
✌ 作者简介:信年✘ ✌,大家可以叫我 ❤信年❤ ,一位精通五门语言的博主 ✌
🏆 CSDN博客专家认证、华为云享专家、阿里云专家博主 、掘金创作榜No.1
📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
💬 人生格言:没有我不会的语言,没有你过不去的坎儿。💬
🔥 如果感觉博主的文章还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
📌作者主页传送门:点此传送
🔎系列文章&专栏推荐:暂未开放
🌐为大家推荐一款刷题网站呀👉点击跳转
所有编程语言,都可以从此网站中找到并参考学习哟~
目录
1 引言
1.1 项目简介
1.2 数据集介绍
2 环境安装
2.1 克隆PaddleDetection
2.2 安装依赖库
3 数据准备
3.1 解压数据集
3.2 数据集格式转换
4 模型训练
4.1 修改配置文件
4.2 启动训练
4.3 训练可视化
5 模型评估
6 模型预测
6.1 开始预测
6.2 可视化预测图片
7 模型导出
8 总结
1 引言
1.1 项目简介
对于交通标志识别系统,其核心作用就是可以准确并及时的识别道路交通标志信息获取当前路况以及行车环境,从而起到提醒和辅助驾驶员对道路信息的把控以及纠正错误交通行为的作用。
传统的目标检测算法容易受到多种因素影响导致算法实现困难、识别精度低、识别速率慢等问题。随着深度学习的发展,人工智能的检测方法受到广泛关注与认可,可以有效地解决误检率高、速度慢等问题。
为解决交通标志识别问题,本项目使用飞桨场景应用开发套件PaddleDetecion中的PicoDet_LCNet模型进行训练,预测,并完成整体流程。本项目包括环境安装、数据准备、模型训练、模型评估、模型预测、模型导出、总结以及附录等主要部分。
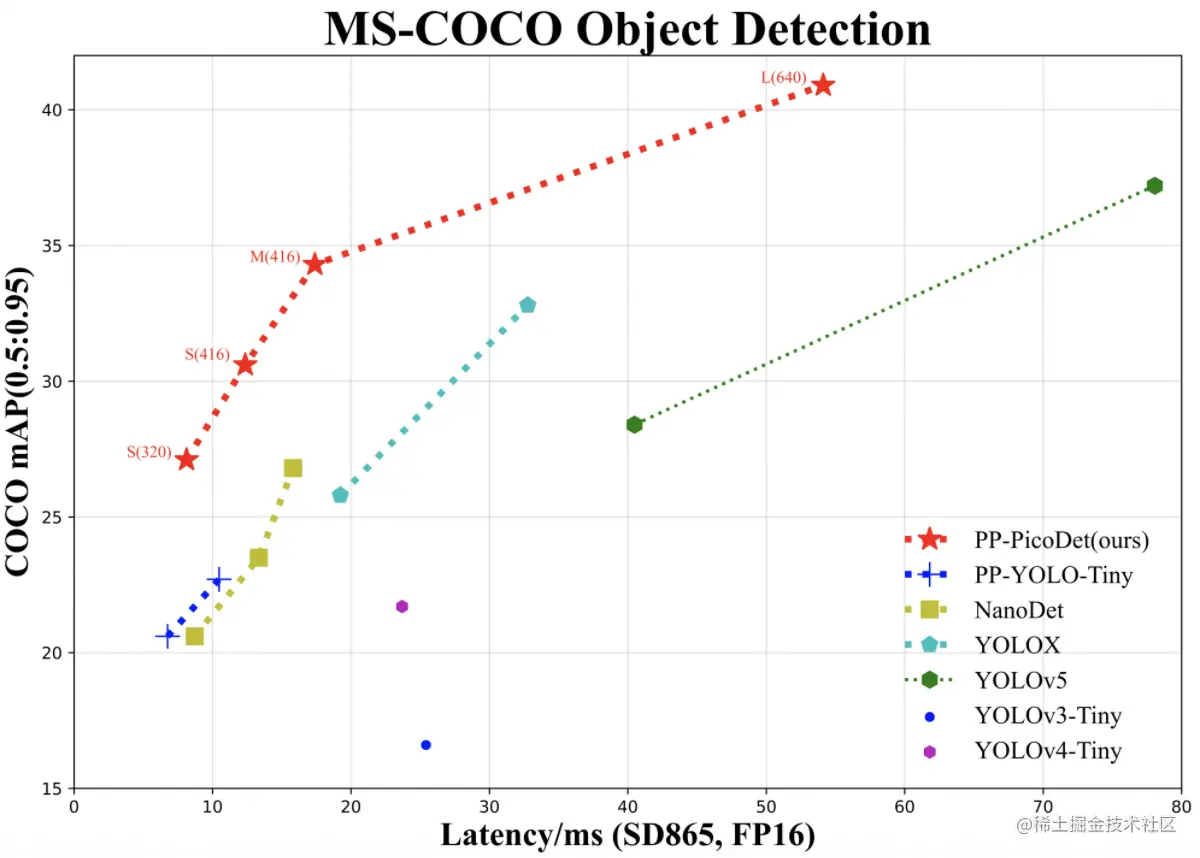
PP-PicoDet有着精度高(PicoDet-S仅1M参数量以内,416输入COCO mAP达到30.6),速度快(PicoDet-S-320在SD865上可达150FPS),部署友好(支持Paddle Inference、Paddle Lite,支持快速导出为ONNX格式,支持Python、C++、Android 部署)等特点。PicoDet具体的指标如下图所示:
1.2 数据集介绍
该数据集源自中国交通标志识别数据库。里加数据科学俱乐部成员已经探索了它,以便对卷积神经网络进行一些训练。
数据集由 58 个类别的 5998 张交通标志图像组成。每个图像都是单个交通标志的放大视图。注释提供图像属性(文件名、宽度、高度)以及图像和类别中的交通标志坐标(例如,限速 5 公里/小时),如下图所示。


