参考视频:https://www.youtube.com/watch?v=UkQ2FVpDxHg
文章目录
- 基本概念
- 孪生网络(Siamese Network)
- Pretraining and Fine Tuning
- Few-shot常用数据集
- 参考资料
基本概念
小样本学习(few-shot learning)是什么:就是使用很少的样本来进行分类或回归
Few-shot Learning的目标:让机器学会自己学习
小样本学习的直观理解:
① 前提:首先要知道,训练一个模型的目的不是为了让模型如何分辨大象和蚂蚁,而是让模型具有判断图片“异同”的能力,即让模型看到两张图片后,它能分别出这俩是不是一个类别。这样,当我们在用大数据集训练出一个分类器后,在测试阶段给模型一个从来没见过的类别的图片(假设给了一个水獭图片),此时模型虽然不知道它是什么类别,但是依然能知道它不属于之前的所有类别。这时如果再给一个相同类别的图片(假设又给了一张水獭图片),此时虽然模型从来没见过这种类别的图片(模型从来没见过水獭),但模型依然能知道这俩是一种类别(模型能判断出这两张图片是一种动物)
② 思路:先用大的训练数据集训练出一个具备判断“异同”能力的模型,在测试阶段,再给一个小样本数据集(称为Support Set),里面会包含模型没见过的样本类别,然后让模型判断当前给的图片属于 Support Set 中的哪一个类别。
例如:

上图中,假设目前有一个训练好的图片分类器,但是该模型没见过水獭(otter),此时测试阶段希望模型可以分辨水獭,这样就可以给模型一个support set,让它从这里面选,query的图片是support set中的哪一种
Few-shot learning 是 Meta Learning 的 一种,Meta Leanring 就是去学习如何学习(Learn to learn)
k-way n-shot support Set:Support Set 就是帮助模型去分辨新类别的小样本数据集。 k k k 代表小样本中类别的数量, n n n 代表每个类别有多少数据。例如,有3个类别,每个类别只有一个样本,那么就是 3-way one-shot.
- k-way: k 的数量越多,分类准确率越低
- n-shot: n 的数量越多,分类准确率越高
Few-shot Learning的基本思路(Basic Idea):
学习一个相似度函数(similarity function):
sim
(
x
,
x
′
)
text{sim}(x, x')
sim(x,x′) ,来判别样本
x
x
x 与
x
′
x'
x′ 的相似度,相似度越高,表示这两个样本越可能是同一个类别。例如,可以通过一个很大的数据集学习出一个相似度函数,然后用该函数进行预测。
孪生网络(Siamese Network)
Siamese Network 是一种用于小样本学习的网络
该网络所用训练数据集(Training Data)包含两部分:
- 正样本(Positive Samples ):两个“同类别”的样本构成的样本对 ( x i , x j , 1 ) (x_i, x_j, 1) (xi,xj,1), 其中 1 表示 x i x_i xi 和 x j x_j xj 是同一个类别的样本,例如: ( 老 虎 a , 老 虎 a , 1 ) (老虎a, 老虎a, 1) (老虎a,老虎a,1)
- 负样本(Negative Samples):两个“不同类别”的样本构成的样本对 ( x i , x j , 0 ) (x_i, x_j, 0) (xi,xj,0),其中 0 表示 x i x_i xi 和 x j x_j xj 不是同一个类别的样本,例如 ( 汽 车 a , 大 象 a , 0 ) (汽车a, 大象a, 0) (汽车a,大象a,0)
Siamese Network的网络结构:
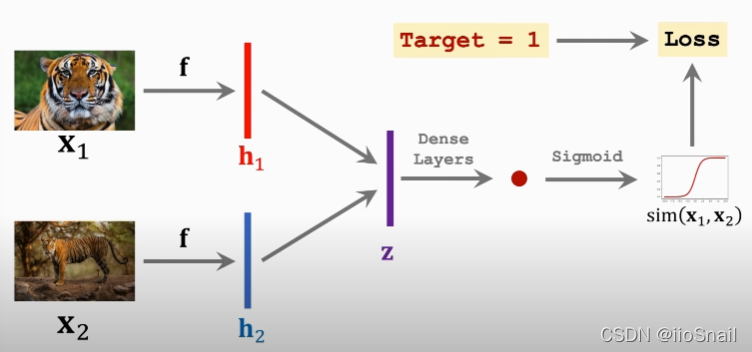
- 模型 f f f :可以是CNN卷积神经网络;注意:上下两个 f f f 是同一个网络
- 向量 h 1 , h 2 h_1, h_2 h1,h2:网络 f f f 的输出向量
- 向量 z z z:对 h 1 h_1 h1 和 h 2 h_2 h2 进行处理,例如,令 z = ∣ h 1 − h 2 ∣ z=|h_1-h_2| z=∣h1−h2∣
- Dense Layers:全连接层
 :全连接层输出的数值(scalar)
:全连接层输出的数值(scalar)
该网络前向传播的过程:
- 将两张图片 x 1 x_1 x1 和 x 2 x_2 x2 分别送给同一个卷积神经网络 f f f ,得到输出向量 h 1 h_1 h1 和 h 2 h_2 h2
- 对 h 1 h_1 h1 和 h 2 h_2 h2 求差的绝对值,得到向量 z z z
- 将向量 z z z 送给全连接网络,得到一个scalar
- 将scalar送给Sigmoid的到最终的输出,最终的输出就是这两张图片的相似度。
对于负样本(Negative Sample)同理。
进阶架构:Triplet Loss
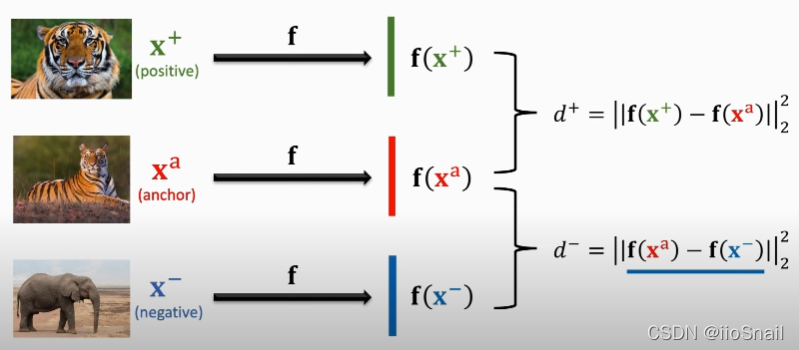
- 从训练集中选取一个样本作为锚点(anchor) x a x^a xa,然后根据锚点,选择一个正样本 x + x^+ x+ 和一个负样本 x − x^- x−。
- 然后将三个样本送到“同一个”卷积神经网络 f f f 中,并计算正样本与锚点之间的距离 d + d^+ d+ 和 负样本与锚点之间的距离 d − d^- d− 。