目录
MySQL执行SQL的整体流程
引言, MySQL索引底层学习原因
磁盘介绍(理解磁盘IO)
索引底层数据结构B+树
B+树(聚集索引)
B+树(辅助索引)
思考一下为何使用B+树结构, 不是B树, 不是平衡树二叉树,红黑树?
索引总结
MySQL执行SQL的整体流程
显示需要跟MYSQL Server 进行连接. 获取MySQL服务. 跟数据库进行交互.
connection Pool 连接池。提前创建多条连接通道. 新的连接请求到来就复用连接通道.
一条连接的建立对应一个线程的创建. 存在多线程并发操作数据库的问题.
--- 引出事务原理. 事务就是专门用来处理。 多连接并发时所产生的问题.
多线程 / 多连接同时对于 数据库进行写操作势必会产生什么? 脏数据
咋处理的, 无非是 MVCC + mutex. 此处如果想要细致了解的, 可以看如下文章.
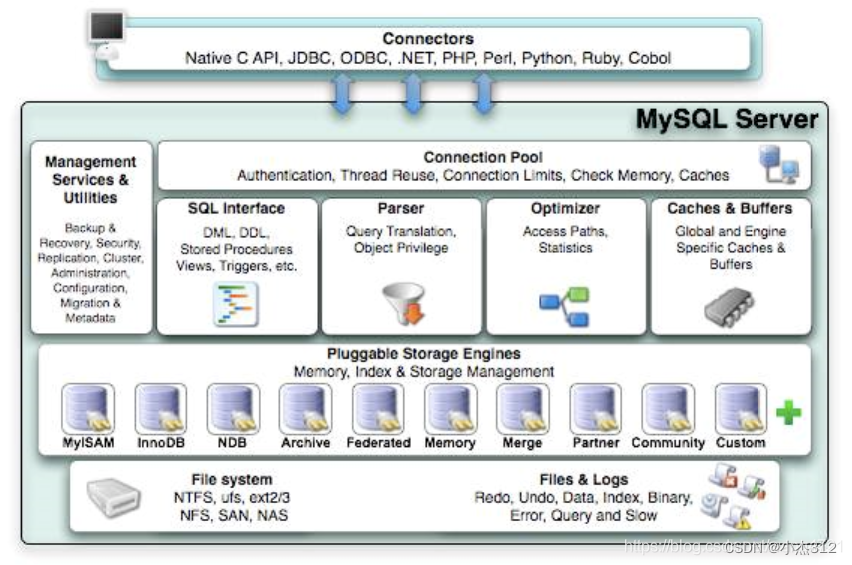
mysql事务的理解学习, 面试不问索引原理就是事务原理_小杰312的博客-CSDN博客mysql事务的理解学习, 面试不问索引原理就是事务原理https://blog.csdn.net/weixin_53695360/article/details/124026899?spm=1001.2014.3001.5502然后连接建立好之后就是对于客户端发过来的SQL语句进行解析优化. 查缓存.
缓存没有,交到存储引擎去查找, 去存储,去修改, 去插入, 去删除 (索引B+树)
很多大公司对于存储引擎的研究,研发岗都是特别重要核心的,所以对存储引擎感兴趣的可以去深究,算是一个很好的方向。大厂对此绝对有需求. 因为他实在太重要了,可以说是MySQL等数据库server的核心所在.
引言, MySQL索引底层学习原因
为何一定要理解索引的底层原理? 我会增删改查这些基本操作不就OK了嘛.
的确,对于以后的工作日常而言,增上改查对于我们普通的开发工程师来说是要不完的。
可是,面试的时候会问。
而且对于我们服务器开发工程师而言,必须理解性能优化上的点点滴滴细节, 一定要从底层数据结构进行理解,因为总有一天我们可能成为更优秀的人, 成为架构师. 而且对于知识的理解点到位可以无形的根深你的记忆.
磁盘介绍(理解磁盘IO)
我们常常在面试的时候回答使用B+树可以减少磁盘IO。索引的加入可以提高查询效率. 可以这些都过于浅显了. 我们甚至连磁盘是什么结构都不知道, 仅仅知道的是磁盘IO效率很低. 时间消耗很长. 远远大于内存IO
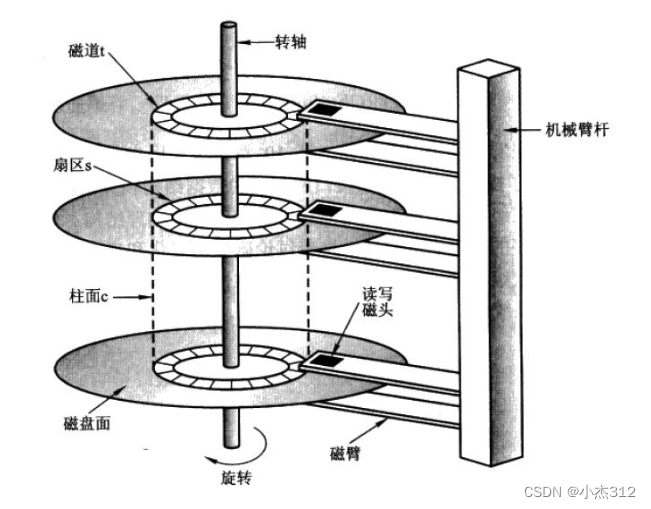
磁盘是由磁盘面, 磁道, 扇区, 读写磁头构成的.
