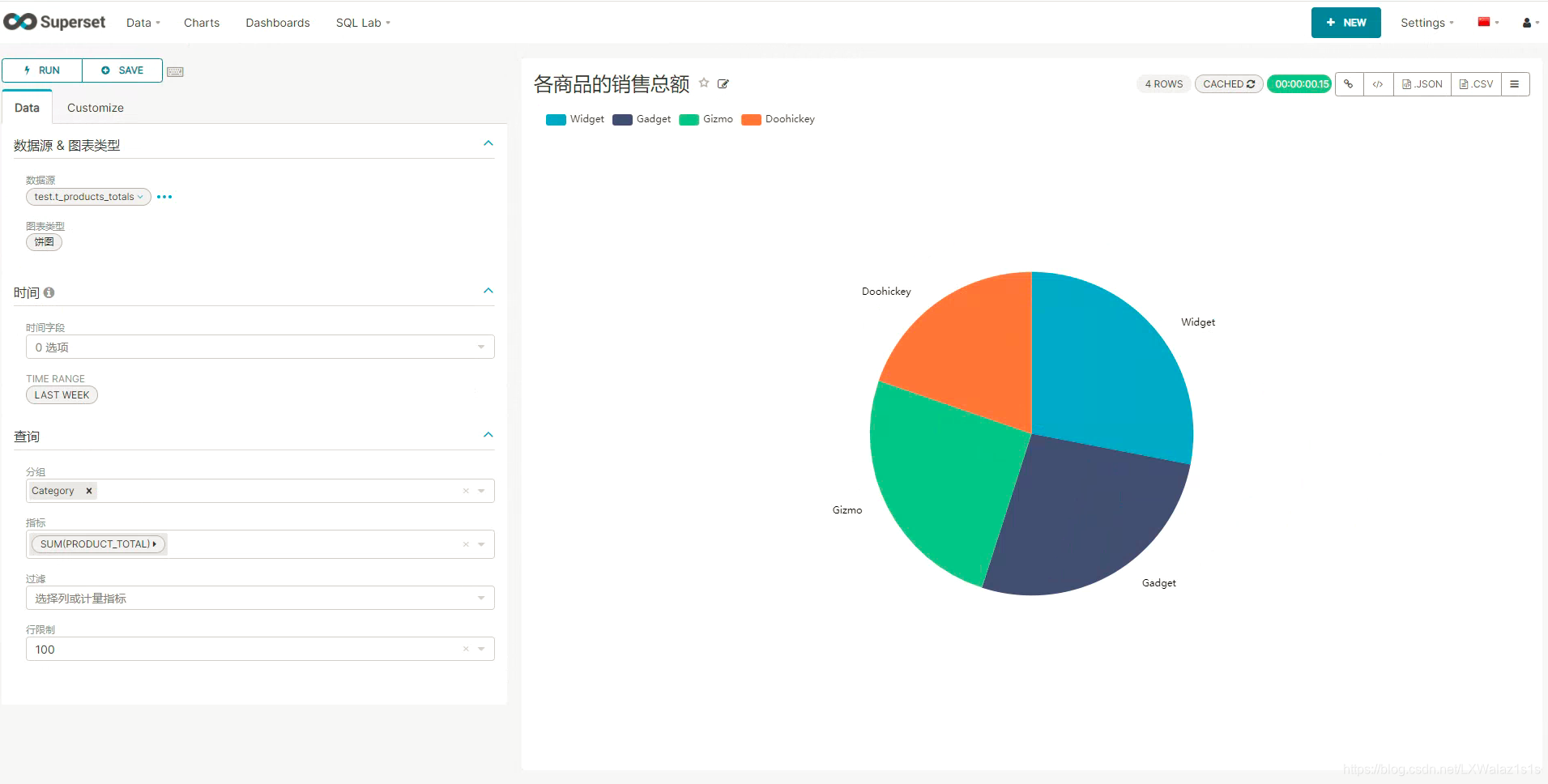
号称最美可视化展示,支持可视化的图表类型确实丰富多彩,应对各种可视化需求。
5.5 创建Dashboards(仪表盘)
仪表盘就是最后的数据总体呈现,即报表展示。
如图5.5.0,点击Dashboards,然后点击+新建仪表盘,跳转图5.5.1。

点击图5.5.1右上角的编辑仪表盘,之前做好的Charts(图表)拖拽到仪表盘上,注意:第一次拖拽的时候尽量网上拖拽,知道出现这个条蓝色的分解线,否则 无法拖拽过去;