其中 d + = ∥ f ( x + ) − f ( x a ) ∥ 2 2 d^{+}=left|mathbf{f}left(mathbf{x}^{+}right)-mathbf{f}left(mathbf{x}^{mathrm{a}}right)right|_{2}^{2} d+=∥f(x+)−f(xa)∥22 , d − = ∣ ∣ f ( x a ) − f ( x − ) ∣ ∣ 2 2 d^{-}=|| mathbf{f}left(mathrm{x}^{mathrm{a}}right)-mathbf{f}left(mathrm{x}^{-}right)||_{2}^{2} d−=∣∣f(xa)−f(x−)∣∣22。 其中 ∣ 2 2 |_2^2 ∣22 是二范数的平方。
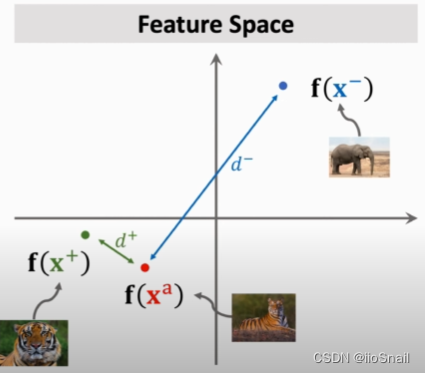
- 显然,我们希望
d
+
d^+
d+ 越小越好,
d
−
d^-
d− 越大越好。用图表示则为:
- 对于损失函数,定义为 L o s s ( x a , x + , x − ) = m a x { 0 , d + + α − d − } Loss(x^a, x^+, x^-)= max{0, d^+ +alpha -d^-} Loss(xa,x+,x−)=max{0,d++α−d−} 其中 α alpha α 为大于0的超参数,含义为:①如果负样本到锚点的距离比正样本到锚点的距离大 α alpha α,我们就认为分对了,损失函数为0; ②否则,就将 d + + α − d − d^+ + alpha - d^- d++α−d− 作为损失函数
Pretraining and Fine Tuning
另一种熊Few-shot Learning的思路:使用别人预训练好的模型来进行Few-shot Learning。
CNN的预训练模型:用别人训练好的CNN模型,把最后的全连接层砍掉即可。保留下来的卷积层的作用是提取图像的特征,相当于对图像进行了编码(embedding)操作。
具体做法:
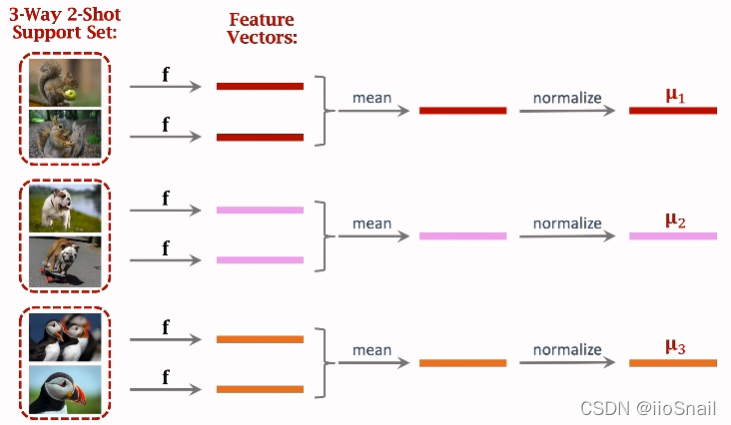
- 用预训练模型 f f f 对所有的小样本进行特征提取,得到它们的特征向量(feature Vectors)
- 将同类别的Feature Vectors进行合并(上图使用的求平均),然后再进行正则化(normalize),最终的得到每个类别的向量 u i u_i ui
- 此时准备工作已经完毕,接下来可以开始做预测了
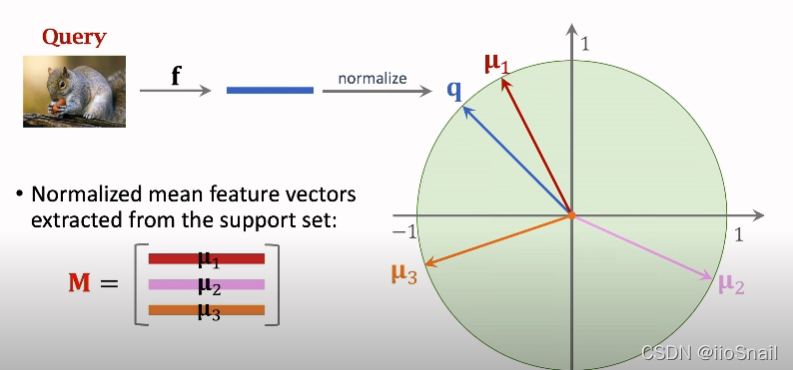
- 将要预测(query)的图片按照步骤1,2的方式得到向量 q q q
- 然后比较向量 q q q 和类别向量 u i u_i ui,距离谁最近,那么该图片就是什么类别
计算过程的数学公式为:
p = Softmax ( M q ) = Softmax ( [ u 1 T q u 2 T q u 3 T q ] ) textbf{p} = text{Softmax}(Mq) = text{Softmax}( begin{bmatrix} u^T_1q \ u^T_2q\ u^T_3q\ end{bmatrix}) p=Softmax(Mq)=Softmax(⎣⎡