扇区的大小是512个字节. (现在有些改成了4k), 很明显扇区就是用来存储的. 存储着数据库文件.

所以第一个问题来了? 我们查找数据库记录. 进行IO交互是直接按照扇区为单位进行交互吗?
NONONO. 是按照page进行一次IO交互的.
系统读取磁盘,page基本单位是 4KB 。
MySQL 进行IO的基本单位是 16KB 也就是 page = 16KB
为何page是更大了. 为何一次IO操作, IO交互是读取更多的数据到内存更好?
很明显, 一次读取的数据够多,就可以减少读取次数,也就可以减少IO交互次数,也就是读取磁盘的次数.
- MySQL 中的数据文件,是以page为单位保存在磁盘当中的
- MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据。
- 而只要涉及计算,就需要CPU参与,既然有CPU参与,就一定要能够先将数据移动到内存当中。
- 所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
- 为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。和磁盘数据进行IO交互
- 为何更高的效率,一定要尽可能的减少系统和磁盘IO的次数
于是现在出现了第一版最easy数据结构, 管理这些page: 你瞅瞅可以不.
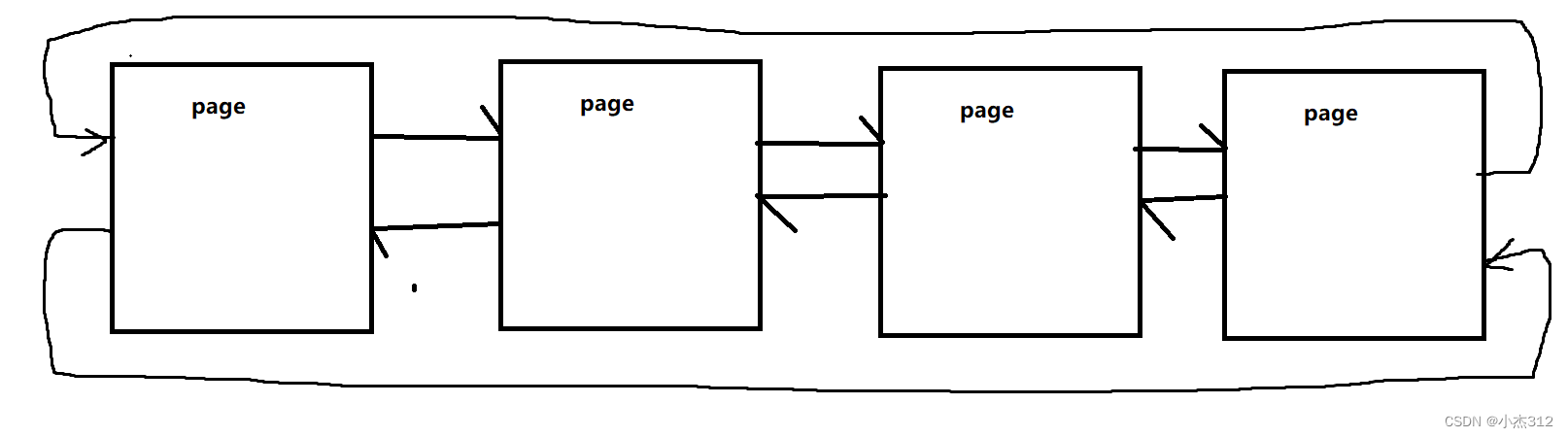
知道是啥了吧。对对对就是它. 双向循环list。如下是更细节的图.