同时也支持一些通用的组件,图表旁的Components下,有Header、Tabs、Row、Column、Markdown、Divider;
编辑完后后记得点保存。
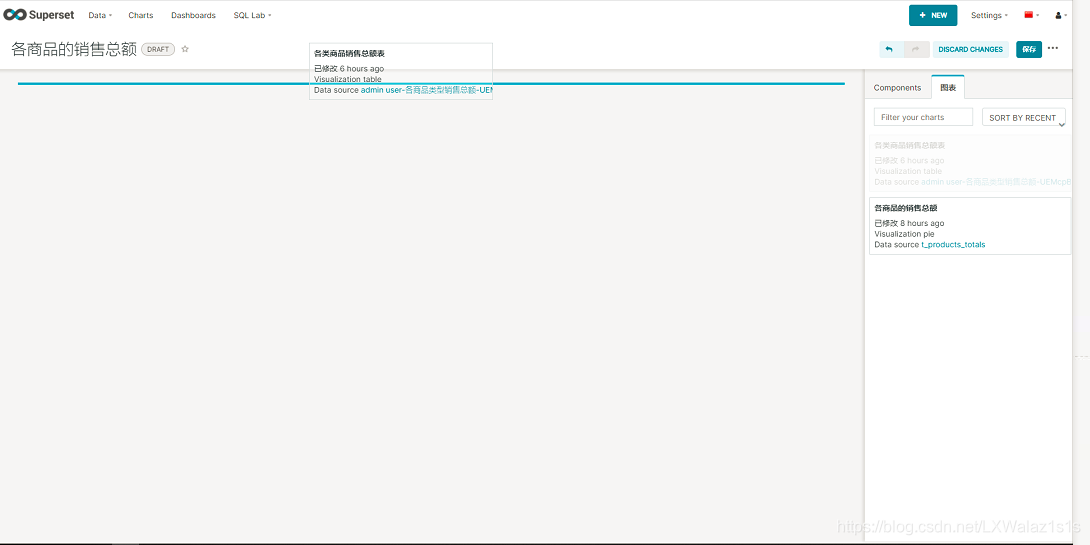
保存后的仪表盘支持分享,下载等功能,同时也会根据图表内的数据源刷新来获取新的数据;
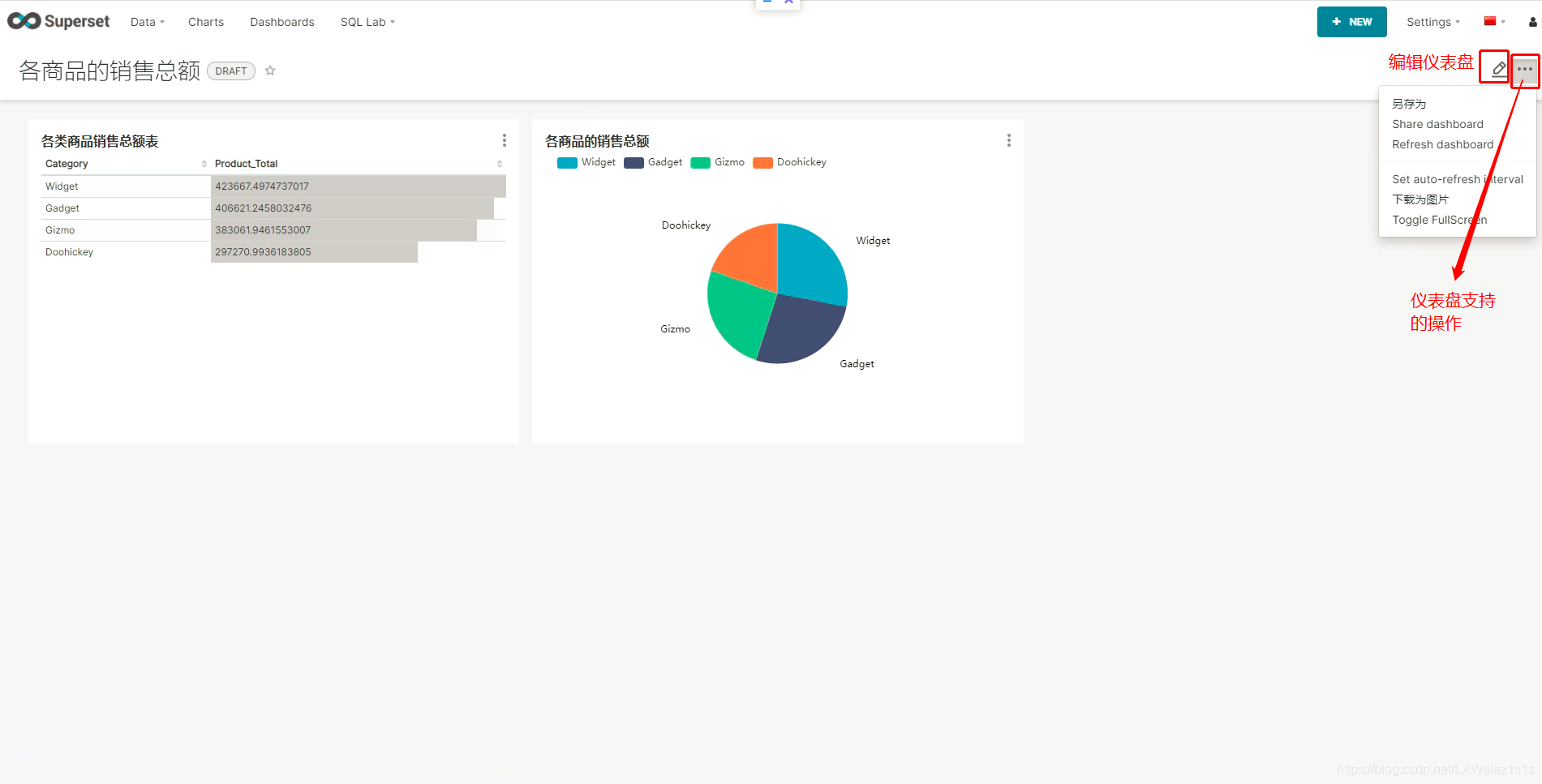
分享给别人看到的仪表盘如图5.5.3。
6. 设置
设置包含在菜单栏Settings下,主要设计权限和操作日志等模块,接下来分别讲解。