该数据集由png图片以及annotations.csv文件构成。
annotations.csv构成:
file_name:包含交通标志的图像的文件名
width:图片宽度
height:图片高度
x1:边界矩形左上角X坐标
y1:边界矩形左上角Y坐标
x2:边界矩形右下角X坐标
y2:边界矩形右下角Y坐标
category:交通标志类别2 环境安装
2.1 克隆PaddleDetection
PaddleDetection作为成熟的目标检测开发套件,提供了从数据准备、模型训练、模型评估、模型导出到模型部署的全流程。
- Github地址:github.com/PaddlePaddl…
- Gitee地址:gitee.com/PaddlePaddl…
使用如下命令完成克隆操作:
# 从github上克隆,若网速较慢也可以考虑从gitee上克隆
! git clone https://gitee.com/PaddlePaddle/PaddleDetection2.2 安装依赖库
通过如下方式安装PaddleDetection依赖,并设置环境变量
%cd ~/work/PaddleDetection/
!pip install -r requirements.txt
%env PYTHONPATH=.:$PYTHONPATH
%env CUDA_VISIBLE_DEVICES=0通过如下命令验证是否安装成功
! python ppdet/modeling/tests/test_architectures.py3 数据准备
该数据集源自中国交通标志识别数据库。里加数据科学俱乐部成员已经探索了它,以便对卷积神经网络进行一些培训。
数据集由 58 个类别的 5998 张交通标志图像组成。每个图像都是单个交通标志的放大视图。注释提供图像属性(文件名、宽度、高度)以及图像和类别中的交通标志坐标(例如,限速 5 公里/小时)
目前PaddleDetection支持:COCO VOC WiderFace, MOT四种数据格式。因此,先解压数据集压缩包,再按照VOC格式将csv文件转化为xml。
3.1 解压数据集
%cd ~
# 解压所挂载的数据集在同级目录下
!unzip -oq data/data107275/archive(5).zip -d data/TrafficSignsVoc3.2 数据集格式转换
本项目采用VOC格式数据。VOC数据格式的目标检测数据,是指每个图像文件对应一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
├── Annotations
│ ├── 001_0001.xml
│ ├── 001_0002.xml
│ ...
