目录
🏀1. 初识make/makefile
🥏1.1 背景
🏀2. Linux项目自动化构建工具-make/makefile
🥏2.1 普通方法编译
🥏2.2 利用make和makefile编译
🥏2.3 升级版编译
🥏2.4 函数版编译
🏀3. 第一个Linux程序---进度条
🥏3.1 缓冲区
🥏3.2 n和r的区别
🥏3.3 倒时游戏
🥏3.4 进度条的编写
🥅3.4.1 程序的编写
🥅3.4.2 脚本的编写
🥅3.4.3 运行结果的动图展示
🏀4. gdb工具的简单使用
🥅如何在Linux让程序可调式
🥅gdb的调试
🏀1. 初识make/makefile
❤️首先先区分一下make和makefile;make是一条命令,makefile是一个文件!
🥏1.1 背景
❤️会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
❤️一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译?哪些文件需要后编译?哪些文件需要重新编译?甚至于进行更复杂的功能操作。
❤️makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
❤️make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
❤️make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
🏀2. Linux项目自动化构建工具-make/makefile
❤️make和makefile到底有什么用呢?我们又怎么使用呢?
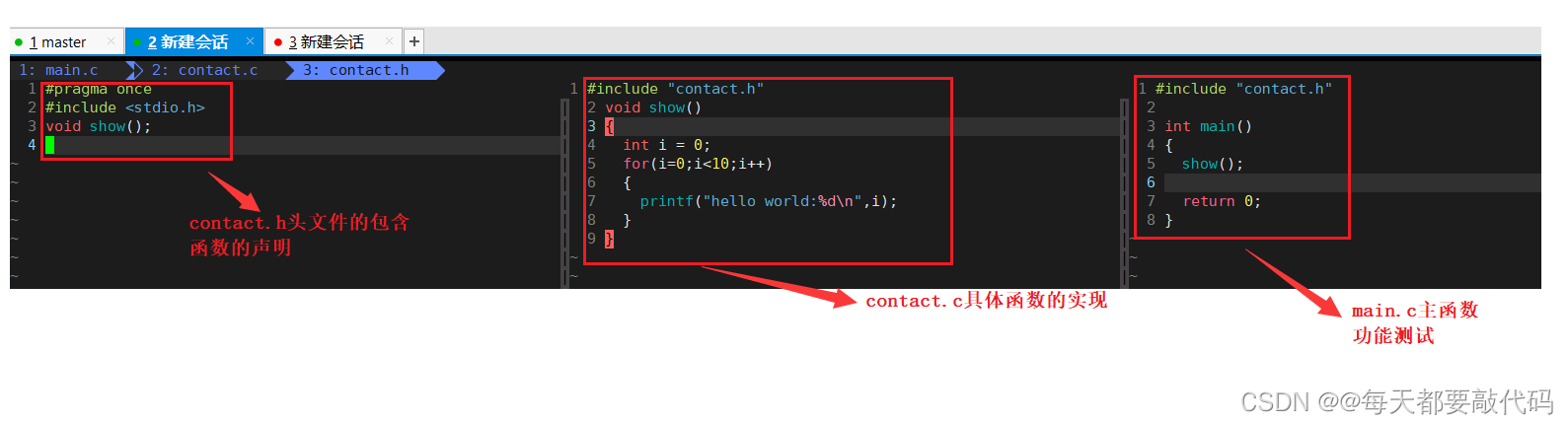
❤️我们不妨写一个小代码,就简单打印10遍hello world吧!我们把这个程序的实现写成项目的模式:contact.h表示头文件的包含,函数的声明等、contact.c具体函数的实现、main.c主函数和测试功能:
❤️这里又两个.c文件,我们要将这两个.c文件合成一个可执行文件,怎么办呢?两种方法!
🥏2.1 普通方法编译
❤️直接编译
⭐️这里直接用了.c文件是不合理的,最好是先转换成.o文件,然后利用.o文件一起编译生成mybin可执行文件!这里前面gcc编译器已经讲解,不在多说!