6.1 角色列表及权限
Apache Superset中的安全性由Flask AppBuilder(FAB)处理,FAB是一个构建在Flask之上的应用程序开发框架。FAB提供身份验证、用户管理、权限和角色,可以查看其相关文档。
Apache Superset默认提供了不同的角色,每种角色拥有的权限不同,在运行superset init命令时,与每个角色关联的权限将重新同步到其原始值,不建议更改与每个角色关联的权限(例如,通过删除或添加权限),支持admin再自建角色类型,指定想要的权限,默认的角色及权限如下;
-
Admin:管理员拥有所有可能的权限,包括授予或撤销其他用户的权限,以及更改其他用户的切片和仪表板; -
Alpha:Alpha用户可以访问所有数据源,但不能授予或撤消其他用户的访问权限。它们也仅限于改变它们所拥有的对象。Alpha用户可以添加和更改数据源。 -
Gamma:Gamma用户的访问权限有限。他们只能使用来自通过另一个补充角色访问的数据源的数据。他们只能查看由他们可以访问的数据源制作的切片和仪表板。目前Gamma用户无法更改或添加数据源。我们假设他们主要是内容消费者,尽管他们可以创建切片和仪表盘。另请注意,当Gamma用户查看仪表板和切片列表视图时,他们将只看到他们有权访问的对象。 -
sql_lab:sql_lab角色授予对sql lab的访问权限。请注意,虽然管理员用户在默认情况下可以访问所有数据库,但Alpha和Gamma用户都需要在每个数据库的基础上获得访问权限。 -
public:要允许注销的用户访问某些超集功能,需要自己配置权限,并将其分配给另一个角色,您希望将其权限传递给该角色。
更多的角色权限可以查看官网Apache Superset Security,或者点开图6.1.0的编辑角色查看,尽量别改默认角色的权限。