├── pngImages
│ ├── 001_0001.png
│ ├── 001_0002.png
│ ...
├── label_list.txt
├── train.txt
└── valid.txtlabel_list.txt:
0
1
...
57train.txt/valid.txt:
./pngImages/014_0051.png ./Annotations/014_0051.xml
./pngImages/017_0031.png ./Annotations/017_0031.xml
./pngImages/015_0012.png ./Annotations/015_0012.xml
./pngImages/028_0025.png ./Annotations/028_0025.xml
...xml文件中包含以下字段:
-
filename,表示图像名称。
001_0008.png -
size,表示图像尺寸。包括:图像宽度、图像高度、图像深度
118
119
3
-
object字段,表示每个物体。包括
name: 目标物体类别名称pose: 关于目标物体姿态描述(非必须字段)truncated: 目标物体目标因为各种原因被截断(非必须字段)occluded: 目标物体是否被遮挡(非必须字段)difficult: 目标物体是否是很难识别(非必须字段)bndbox: 物体位置坐标,用左上角坐标和右下角坐标表示:xmin、ymin、xmax、ymax
按照以上所述VOC格式,通过运行以下脚本可以将csv文件转化为xml,并生成相应txt文件
import os
import numpy as np
import codecs
import pandas as pd
import json
from glob import glob
import cv2
import shutil
from sklearn.model_selection import train_test_split
# from IPython import embed
#1.标签路径
csv_file = "data/TrafficSignsVoc/annotations.csv"
saved_path = "data/TrafficSignsVoc/VOC2007/" #VOC格式数据的保存路径
image_save_path = "./pngImages"
image_raw_parh = "data/TrafficSignsVoc/images/"
#2.创建需要的文件夹
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
if not os.path.exists(saved_path + "pngImages/"):
os.makedirs(saved_path + "pngImages/")
#3.获取待处理文件
total_csv_annotations = {}
annotations = pd.read_csv(csv_file,header=None).values
for annotation in annotations:
key = annotation[0].split(os.sep)[-1]
value = np.array([annotation[1:]])
if key in total_csv_annotations.keys():
total_csv_annotations[key] = np.concatenate((total_csv_annotations[key],value),axis=0)
else:
total_csv_annotations[key] = value
#4.读取标注信息,按VOC格式写入xml
for filename,label in total_csv_annotations.items():
if filename == 'file_name':
continue
height, width, channels = cv2.imread(image_raw_parh + filename).shape
with codecs.open(saved_path + "Annotations/"+filename.replace(".png",".xml"),"w","utf-8") as xml:
xml.write('n')
xml.write('t' + 'pngImages' + 'n')
xml.write('t' + filename + 'n')
xml.write('tn')
xml.write('tt'+ str(width) + 'n')
xml.write('tt'+ str(height) + 'n')
xml.write('tt' + str(channels) + 'n')