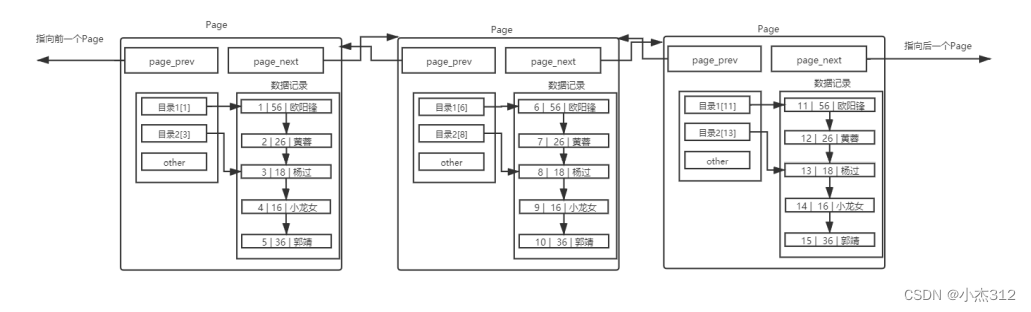
上述这样的存储结构. 是用来存储记录的, 也就是存储数据的,在数据量很少的情况下.这样是没多大问题的
可是数据量达到一定程度的时候. 线性的查找每一页, IO交互的次数也会很多. 效率很低下.
索引底层数据结构B+树
于是乎. 索引B+树这个结构出现了. (为页添加目录的形式. 有点像. 上层页是下层页的目录.)
只有叶子结点会存储真正的记录信息. 上面的页都是存储的索引值 + 索引值对应的页的地址.
B+树的特征. 树宽大,但是高度低。 好处是啥? 查找页数少. 加载磁盘page到内存的磁盘IO次数少. 效率高.
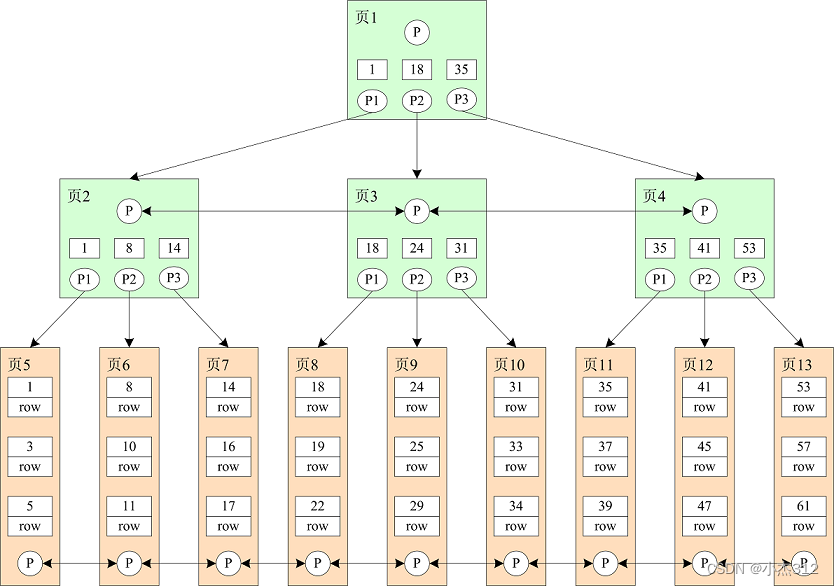
B+树(聚集索引)
- 使用主键为key值构建B+树
- 除了叶子结点, 上面的所有结点都存储的是目录页. 只有叶子结点存储的是数据页.(实实在在的记录,行数据).
- 目录页只放各个下级Page的最小键值, 键值从左到右依次增大
- 最下面一层叶子结点. 采用双向链接. 构成双向循环链表. why?
B+树(辅助索引)
- 辅助索引还是构成的B+树. 但是和上述不同的是. 辅助索引构成B+树的叶子结点中存储的不是行数据. 而是聚簇索引值 (主键值), 然后通过这个主键值到聚簇索引B+树种去查询,操作
- 为什么要这样? 保证数据的一致性, 和保证全局仅存储一份数据.
- 辅助索引也按照B+树结构组织起来, 是为了降低磁盘IO. 但是它的叶子结点中不是行数据,只有对应的主键,再回表到聚簇索引B+树中去查找操作. (回表查询操作)
思考一下为何使用B+树结构, 不是B树, 不是平衡树二叉树,红黑树?
不采用红黑树 + AVL树原因在于树高的问题. 树高越高,进行的IO交互次数, 磁盘IO的次数越多.效率越低.
那为何使用B+树而不使用B树?
因为首先B树对比B+树. B+树是所有的数据全部分布在叶子结点上. 而B树不一样, 它是数据结点分布在整棵树.
所以弊端1出现了. B树的树高会高于B+树
- 非叶子节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
- 叶子节点相连,更便于进行范围查找
索引总结
- 索引对应的底层数据结构是B+树. 数据存储在主键构成的聚簇索引B+树的叶子结点
- 使用索引B+树的优势在于提高查询效率.
- 索引尽量短小. B+树结点可以存储更多的 下层结点, 降低B+树树高.
- 查询频次较高且数据量大的表建立索引;索引选择使用频次较高,过滤效果好的列或者组合
- 尽量扩展索引,在现有索引的基础上,添加复合索引
- 不要 select * ; 尽量只列出需要的列字段
- 索引列,列尽量设置为非空