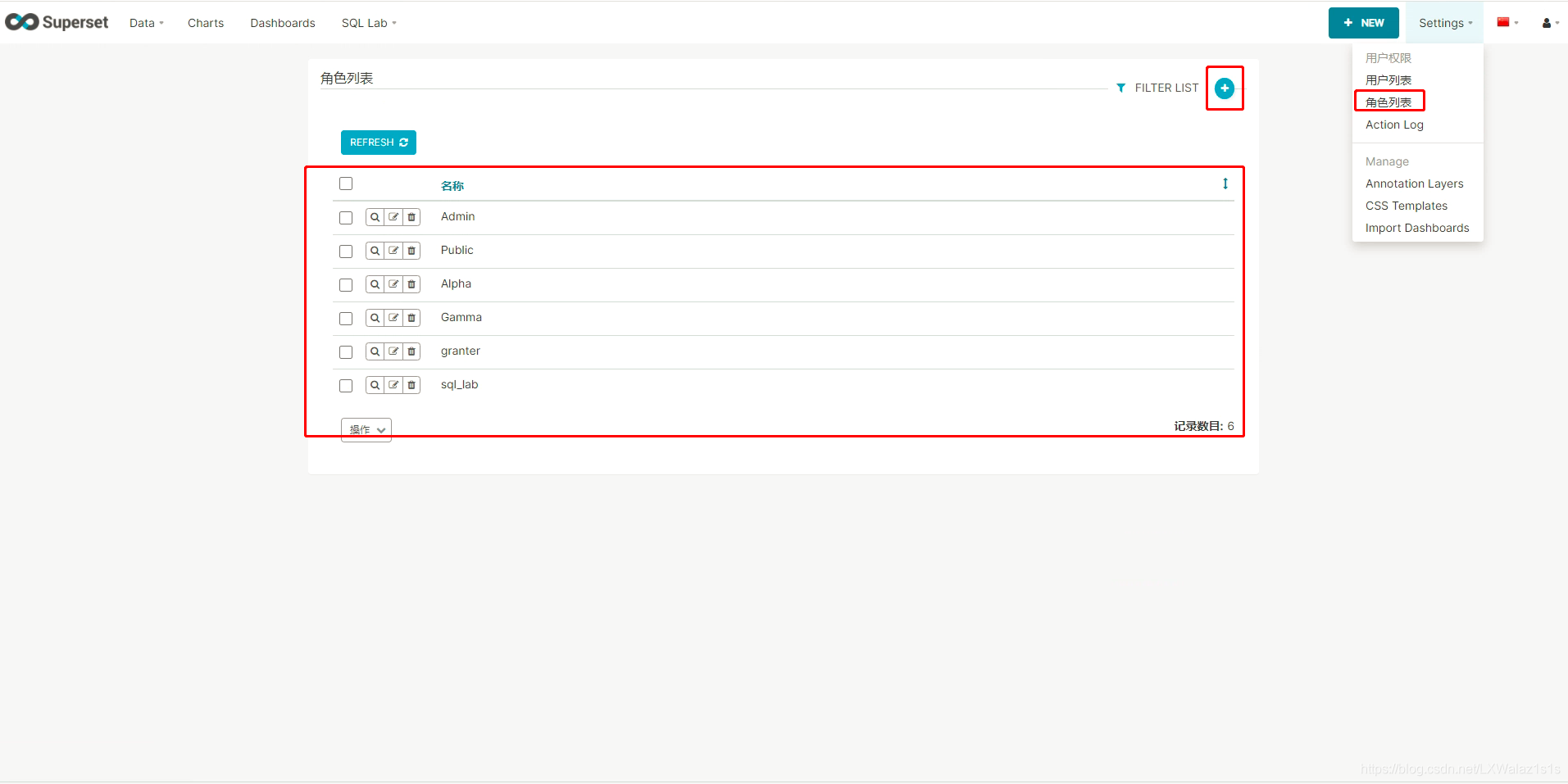
同时Apache Superset也支持管理员自己新增角色,如图6.1.1,新建角色并指定角色权限。
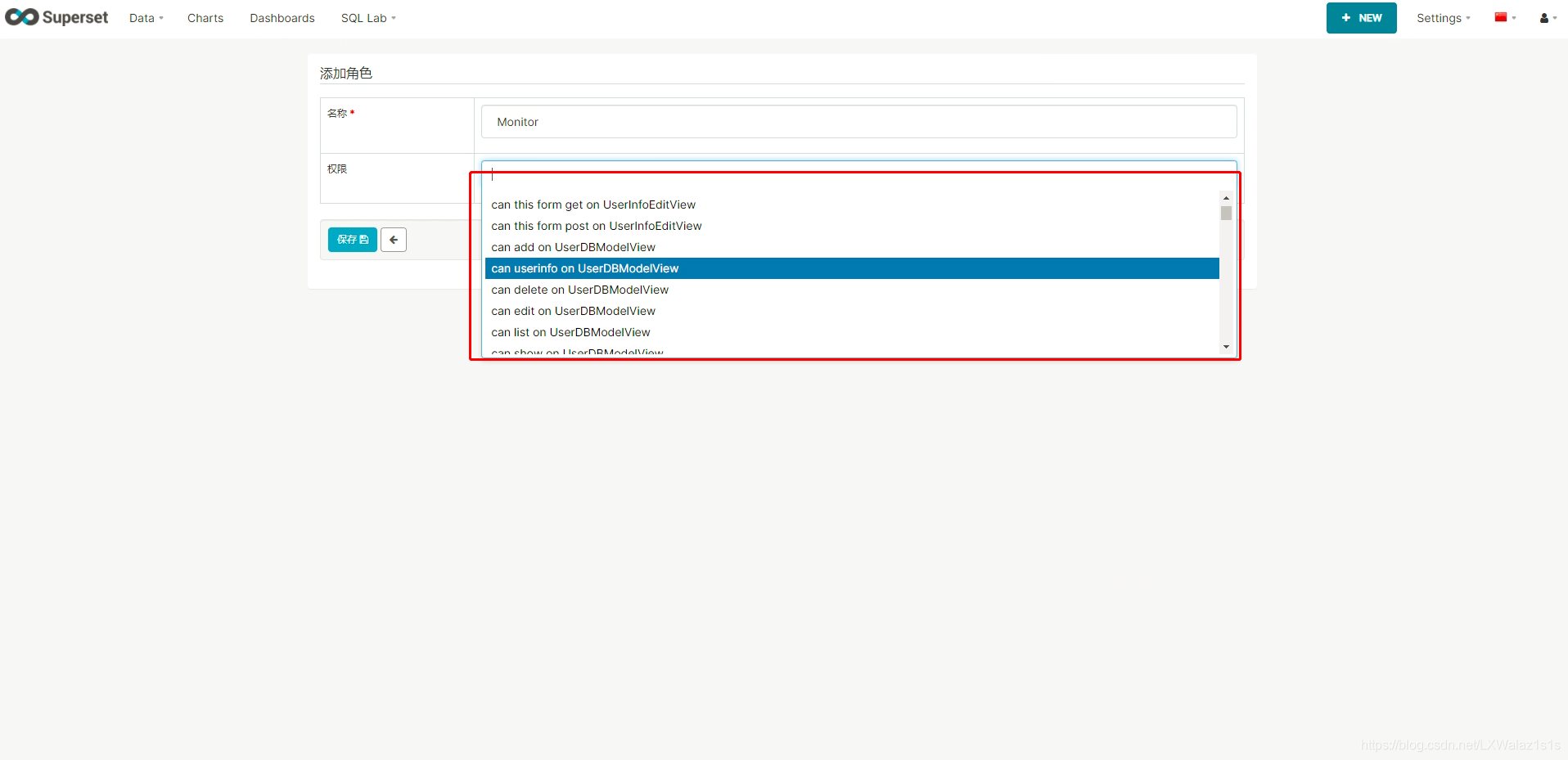
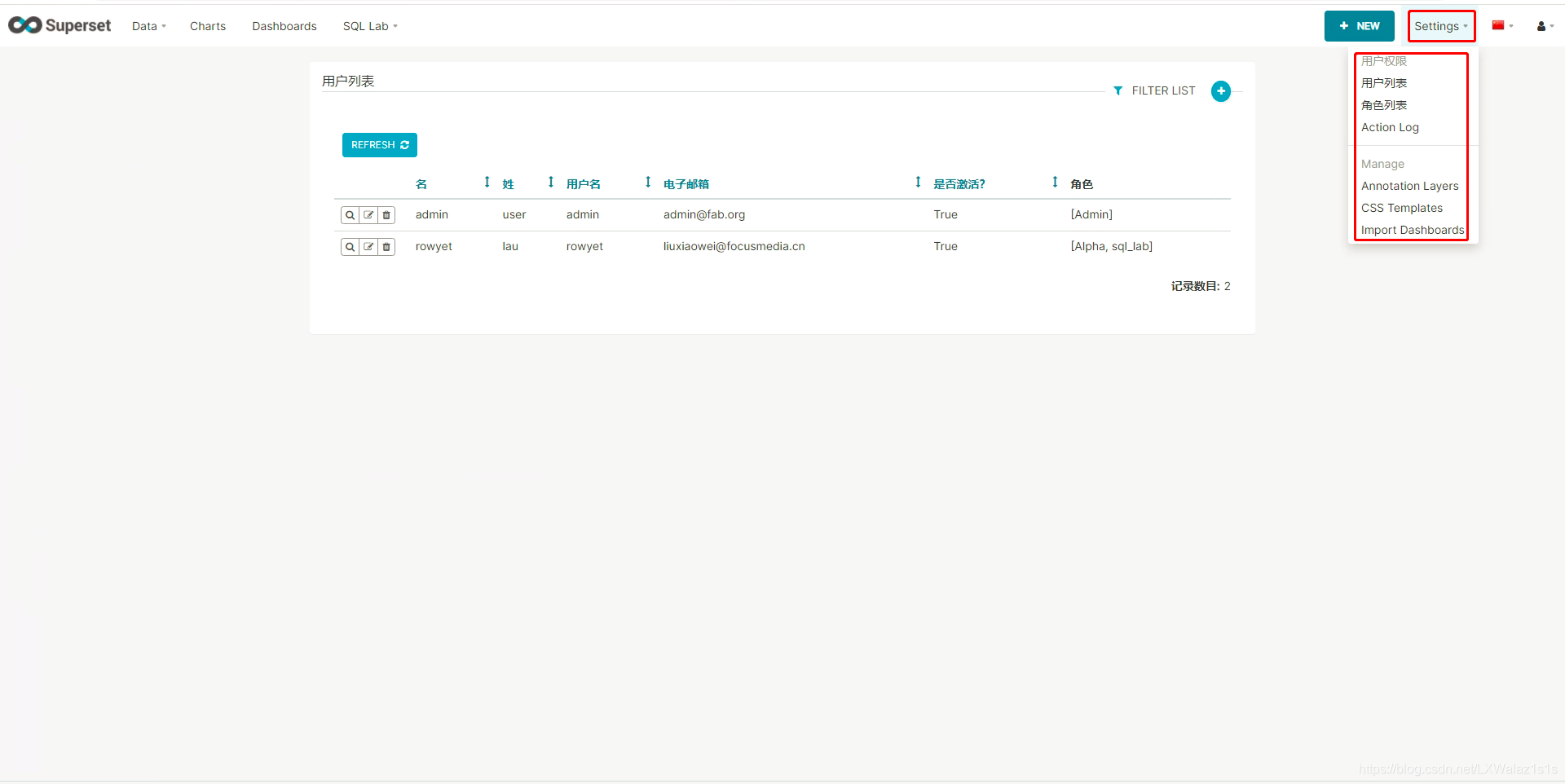
6.2 用户列表
新建、编辑用户指定角色,用户的权限是绑定在角色里面的,一个用户可以有多个角色,配置信息如图6.2.0。

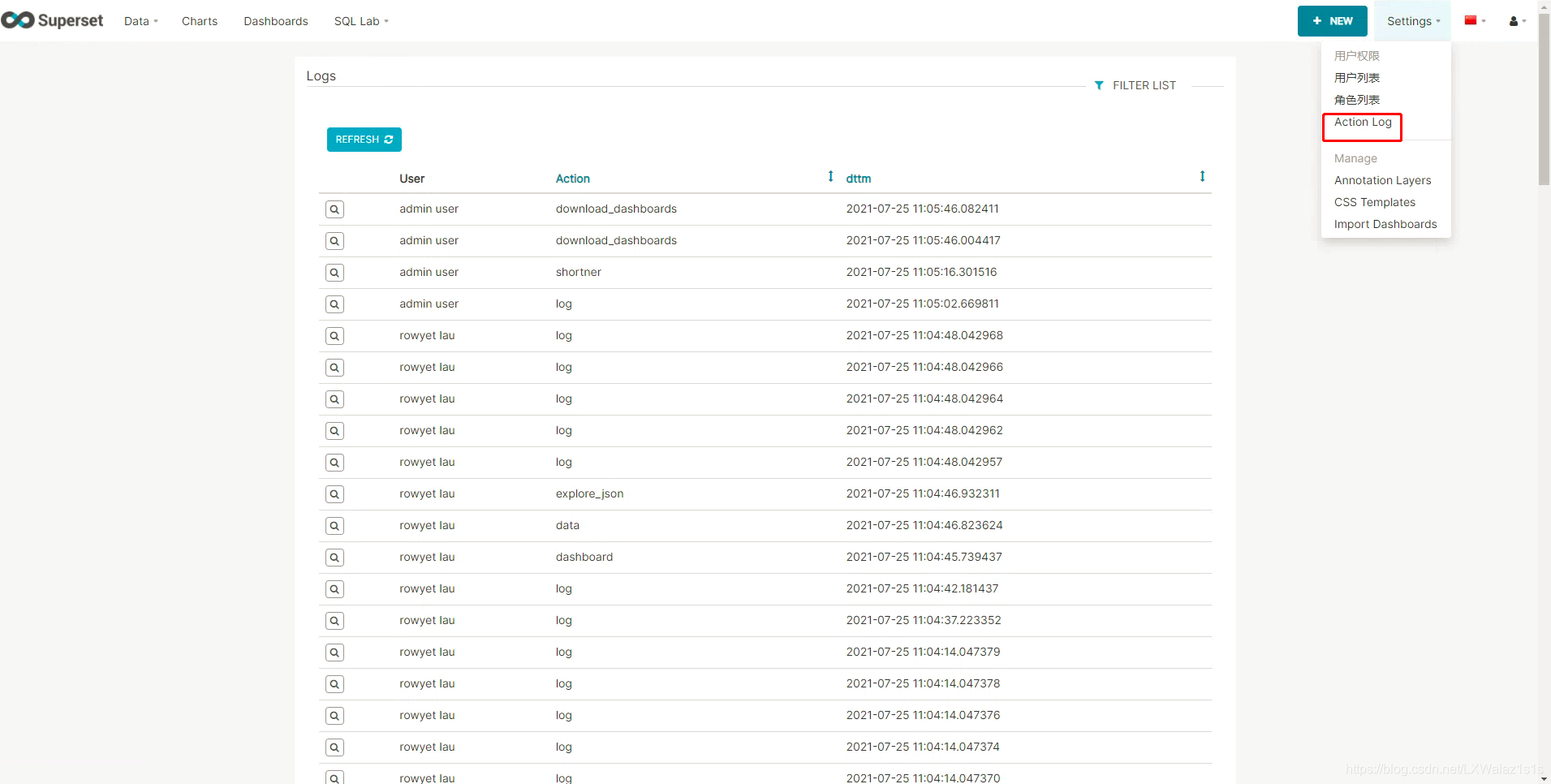
