
文章目录
- 缓存
- 抽奖
- Redis-cli 操作
- SpringBoot 实现
- Set实现点赞/收藏功能
- Redis-cli API操作
- SpringBoot 操作
- 排行榜
- Redis-cli操作
- SpringBoot操作
- PV统计(incr自增计数)
- Redis-cli 操作
- UV统计(HeyperLogLog)
- Redis-cli 操作
- SpringBoot操作HeyperLogLog
- 去重(BloomFiler)
- BloomFiler 安装
- Redis-cli操作
- SpringBoot整合
- 用户签到(BitMap)
- Redis-cli 操作:
- 是否签到、连续签到判断
- SpringBoot实现签到
- 按月签到
- 指定时间签到
- GEO搜附近
- GEO API 及Redis-cli 操作:
- SpringBoot 操作
- 简单限流
- Redis-cli操作
- SpringBoot示例:
- 全局ID
- Redis-cli 客户端测试
- 简单分布式锁
- 认识的人/好友推荐
- Redis-cli 客户端测试
- 发布/订阅
- Redis-cli操作
- 消息队列
- 数据共享(session共享)
- 商品筛选
- Redis-cli 客户端测试
- 购物车
- Redis-cli 客户端测试
- 定时取消订单(key过期监听)
- 物流信息(时间线)
大家好,我是一航
后端程序员,不管是出去面试,还是当面试官,Redis几乎是100%会问到的技术点;究其原因,主要是因为他实在过于强大、使用率太高了;导致项目中几乎无处不在。
那Redis部分,不出意外,第一个问题就是:你做的项目,用Redis干了些啥?大部分人的回答都会是:缓存;当问到是否还有其他场景中使用时,部分用的少的朋友就会微微摇头;
其实也没错,Redis绝不部分使用场景就是用来做缓存;但是,由于Redis 支持比较丰富的数据结构,因此他能实现的功能并不仅限于缓存,而是可以运用到各种业务场景中,开发出既简洁、又高效的系统;
下面整理了20种 Redis 的妙用场景,每个方案都用一个实际的业务需求并结合数据结构的API来讲解,希望大家能够理解其底层的实现方式,学会举一反三,并运用到项目的方方面面:
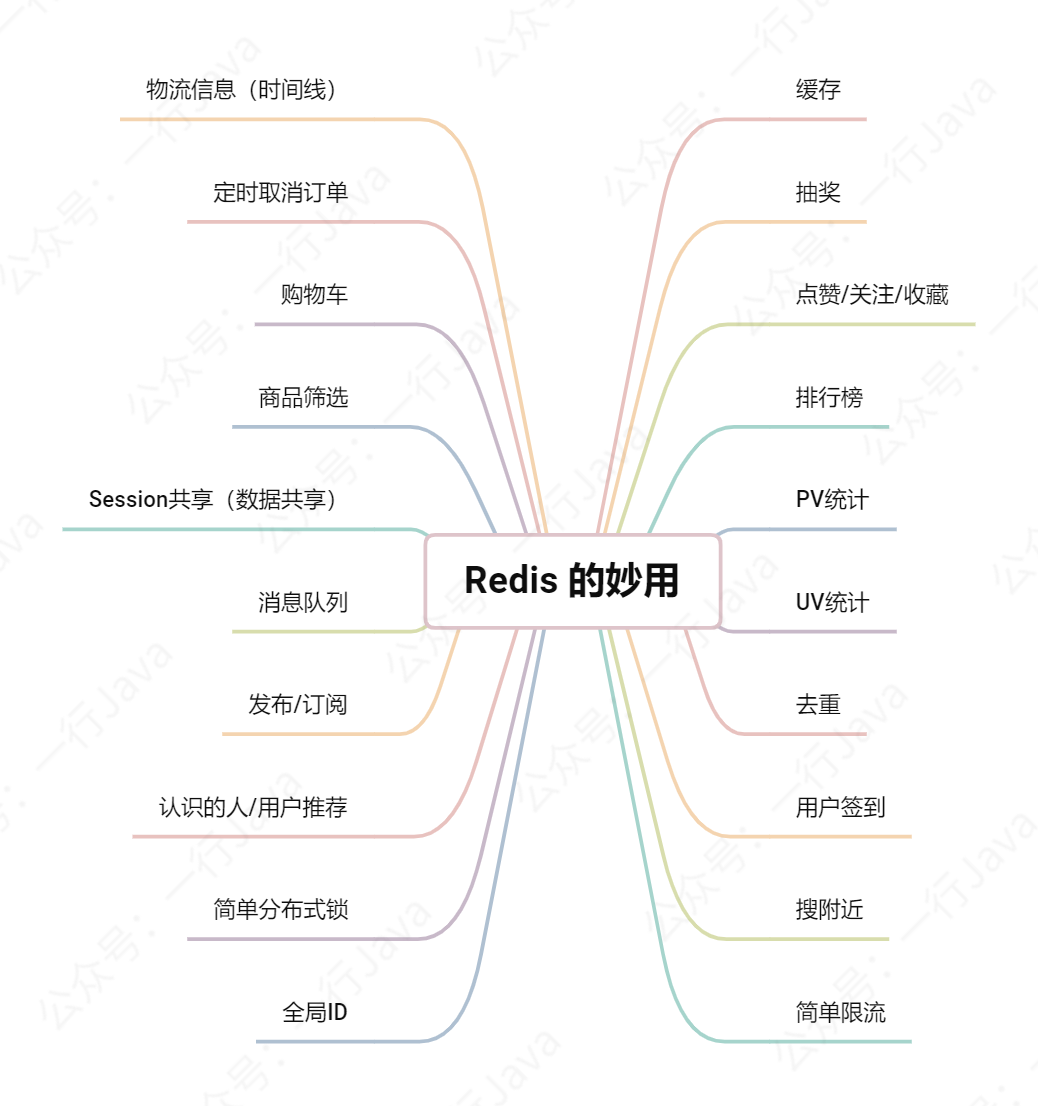
本文稍微有点点长,如果时间不够,建议看一下目录,收藏起来,用的时候再翻出来看看。
测试源码:https://github.com/vehang/ehang-spring-boot/tree/main/spring-boot-011-redis
缓存
本文假定你已经了解过Redis,并知晓Redis最基础的一些使用,如果你对Redis的基础API还不了解,可以先看一下菜鸟教程:https://www.runoob.com/redis,那么缓存部分及基础API的演示,就不过多来讲解了;
但是,基本的数据结构,在这里再列举一下,方便后续方案的理解:
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有:看是否存在、添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有:添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有:添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
-
依赖
以下所有通过SpringBoot测试的用例,都需要引入 Redis 的依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
抽奖
曾几何时,抽奖是互联网APP热衷的一种推广、拉新的方式,节假日没有好的策划,那就抽个奖吧!一堆用户参与进来,然后随机抽取几个幸运用户给予实物/虚拟的奖品;此时,开发人员就需要写上一个抽奖的算法,来实现幸运用户的抽取;其实我们完全可以利用Redis的集合(Set),就能轻松实现抽奖的功能;
功能实现需要的API
- SADD key member1 [member2]:添加一个或者多个参与用户;
- SRANDMEMBER KEY [count]:随机返回一个或者多个用户;
- SPOP key:随机返回一个或者多个用户,并删除返回的用户;
SRANDMEMBER 和 SPOP 主要用于两种不同的抽奖模式,SRANDMEMBER 适用于一个用户可中奖多次的场景(就是中奖之后,不从用户池中移除,继续参与其他奖项的抽取);而 SPOP 就适用于仅能中一次的场景(一旦中奖,就将用户从用户池中移除,后续的抽奖,就不可能再抽到该用户); 通常 SPOP 会用的会比较多。
Redis-cli 操作
127.0.0.1:6379> SADD raffle user1
(integer) 1
127.0.0.1:6379> SADD raffle user2 user3 user4 user5 user6 user7 user8 user9 user10
(integer) 9
127.0.0.1:6379> SRANDMEMBER raffle 2
1) "user5"
2) "user2"
127.0.0.1:6379> SPOP raffle 2
1) "user3"
2) "user4"
127.0.0.1:6379> SPOP raffle 2
1) "user10"
2) "user9"
SpringBoot 实现
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.List;
/**
* @author 一行Java
* @title: RaffleMain
* @projectName ehang-spring-boot
* @description: TODO
* @date 2022/7/18 15:17
*/
@Slf4j
@SpringBootTest
public class RaffleMain {
private final String KEY_RAFFLE_PROFIX = "raffle:";
@Autowired
RedisTemplate redisTemplate;
@Test
void test() {
Integer raffleId = 1;
join(raffleId, 1000, 1001, 2233, 7890, 44556, 74512);
List lucky = lucky(raffleId, 2);
log.info("活动:{} 的幸运中奖用户是:{}", raffleId, lucky);
}
public void join(Integer raffleId, Integer... userIds) {
String key = KEY_RAFFLE_PROFIX + raffleId;
redisTemplate.opsForSet().add(key, userIds);
}
public List lucky(Integer raffleId, long num) {
String key = KEY_RAFFLE_PROFIX + raffleId;
// 随机抽取 抽完之后将用户移除奖池
List list = redisTemplate.opsForSet().pop(key, num);
// 随机抽取 抽完之后用户保留在池子里
//List list = redisTemplate.opsForSet().randomMembers(key, num);
return list;
}
}
Set实现点赞/收藏功能
有互动属性APP一般都会有点赞/收藏/喜欢等功能,来提升用户之间的互动。
传统的实现:用户点赞之后,在数据库中记录一条数据,同时一般都会在主题库中记录一个点赞/收藏汇总数,来方便显示;
Redis方案:基于Redis的集合(Set),记录每个帖子/文章对应的收藏、点赞的用户数据,同时set还提供了检查集合中是否存在指定用户,用户快速判断用户是否已经点赞过
功能实现需要的API
- SADD key member1 [member2]:添加一个或者多个成员(点赞)
- SCARD key:获取所有成员的数量(点赞数量)
- SISMEMBER key member:判断成员是否存在(是否点赞)
- SREM key member1 [member2] :移除一个或者多个成员(点赞数量)
Redis-cli API操作
127.0.0.1:6379> sadd like:article:1 user1
(integer) 1
127.0.0.1:6379> sadd like:article:1 user2
(integer) 1
# 获取成员数量(点赞数量)
127.0.0.1:6379> SCARD like:article:1
(integer) 2
# 判断成员是否存在(是否点在)
127.0.0.1:6379> SISMEMBER like:article:1 user1
(integer) 1
127.0.0.1:6379> SISMEMBER like:article:1 user3
(integer) 0
# 移除一个或者多个成员(取消点赞)
127.0.0.1:6379> SREM like:article:1 user1
(integer) 1
127.0.0.1:6379> SCARD like:article:1
(integer) 1
SpringBoot 操作
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
/**
* @author 一行Java
* @title: LikeMain
* @projectName ehang-spring-boot
* @description: TODO
* @date 2022/7/18 15:38
*/
@Slf4j
@SpringBootTest
public class LikeMain {
private final String KEY_LIKE_ARTICLE_PROFIX = "like:article:";
@Autowired
RedisTemplate redisTemplate;
@Test
void test() {
long articleId = 100;
Long likeNum = like(articleId, 1001, 1002, 2001, 3005, 4003);
unLike(articleId, 2001);
likeNum = likeNum(articleId);
boolean b2001 = isLike(articleId, 2001);
boolean b3005 = isLike(articleId, 3005);
log.info("文章:{} 点赞数量:{} 用户2001的点赞状态:{} 用户3005的点赞状态:{}", articleId, likeNum, b2001, b3005);
}
/**
* 点赞
*
* @param articleId 文章ID
* @return 点赞数量
*/
public Long like(Long articleId, Integer... userIds) {
String key = KEY_LIKE_ARTICLE_PROFIX + articleId;
Long add = redisTemplate.opsForSet().add(key, userIds);
return add;
}
public Long unLike(Long articleId, Integer... userIds) {
String key = KEY_LIKE_ARTICLE_PROFIX + articleId;
Long remove = redisTemplate.opsForSet().remove(key, userIds);
return remove;
}
public Long likeNum(Long articleId) {
String key = KEY_LIKE_ARTICLE_PROFIX + articleId;
Long size = redisTemplate.opsForSet().size(key);
return size;
}
public Boolean isLike(Long articleId, Integer userId) {
String key = KEY_LIKE_ARTICLE_PROFIX + articleId;
return redisTemplate.opsForSet().isMember(key, userId);
}
}
排行榜
排名、排行榜、热搜榜是很多APP、游戏都有的功能,常用于用户活动推广、竞技排名、热门信息展示等功能;

比如上面的热搜榜,热度数据来源于全网用户的贡献,但用户只关心热度最高的前50条。
常规的做法:就是将用户的名次、分数等用于排名的数据更新到数据库,然后查询的时候通过Order by + limit 取出前50名显示,如果是参与用户不多,更新不频繁的数据,采用数据库的方式也没有啥问题,但是一旦出现爆炸性热点资讯(比如:大陆收复湾湾,xxx某些绿了等等),短时间会出现爆炸式的流量,瞬间的压力可能让数据库扛不住;
Redis方案:将热点资讯全页缓存,采用Redis的有序队列(Sorted Set)来缓存热度(SCORES),即可瞬间缓解数据库的压力,同时轻松筛选出热度最高的50条;
功能实现需要的命令
- ZADD key score1 member1 [score2 member2]:添加并设置SCORES,支持一次性添加多个;
- ZREVRANGE key start stop [WITHSCORES] :根据SCORES降序排列;
- ZRANGE key start stop [WITHSCORES] :根据SCORES降序排列;
Redis-cli操作
# 单个插入
127.0.0.1:6379> ZADD ranking 1 user1
(integer) 1
# 批量插入
127.0.0.1:6379> ZADD ranking 10 user2 50 user3 3 user4 25 user5
(integer) 4
# 降序排列 不带SCORES
127.0.0.1:6379> ZREVRANGE ranking 0 -1
1) "user3"
2) "user5"
3) "user2"
4) "user4"
5) "user1"
# 降序排列 带SCORES
127.0.0.1:6379> ZREVRANGE ranking 0 -1 WITHSCORES
1) "user3"
2) "50"
3) "user5"
4) "25"
5) "user2"
6) "10"
7) "user4"
8) "3"
9) "user1"
10) "1"
# 升序
127.0.0.1:6379> ZRANGE ranking 0 -1 WITHSCORES
1) "user1"
2) "1"
3) "user4"
4) "3"
5) "user2"
6) "10"
7) "user5"
8) "25"
9) "user3"
10) "50"
SpringBoot操作
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.DefaultTypedTuple;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.Set;
/**
* @author 一行Java
* @title: RankingTest
* @projectName ehang-spring-boot
* @description: TODO
* @date 2022/7/18 15:54
*/
@SpringBootTest
@Slf4j
public class RankingTest {
private final String KEY_RANKING = "ranking";
@Autowired
RedisTemplate redisTemplate;
@Test
void test() {
add(1001, (double) 60);
add(1002, (double) 80);
add(1003, (double) 100);
add(1004, (double) 90);
add(1005, (double) 70);
// 取所有
Set<DefaultTypedTuple> range = range(0, -1);
log.info("所有用户排序:{}", range);
// 前三名
range = range(0, 2);
log.info("前三名排序:{}", range);
}
public Boolean add(Integer userId, Double score) {
Boolean add = redisTemplate.opsForZSet().add(KEY_RANKING, userId, score);
return add;
}
public Set<DefaultTypedTuple> range(long min, long max) {
// 降序
Set<DefaultTypedTuple> set = redisTemplate.opsForZSet().reverseRangeWithScores(KEY_RANKING, min, max);
// 升序
//Set set = redisTemplate.opsForZSet().rangeWithScores(KEY_RANKING, min, max);
return set;
}
}
输出
所有用户排序:[DefaultTypedTuple [score=100.0, value=1003], DefaultTypedTuple [score=90.0, value=1004], DefaultTypedTuple [score=80.0, value=1002], DefaultTypedTuple [score=70.0, value=1005], DefaultTypedTuple [score=60.0, value=1001]]
前三名排序:[DefaultTypedTuple [score=100.0, value=1003], DefaultTypedTuple [score=90.0, value=1004], DefaultTypedTuple [score=80.0, value=1002]]
PV统计(incr自增计数)
Page View(PV)指的是页面浏览量,是用来衡量流量的一个重要标准,也是数据分析很重要的一个依据;通常统计规则是页面被展示一次,就加一
功能所需命令
- INCR:将 key 中储存的数字值增一
Redis-cli 操作
127.0.0.1:6379> INCR pv:article:1
(integer) 1
127.0.0.1:6379> INCR pv:article:1
(integer) 2
UV统计(HeyperLogLog)
前面,介绍了通过(INCR)方式来实现页面的PV;除了PV之外,UV(独立访客)也是一个很重要的统计数据;
但是如果要想通过计数(INCR)的方式来实现UV计数,就非常的麻烦,增加之前,需要判断这个用户是否访问过;那判断依据就需要额外的方式再进行记录。
你可能会说,不是还有Set嘛!一个页面弄个集合,来一个用户塞(SADD)一个用户进去,要统计UV的时候,再通过SCARD汇总一下数量,就能轻松搞定了;此方案确实能实现UV的统计效果,但是忽略了成本;如果是普通页面,几百、几千的访问,可能造成的影响微乎其微,如果一旦遇到爆款页面,动辄上千万、上亿用户访问时,就一个页面UV将会带来非常大的内存开销,对于如此珍贵的内存来说,这显然是不划算的。
此时,HeyperLogLog数据结构,就能完美的解决这一问题,它提供了一种不精准的去重计数方案,注意!这里强调一下,是不精准的,会存在误差,不过误差也不会很大,标准的误差率是0.81%,这个误差率对于统计UV计数,是能够容忍的;所以,不要将这个数据结构拿去做精准的去重计数。
另外,HeyperLogLog 是会占用12KB的存储空间,虽然说,Redis 对 HeyperLogLog 进行了优化,在存储数据比较少的时候,采用了稀疏矩阵存储,只有在数据量变大,稀疏矩阵空间占用超过阈值时,才会转为空间为12KB的稠密矩阵;相比于成千、上亿的数据量,这小小的12KB,简直是太划算了;但是还是建议,不要将其用于数据量少,且频繁创建 HeyperLogLog 的场景,避免使用不当,造成资源消耗没减反增的不良效果。
功能所需命令:
- PFADD key element [element …]:增加计数(统计UV)
- PFCOUNT key [key …]:获取计数(货物UV)
- PFMERGE destkey sourcekey [sourcekey …]:将多个 HyperLogLog 合并为一个 HyperLogLog(多个合起来统计)
Redis-cli 操作
# 添加三个用户的访问
127.0.0.1:6379> PFADD uv:page:1 user1 user2 user3
(integer) 1
# 获取UV数量
127.0.0.1:6379> PFCOUNT uv:page:1
(integer) 3
# 再添加三个用户的访问 user3是重复用户
127.0.0.1:6379> PFADD uv:page:1 user3 user4 user5
(integer) 1
# 获取UV数量 user3是重复用户 所以这里返回的是5
127.0.0.1:6379> PFCOUNT uv:page:1
(integer) 5
SpringBoot操作HeyperLogLog
模拟测试10000个用户访问id为2的页面
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
/**
* @author 一行Java
* @title: HeyperLogLog 统计UV
* @projectName ehang-spring-boot
* @description: TODO
* @date 2022/7/19 16:13
*/
@SpringBootTest
@Slf4j
public class UVTest {
private final String KEY_UV_PAGE_PROFIX = "uv:page:";
@Autowired
RedisTemplate redisTemplate;
@Test
public void uvTest() {
Integer pageId = 2;
for (int i = 0; i < 10000; i++) {
uv(pageId, i);
}
for (int i = 0; i < 10000; i++) {
uv(pageId, i);
}
Long uv = getUv(pageId);
log.info("pageId:{} uv:{}", pageId, uv);
}
/**
* 用户访问页面
* @param pageId
* @param userId
* @return
*/
private Long uv(Integer pageId, Integer userId) {
String key = KEY_UV_PAGE_PROFIX + pageId;
return redisTemplate.opsForHyperLogLog().add(key, userId);
}
/**
* 统计页面的UV
* @param pageId
* @return
*/
private Long getUv(Integer pageId) {
String key = KEY_UV_PAGE_PROFIX + pageId;
return redisTemplate.opsForHyperLogLog().size(key);
}
}
日志输出
pageId:2 uv:10023
由于存在误差,这里访问的实际访问的数量是1万,统计出来的多了23个,在标准的误差(0.81%)范围内,加上UV数据不是必须要求准确,因此这个误差是可以接受的。
去重(BloomFiler)
通过上面HeyperLogLog的学习,我们掌握了一种不精准的去重计数




