深度学习CV八股文
- 一、深度学习中解决过拟合方法
- L1和L2正则化
- Dropout
- Dropout正则化
- Inverted Dropout(反向随机失活)
- Dropout起到正则化效果的原因:
- Dropout的缺点
- eargstopping ( 早停法 )
- 二、深度学习中解决欠拟合方法
- 三、梯度消失和梯度爆炸
- 解决梯度消失的方法
- 解决梯度爆炸的方法
- 四、神经网络权重初始化方法
- Xavier
- 指数加权移动平均数
- 五、梯度下降法
- 梯度下降
- SGD(随机梯度下降法)
- Momentum(动量梯度下降)
- Nesterov Momentum
- 自适应学习率算法
- Adagrad
- RMSprop
- Adam
- NAdam
- 六、学习率衰减
- 七、BatchNorm
- BN的作用
- BN的缺点
- 测试时的BN
- 八、内部协变量偏移
- 九、归一化方法
- LayerNormalization
- Instance Normalization
- Group Nomalization
- 对比
- 十、卷积
- 卷积的优点
- 1x1Conv(点卷积)
- Depthwise Separable Convolution
- Mlpconv
- 十一、池化
- 十二、激活函数
- Sigmoid
- tanh
- ReLU
- ReLU的变体
- Swish
- 十三、预训练
- 预训练的好处
- 什么是预训练
- 十四、Transformer
- Attention
- self-attention
- self-attention缩放(归一化)的原因
- self-attention采用点乘而不是加线性注意力的原因:
- 作用
- Mutil_Head Attention
- Mutil_Head Attention的作用
- MLP
- 残差连接的目的:
- Patch Embedding
- Learnable Embedding
- Position Embedding
- 十五、损失函数
- 交叉熵函数
- 从KL散度到交叉熵
- MSE
- 十六、度量指标分析
- F1-score
- precision
- recall
- PR曲线
- ROC-AUC
- ROC
- AUC
- 训练模型时的F1-score和AUC的选择
- 十七、经典的模块组合方法
- Res和Dense
- Res
- Dense
- 如何选择Res和Concat
- 多尺度卷积
- Inverted Residual 和Linear Bottleneck
- Inverted Residual
- Linear Bottleneck
- Group Average Pooling +1x1 Conv与FC
- Squeeze-and-Excitation(SE)
一、深度学习中解决过拟合方法
- 数据增强
- L1和L2正则化
- Dropout正则化
- early stopping
- BatchNorm
L1和L2正则化
L1正则化直接在原来的损失函数基础上加上权重参数的绝对值:
l
o
s
s
=
J
(
w
,
b
)
+
λ
2
m
∑
∣
w
∣
loss=J(w,b)+frac{lambda}{2m}sum|w|
loss=J(w,b)+2mλ∑∣w∣
L2正则化直接在原来的损失函数基础上加上权重参数的平方和:
l
o
s
s
=
J
(
w
,
b
)
+
λ
2
m
∑
∥
w
∥
F
2
loss=J(w,b)+frac{lambda}{2m}sumlVert wlVert _F^2
loss=J(w,b)+2mλ∑∥w∥F2
L1和L2正则化能够缓解过拟合的原因:
神经网络就是一个函数,对其进行傅里叶变换求得频谱,频谱中低频分量就是变化平滑的部分,高频分量就是变化敏感的部分。模型对于微小扰动的反馈差异大实际就是一个过拟合的表现,也就是高频分量不能多。根据雅各比矩阵(一阶导数矩阵),神经网络这个函数的高频分量存在上界,上界和谱范数正相关。谱范数逆变换回时域,可求得和参数范数正相关。正则就是将参数的范数加入loss里求最优化,故而限制了神经网络学到高频分量,更倾向于一个低频的平滑的函数,从而缓解过拟合。
推导过程:https://blog.csdn.net/StreamRock/article/details/83539937
Dropout
Dropout正则化
步骤:
- 遍历神经网络每一层节点,设置节点保留概率keep_prob(每一层的keep_prob可以不同,参数多的层keep_prob可以小一些,少的可以多一些)。
- 删除神经网络节点和从该节点进出的连线。
- 输入样本使用简化后的神经网络进行训练。
每次输入样本都要重复以上三步
Inverted Dropout(反向随机失活)
步骤:
- 产生⼀个[0,1)的随机矩阵,维度与权重矩阵相同。
- 设置节点保留概率keep_prob 并与随机矩阵比较,小于为1,大于为0。
- 将权重矩阵与0-1矩阵对应相乘得到新权重矩阵。
- 对新权重矩阵除于keep_prob(保证输⼊均值和输出均值一致),保证权重矩阵均值不变,层输出不变。