6.3 操作日志
操作日志记录的是在你的Superset平台上不同用户的行为日志,如图6.3.0。
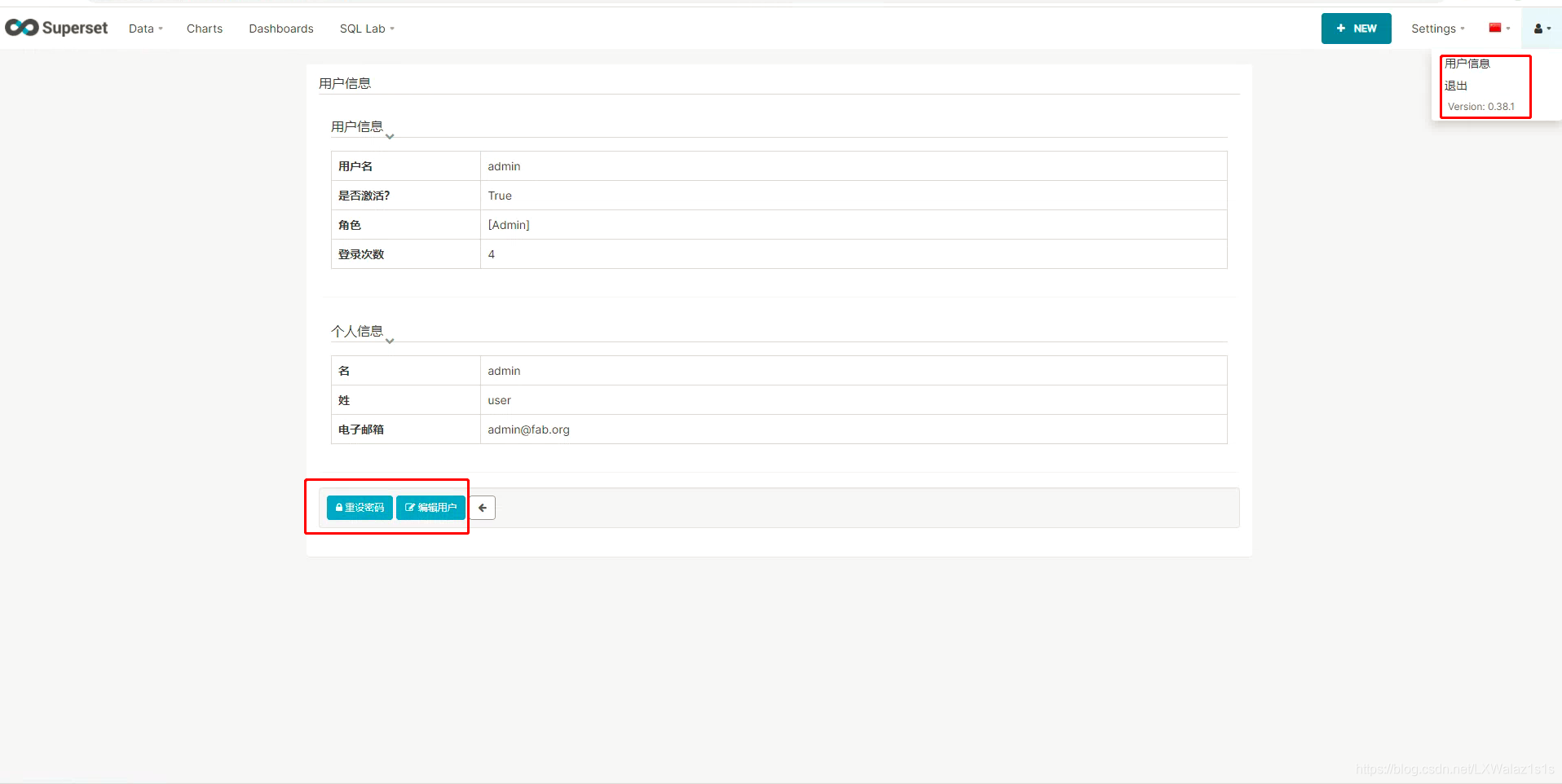
6.4 用户信息、退出、版本信息
菜单栏最右侧的个人信息,主要是包含:
用户信息:修改用户姓名,重置密码;退出:回到登录主界面;版本:目前您安装的Superset版本信息。
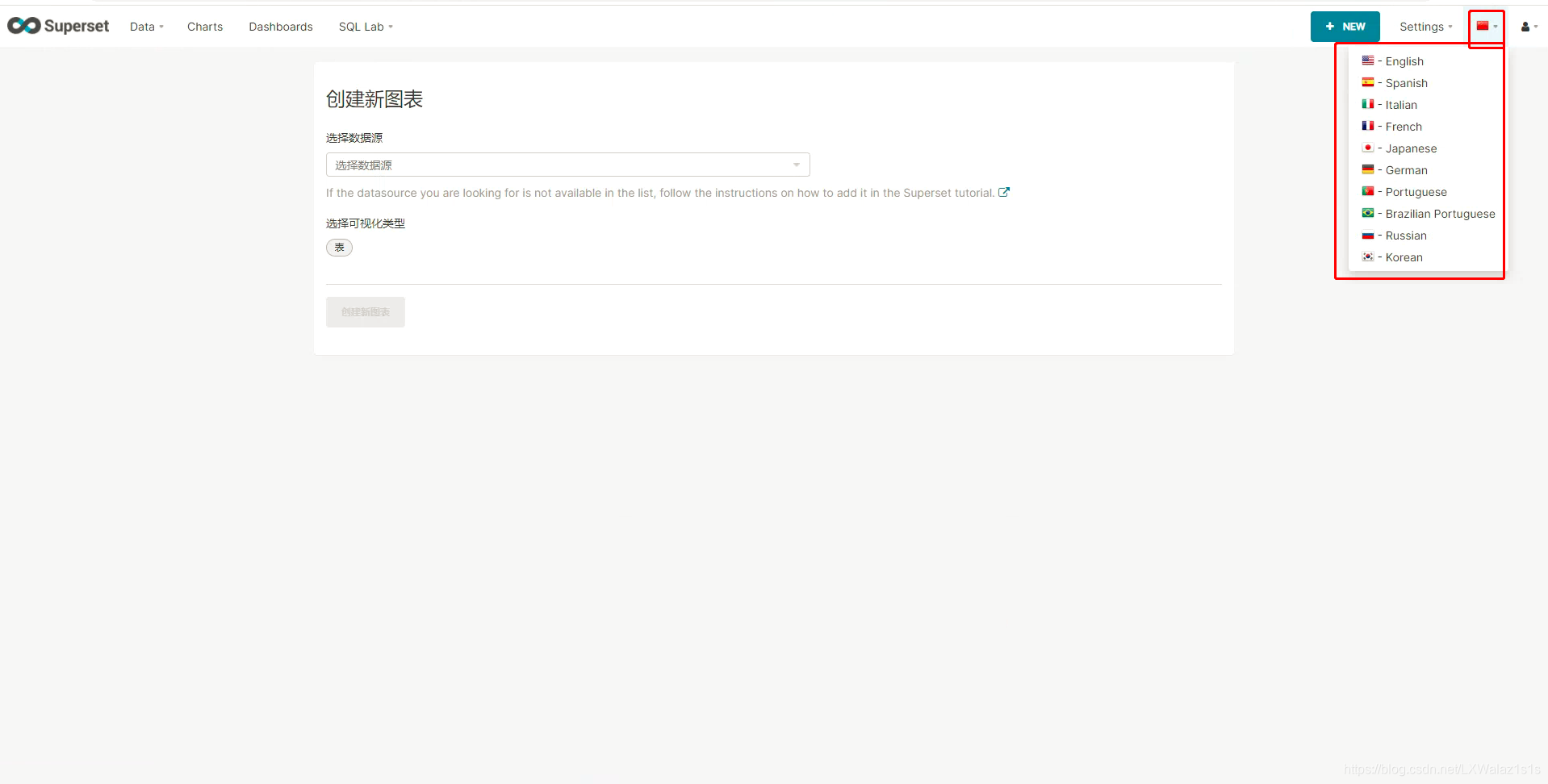
6.5 语言选择
作为Apache的顶级项目,自然是运用于全球的,支持世界上一些通用的语言 ,选择一款你最喜欢的即可。
6.6 管理设置
针对仪表盘,图表渲染加入自己想要的风格和模板,实际运用的用的不多。

6.7 + NEW
菜单栏的+ NEW其实就是给最通用的三个模块SQL Query、图表、看板(仪表盘)的一个快捷方式,此三者的用法就不在累赘了。
+ NEW模块
以上就是关于Apache Superset这款开源的大数据探索分析、可视化报表平台的基本介绍,更多更加刺激的内容可以关注官网及官方文档Apache Superset Documention。