xml.write('tn')
xml.write('t0n')
if isinstance(label,float):
xml.write('')
continue
for label_detail in label:
labels = label_detail
xmin = int(labels[2])
ymin = int(labels[3])
xmax = int(labels[4])
ymax = int(labels[5])
label_ = labels[-1]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
xml.write('tn')
print(filename,xmin,ymin,xmax,ymax,labels)
xml.write('')
#6.创建txt文件(可以不创建,后面用Paddlex划分数据集时生成相应的txt文件)
txtsavepath = saved_path
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/valid.txt', 'w')
flabel = open(txtsavepath+'/label_list.txt', 'w')
total_files = glob(saved_path+"./Annotations/*.xml")
total_files = [i.split("/")[-1].split(".xml")[0] for i in total_files]
# 将图片复制到voc pngImages文件夹
for image in glob(image_raw_parh+"/*.png"):
shutil.copy(image,saved_path+image_save_path)
train_files,val_files = train_test_split(total_files,test_size=0.15,random_state=42)
for file in train_files:
ftrain.write("./pngImages/" + file + ".png" + " ./Annotations/" + file+ ".xml" + "n")
#val
for file in val_files:
fval.write("./pngImages/" + file + ".png" + " ./Annotations/" + file+ ".xml" + "n")
for i in range(58):
flabel.write(str(i) + "n")
ftrain.close()
fval.close()
flabel.close()4 模型训练
4.1 修改配置文件
本项目使用的是work/PaddleDetection/configs/picodet/picodet_s_320_coco_lcnet.yml配置文件,该配置文件中涉及到的其他配置文件以及修改的具体配置如下所示:
(1) work/PaddleDetection/configs/picodet/picodet_s_320_coco_lcnet.yml
- 保存训练的轮数:
snapshot_epoch: 10
(2) work/PaddleDetection/configs/picodet/base/picodet_320_reader.yml
- 数据读取进程数量,根据本地算力资源调整:
worker_num: 6 - 根据显存大小调整:
batch_size: 64
(3) work/PaddleDetection/configs/picodet/base/optimizer_300e.yml
- 学习率:
base_lr: 0.04 - 训练轮数:
epoch: 300
(4) work/PaddleDetection/configs/datasets/voc.yml
- 数据集包含的类别数:
num_classes: 58 - 图片相对路径:
dataset_dir: dataset/VOC2007 anno_path: train.txtlabel_list: label_list.txt- 数据格式
metric: VOC
更多关于PaddleDetection的详细信息可参考30分钟快速上手PaddleDetection以及官方说明文档
4.2 启动训练
通过指定visualDL可视化工具,对loss变化曲线可视化。仅需要指定 use_vdl 参数和 vdl_log_dir 参数即可。使用如下命令进行模型训练。
# 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数
!python tools/train.py -c configs/picodet/picodet_s_320_coco_lcnet.yml