🥏2.2 利用make和makefile编译
❤️makefile两个核心构成:1.依赖关系 2.依赖方法 ;通常情况下缺一不可!
❤️在当前目录再创建一个makefile/Makefile(都可以)文件;然后在makefile里面写如下脚本,直接make就能运行:
❤️脚本:
mybin:main.c contact.c 2 gcc main.c contact.c -o mybin 3 4 .PHONY:clean 5 clean: 6 rm -rf mybin
❤️脚本详解

❤️实操理解:
❤️脚本写好后,我们就用make和makefile共同来进行编译:
⭐️输入make我们调用makefile里面的脚本,直接就会生成mybin可执行文件;
⭐️输入make clean就会删除可执行文件mybin

🥏2.3 升级版编译
❤️对于上面我们虽然用的是make和makefile进行编译,但是还是直接调用的test.c直接生成mybin;但是我们在gcc编译器已经声明,最好使用.o目标文件去生成mybin;那么怎么实现呢?我们还是先给出脚本!
❤️脚本:
mybin:main.o contact.o 2 gcc $^ -o $@ 3 4 %.o:%.c 5 gcc -c $< 6 7 .PHONY:clean 8 clean: 9 rm -rf *.o mybin
❤️脚本详解:
❤️这个脚本就没有上面那个好理解了,但是这样写的效果无疑是最好的,特别是.c文件越多越好;这里%.o代表任意文件,*.o代表所有文件;
⭐️(1) mybin:main.o contact.o;对于依赖关系不再是mybin依赖.c文件了;而是依赖.o文 件,main.o和contact.o文件
⭐️(2) gcc $^ -o $@;$^表示依赖文件列表(.o文件),$@表示目标文件(mybin);
⭐️(3)%o.%c;%c表示当前目录下的所有的.c文件;%.o表示对应的.c文件形成.o
⭐️(4)gcc -c $<;$<表示把所有的.c文件一个个拿出来,用gcc进行编译生成同名的.o文件
⭐️(5)最后删除基本一样的,区别就是多删除生成.o文件;*.o就表示以.o结尾的所有文件;
🥏2.4 函数版编译
❤️这里相信大家也发现了,2.3版本的编译虽然好,还是有很大问题;对于一个大工程,如果有很多.c文件,我们需要把所有对应的.o文件都要写出来吗?当然不是,这里就给大家一个函数的版本,可以了解一下!
❤️脚本:
CC=gcc -g ELF=mybin src = $(wildcard *.c) object = $(src:%.c=%.o) $(ELF):$(object) @$(CC) $^ -o $@ $(object): .PHONY:clean clean: @rm -rf $(object) $(ELF)
❤️这里先给大家介绍三个函数:wildcard函数、patsubst函数、notdir函数!
⭐️wildcard函数:当前目录下匹配模式的文件,例如:src=$(wildcard *.c),找到所有的.c文 件,类似于find *.c;也可以写成src=$(shell find ‘*.c’),找到所有的.c文件。
⭐️patsubst函数:$(patsubst%.c,%.o,$src),这个不理解比较难记;可以写成下面这种方式:object=$(src:.c=.o),作用是把所有的.c文件转换成.o文件。
⭐️notdir函数:如果是多级目录呢?那就需要加上$(notdir $src),作用是去除目录的限制;不懂的同学也可以用:$(shell find -name '*.c');这句话就可以代替1,3的功能。
❤️脚本详解:
⭐️这里我没有写太复杂,只用了wildcard函数;感兴趣的小伙伴可以自己学习一下上述的三个函数,尝试一下全用函数实现!

🏀3. 第一个Linux程序---进度条
在写进度条之前我们先理解两个知识点!
1.缓冲区;
2. n换行和r回车;
🥏3.1 缓冲区
我们就拿一段代码来提出问题:
❤️sleep(3)表示睡眠 3秒,需要的头文件是,想要深度了解的不妨去man 3 sleep查看详情;
⭐️我们常见的就是后者带n;它是先打印在睡眠3秒;然后结束程序;
⭐️对于前者不带n是先睡眠3秒,然后直接打印结束;为什么呢?这就涉及到缓冲区的概念了!那么怎么不带n也能带到带n的效果呢?利用fflush刷新一下缓冲区!
⭐️缓冲区就是一块内存区域;刷新策略主要有三种:
a.无缓冲(立即)
b.行缓冲(n)
c.全缓冲(缓冲区满了才缓冲)
⭐️程序退出,也会自动刷新!
❤️我们的进度条肯定是在同一行打印的,肯定不能用n进行换行;那么我们怎么让不带n达到带n的效果?这就需要fflush刷新缓冲区;fflush(stdout);刷新到显示器!

🥏3.2 n和r的区别
❤️对于n是换行,r是回车;我们都是知道的,但是你深入理解过这两个吗?其实这两个是和光标的位置有关系的!
❤️对于n(换行)
⭐️对于换行;我们写完一句话,写完了需要换行,它是对应着当前光标的位置另起一行!但是不从头开始,而是衔接着上一行的位置;比如:
但是C语言里的n实际上有两个功能换行和回车!

❤️对于r(回车)
⭐️对于回车,并不会新起一行,而是在当前行回退到起始位置,原来的内容会被新的内容覆盖,比如:
我们目前就记住一句话:n既回车又换行,r只回车不换行!
🥏3.3 倒时游戏
既然我们理解了前两个,不妨就写一个好玩的倒时小游戏,就利用n和r看看有什么区别!
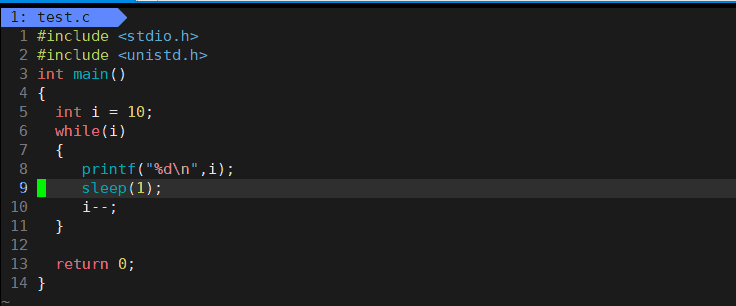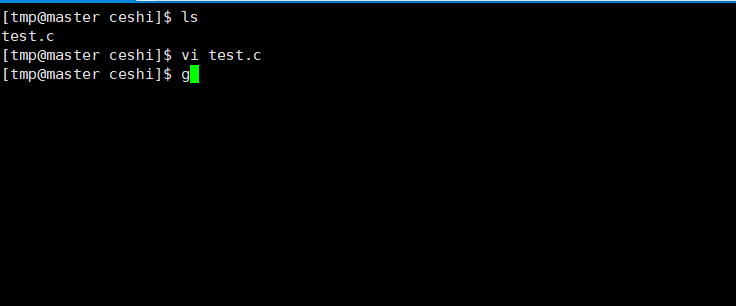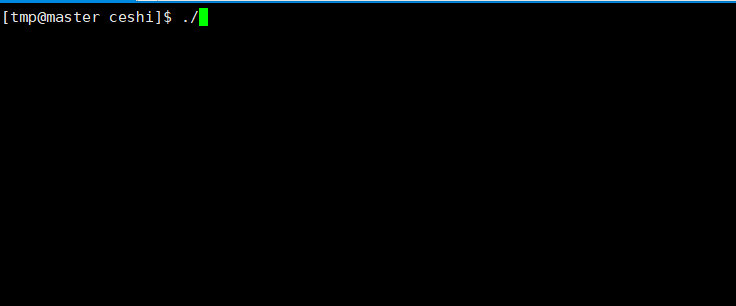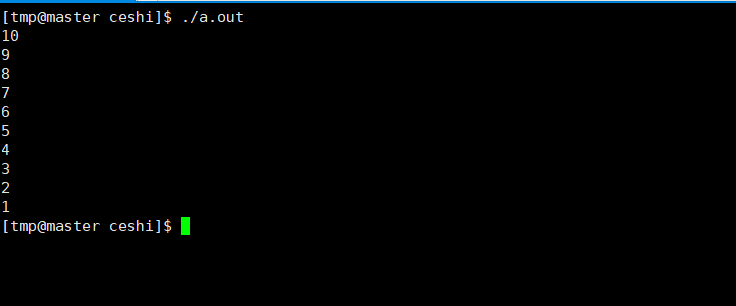
❤️(1)用n
#include 2 #include 3 int main() 4 { 5 int i = 10; 6 while(i) 7 { 8 printf("%dn",i); 9 sleep(1); 10 i--; 11 } 12 13 return 0; 14 }
⭐️运行效果动图如下:
❤️(2)用r
#include 2 #include 3 int main() 4 { 5 int i = 9; 6 while(i) 7 { 8 printf("%dr",i); 9 fflush(stdout); //刷新缓存 10 sleep(1); 11 i--; 12 } 13 14 return 0; 15 }
⭐️运行效果动图如下:
🥏3.4 进度条的编写
有了前面的一整套学习,我们就可以写我们的第一个Linux正式小程序了,进度条的编写!
🥅3.4.1 程序的编写
❤️我们还是分成三个部分:ProcBar.h头文件的包含等、ProcBar.c具体函数的实现、Main功能的测试!

❤️(1)Main.c
#include "ProcBar.h" 2 int main() 3 { 4 process_bar(); 5 return 0; 6 }⭐️主要包括函数的调用,用来测试功能!注意需要引头文件“ProcBar.h”
❤️(2)ProcBar.h
#pragma once #include #include //sleep的头文件 #include //memset的头文件 #define M 101 void process_bar();⭐️主要包括头文件的包含、宏的定义、函数的声名!
❤️(3)ProcBar.h
#include "ProcBar.h" void process_bar() { char arr[M]; memset(arr,0,sizeof(arr));//初始化 const char* p = "|/-\"; int i = 0; while(i<=100) { printf("[%-100s][%-3d%%][%c]r",arr,i,p[i%4]); fflush(stdout); arr[i++] = '#'; usleep(50000);//1s = 1000ms 1ms = 1000um } printf("n"); }⭐️主要包括具体函数的实现!注意需要引头文件“ProcBar.h”
🥅3.4.2 脚本的编写
❤️我么还用前面学过的知识点,利用make和makefile进行编译链接!
❤️makefile脚本的编写
procbar:Main.o ProcBar.o @gcc $^ -o $@ %.o:%.c @gcc -c $< .PHANY:clean clean: @rm -rf procbar *.o⭐️脚本的解释我们前面都已经分析过了,这里只强调一点在前面加的@表示在make和make clean的时候不显示过程!
🥅3.4.3 运行结果的动图展示
❤️程序的代码编写好了,脚本也完成了,接下来就是编译运行啦!请看下面动图效果!

🏀4. gdb工具的简单使用
🥅如何在Linux让程序可调式
❤️gdb --version查看系统中是否有gdb;直接输入gdb回车就能进入gdb的交互模式,退出输入q回车即可!发现系统没有gdb就自己安装,sudo yum -y install gdb即可!
❤️gdb:默认是以release版本的方式进行发布的!我们在学c的时候已经提过,调试版本是debug版本,包含了调试信息;并且debug生成的程序,体积上一定大于release;release是发布版本,是不支持调试的,一般默认会对代码进行优化!
❤️Linux 默认是release版本,如何改成debug版本呢?直接在Makefile脚本里的gcc编译时加一个参数-g就可以了!生成的是debug版本,包含着调试的信息,怎么查看呢?
readelf -Sh 可执行文件 | grep debug即可,例如下面:

🥅gdb的调试
我们调试肯定需要一个程序,先写一个求前100和的程序,在写好nakefile里面的脚本,具体如下:
❤️代码
#include
2 int my_sum(int n)
3 {
4 int i = 0;
5 int sum = 0;
6 for(i = 1;i<=n;i++)
7 {
8 sum += i;
9 }
10 return sum;
11
12 }
13 int main()
14 {
15 printf("process begin runing...n!");
16 int result = my_sum(100);
17 printf("result:%dn",result);
18 printf("process end runing...n!");
19
20 return 0;
21 }
❤️makefile脚本
mytest:test.o
@gcc $^ -o $@ -g "-g参数生成debug版本"
%.o:%.c
@gcc -c $< -g
.PHONY:clean
clean:
@rm -rf *.o mytest ❤️调试
❤️gdb mytest就可以进入交互模式;
⭐️输入l就可以看到代码;l 1可以看到第一行的代码,在回车就可以看到整个代码
⭐️打断点b+行号;
⭐️r运行代码,到断点处停止;如果没有断点r直接运行程序到结束;类似于VS中的F5
⭐️n(next)表示一步步代码往下走,是逐过程直接跳过函数,相当于VS中的F10;
⭐️s(step)表示逐语句,会进入函数内部,相当于VS中的F11
⭐️info b查看断点,并给断点表上新的数字(从1开始);
⭐️d 1删除断点,删除后info b在查看,就没有断点信息了 ;
⭐️c(continue):从一个断点直接跳转到另一个断点;
⭐️display常显示:display i 就可以看到i变量的变化,想看地址加上&i就可以了;
⭐️undisplay+数字,取消常显示;和删除断点一样,看新的编号,而不是行号
⭐️until + 行号:表示跳到指定行,一般用来跳出循环;
⭐️再次r,就可以重新运行到断点处,重新进行调试;
⭐️finish:会直接跳出函数内部,结束函数调用,然后停下;
⭐️q:跳出gdb,结束调试