测试阶段不需要使用dropout,因为如果在测试阶段使用dropout会导致预测值随机变化 , 而且在训练阶段已经将权重参数除以 keep_prob 保证输出均值不变所以在刚试阶段没必要使用dropout
Dropout起到正则化效果的原因:
- Dropout可以使部分节点失活,起到简化神经网络结构的作用,从而起到正则化的作用。
- Dropout使神经网络节点随机失活,所以神经网络节点不依赖于任何输⼊,每个输入的权重都不会很⼤。Dropout最终产⽣收缩权重的平方范数的效果,压缩权重效果类似L2正则化。
Dropout的缺点
没有明确的损失函数。
eargstopping ( 早停法 )
训练时间和泛化误差的权衡。提早停⽌训练神经网络得到⼀个中等大小的W的F范数,与L2正则化类似。
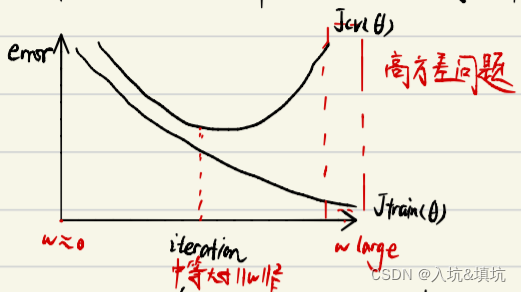
在训练中计算模型在验证集上的表现,当模型在验证集上的误差开始增大时,停止训练。这样就可以避免继续训练导致的过拟合问题。
二、深度学习中解决欠拟合方法
增加神经网络层数或神经元个数
三、梯度消失和梯度爆炸
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
梯度饱和:越来越趋近一条直线(平行X轴的直线),梯度的变化很小
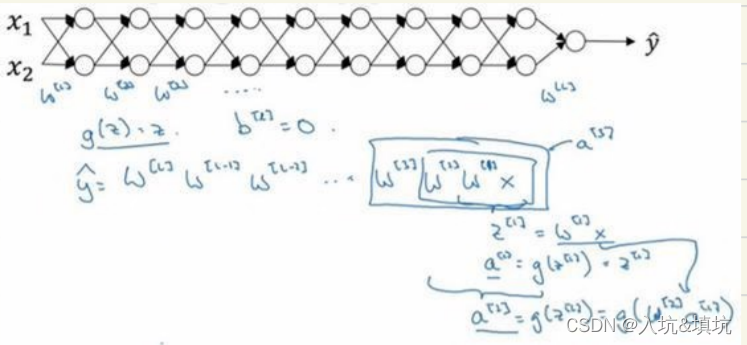
设激活函数是线性或函数,忽略b。
g
(
z
)
=
z
g(z)=z
g(z)=z
y
^
=
W
(
l
)
W
(
l
−
1
)
⋯
W
(
2
)
W
(
1
)
x
hat{y} = W^{(l)} W^{(l-1)} cdots W^{(2)} W^{(1)} x
y^=W(l)W(l−1)⋯W(2)W(1)x
当
W
(
l
)
>
1
W^{(l)}>1
W(l)>1时,如
W
(
l
)
=
[
1.5
0
0
1.5
]
W^{(l)}=begin{bmatrix} 1.5 & 0 \ 0 & 1.5 \ end{bmatrix}
W(l)=[1.5001.5],
y
^
=
W
(
l
)
[
1.5
0
0
1.5
]
(
l
−
1
)
x
=
1.
5
(
l
)
x
hat{y}=W^{(l)}begin{bmatrix} 1.5 & 0 \ 0 & 1.5 \ end{bmatrix}^{(l-1)}x=1.5^{(l)}x
y^=W(l)[1.5001.5](l−1)x=1.5(l)x。此时,激活函数值/梯度函数值呈指数级增长=>梯度爆炸
当
W
(
l
)
>
1
W^{(l)}>1
W(l)>1时,如
W
(
l
)
=
[
0.5
0
0
0.5
]
W^{(l)}=begin{bmatrix} 0.5 & 0 \ 0 & 0.5 \ end{bmatrix}
W(l)=[0.5000.5],
y
^
=
W
(
l
)
[
0.5
0
0
0.5
]
(
l
−
1
)
x
=
0.
5
(
l
)
x
hat{y}=W^{(l)}begin{bmatrix} 0.5 & 0 \ 0 & 0.5 \ end{bmatrix}^{(l-1)}x=0.5^{(l)}x
y^=W(l)[0.5000.5](l−1)x=0.5(l)x。此时,激活函数值/梯度函数值呈指数级递减=>梯度消失
∂
J
(
θ
)
∂
θ
i
j
=
∂
J
(
θ
)
∂
z
i
l
+
1
⋅
∂
z
i
l
+
1
∂
θ
i
j
frac{partial{J(theta)}}{partial{theta_ij} }=frac{partial{J(theta)}}{partial{z^{l+1}_i} } cdot frac{partial{z^{l+1}_i}}{partial{theta_ij} }
∂θij∂J(θ)=∂zil+1∂J(θ)⋅∂θij∂zil+1
解决梯度消失的方法
- Relu及其变体
- LSTM/GRU
- 残差结构
- BatchNorm
- Xavier初始化(修正w的方差,避免w过小)
解决梯度爆炸的方法
- 梯度裁剪
- 正则化(将w加入Loss里,如果Loss小则w也要小,而梯度爆炸是w过大[绝对值]造成的)
- Xavier初始化(修正w的方差,避免w过大)
- BatchNorm
四、神经网络权重初始化方法
Xavier
X和Z的方差在各层相等,激活值在网络供传递过程中就不会放大或缩小。
解决梯度消失和梯度爆炸问题
z
=
∑
i
=
1
n
w
i
x
i
z= sum_{i=1}^n w_ix_i
z=∑i=1nwixi
v
a
r
(
w
i
x
i
)
=
E
[
w
i
]
2
v
a
r
(
x
i
)
+
E
[
x
i
]
2
v
a
r
(
w
i
)
+
v
a
r
(
w
i
)
v
a
r
(
x
i
)
var(w_ix_i)=E[w_i]^2var(x_i)+E[x_i]^2var(w_i)+var(w_i)var(x_i)
var(wixi)=E[wi]2var(xi)+E[xi]2var(wi)+var(wi)var(xi)
若
E
[
w
i
]
=
E
[
x
i
]
=
0
E[w_i]=E[x_i]=0
E[wi