-o use_gpu=true
-o pretrain_weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_coco.pdparams
--use_vdl=true
--vdl_log_dir=vdl_dir/scalar
--eval
# 指定配置文件
# 设置或更改配置文件里的参数内容
# 预训练权重
# 使用VisualDL记录数据
# 指定VisualDL记录数据的存储路径
# 边训练边测试4.3 训练可视化
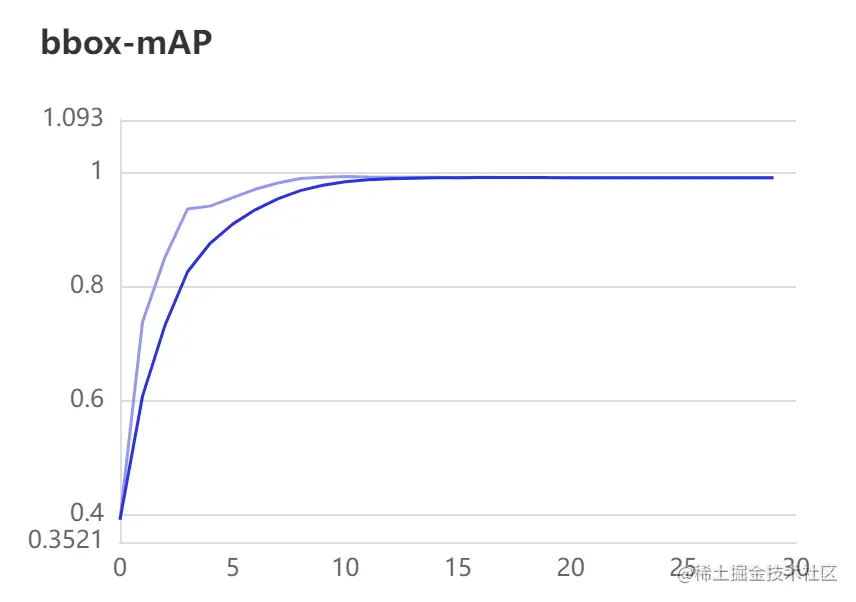
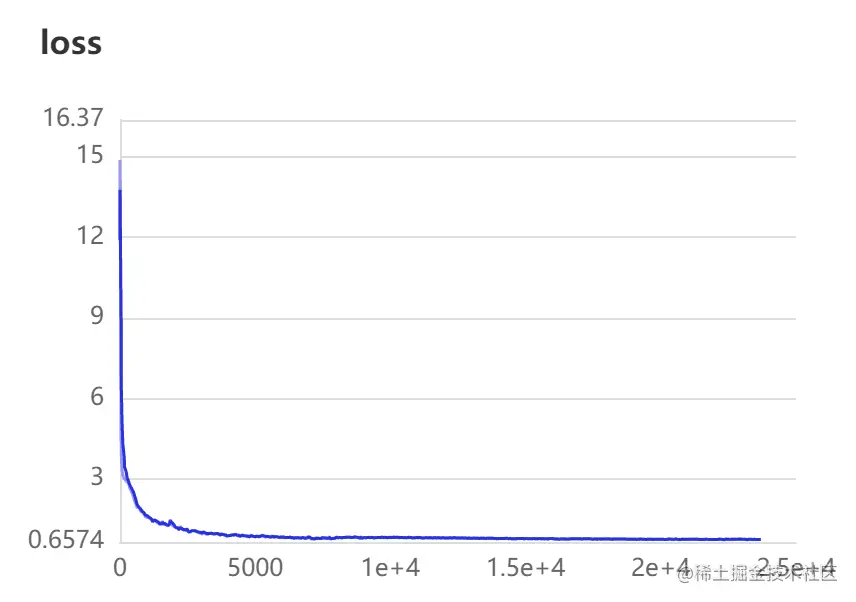
上一步训练过程中已开启VisualDL可视化工具,VisualDL记录数据的存储路径为 work/PaddleDetection/vdl_dir/scalar,其训练可视化结果如下所示:
最终训练结果 mAP = 99.16%mAP=99.16,训练效果很不错,达到应用级别效果。
5 模型评估
!python tools/eval.py -c configs/picodet/picodet_s_320_coco_lcnet.yml
-o weights=output/picodet_s_320_coco_lcnet/model_final.pdparams
# 指定模型配置文件
# 加载训练好的模型 6 模型预测
6.1 开始预测
加载训练好的模型,置信度阈值设置为0.5,执行下行命令对验证集或测试集图片进行预测,此处挑选了一张验证集图片进行预测,并输出预测后的结果到infer_output文件夹下。得到的预测结果如下所示:

!python3.7 tools/infer.py -c configs/picodet/picodet_s_320_coco_lcnet.yml
--infer_img=/home/aistudio/work/PaddleDetection/dataset/VOC2007/pngImages/005_0047.png
--output_dir=infer_output/
--draw_threshold=0.5
-o weights=output/picodet_s_320_coco_lcnet/model_final
# 指定模型配置文件
# 测试图片
# 结果输出位置
# 置信度阈值
# 加载训练好的模型 6.2 可视化预测图片
import cv2
import matplotlib.pyplot as plt
import numpy as np
image = cv2.imread('infer_output/005_0047.png')
plt.figure(figsize=(8,8))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()运行结果如下图所示:

7 模型导出
将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
预测模型会导出到inference_model/目录下,包括model.pdmodel、model.pdiparams、model.pdiparams.info和infer_cfg.yml四个文件,分别表示模型的网络结构、模型权重、模型权重名称和模型的配置文件(包括数据预处理参数等)的流程配置文件。
!python tools/export_model.py
-c configs/picodet/picodet_s_320_coco_lcnet.yml
-o weights=output/picodet_s_320_coco_lcnet/model_final.pdparams
--output_dir=inference_model8 总结
- 🌟 经模型评估,对于经过300轮训练的模型效果为:mAP(0.50, 11point) = 99.16%mAP(0.50,11point)=99.16。
- 🌟 PaddleDetecion中的PicoDet_LCNet模型上手方便,各种模型的配置文件可根据自己需求去修改调整,可复用程度高,因此大大提高了效率。当然,PaddleDetection套件中还包含了很多种类的模型,提供多种主流目标检测、实例分割、跟踪、关键点检测算法,能够满足大大小小的开发需求,从而更好完成端到端全开发流程。
- 🔥 注:本文使用的是飞桨深度学习开发套件,编译器为AI Studio Notebook平台。
- 🔥 本文旨在为读者提供深度学习流程思路参考,若需要运行时,请注意调整文件路径。
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨




