🚩 前言
活动地址:CSDN21天学习挑战赛
🚀 博主主页:阿阿阿阿锋的主页_CSDN
今天学到了多层感知机的softmax回归。
在调整超参数观察它对于实验结果的影响时,突然发现我遇到了一个问题:在超参数不变的情况下,多次模型训练的结果也可能是不同的。
这种不同并不是很小。其中有两次,在相同超参数下的训练,模型在测试集上的分类正确率分别为 86.5% 和 83.3%。
文章目录
- 🚩 前言
- 1. 🌱训练结果不稳定
- 2. 🌲全相同值初始化
- 3. 🌳为何丧失拟合能力
- 4. 🌴赋不同值初始化
- 5. 🌵附录:初完整代码
- 🚩 总结
1. 🌱训练结果不稳定
虽然我大致知道模型中的每段代码大致在做什么,但现在我有些茫然了,感觉这些代码根本不在我的掌控之中。这种感觉有点糟糕,不过学习本来就是一个一边使用和一边了解的过程。
我后来猜测原因应该在权重参数那里。因为,权重参数是使用随机取样来初始化的。我这里使用的是正态分布(normal)中的随机取样。也就是说,每次开始训练时,初始模型参数都不一样。
参数初始化部分的代码:
num_inputs, num_outputs = 784, 10
num_hiddens, num_hiddens2 = 256, 30
W1 = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens))
b1 = nd.zeros(num_hiddens)
W2 = nd.random.normal(scale=0.01, shape=(num_hiddens, num_hiddens2))
b2 = nd.zeros(num_hiddens2)
W3 = nd.random.normal(scale=0.01, shape=(num_hiddens2, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
2. 🌲全相同值初始化
考虑到很可能是权值参数导致的每次训练的结果有浮动,那不如就试试每次都从相同的权值参数开始训练,这样我后面调超参数的时候,应该就好观察一点。我一开始想的是简单起见,把所有的权值都设置为 1 试试。
改动后的参数初始化代码:
num_inputs, num_outputs = 784, 10
num_hiddens, num_hiddens2 = 256, 30
W1 = nd.ones((num_inputs, num_hiddens))
b1 = nd.zeros(num_hiddens)
W2 = nd.ones((num_hiddens, num_hiddens2))
b2 = nd.zeros(num_hiddens2)
W2 = nd.ones((num_hiddens2, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
改动后的运行情况:
epoch 1, loss 9765948.7299, train acc 0.100, test acc 0.100
epoch 2, loss 2.3032, train acc 0.099, test acc 0.100
epoch 3, loss 2.3031, train acc 0.100, test acc 0.100
epoch 4, loss 2.3031, train acc 0.098, test acc 0.100
epoch 5, loss 2.3031, train acc 0.098, test acc 0.100
可以看到,在第一个训练周期中,损失值(loss)很大。后来损失值虽然变小了,但是在测试集上的准确率(test acc)却没有动静,始终为10%。而数据集中刚好一共就是10个类别。可以说,这分类,它完全就是蒙的。人工智障了属于是。
改动前正常的运行情况:
epoch 1, loss 1.4737, train acc 0.429, test acc 0.725
epoch 2, loss 0.6242, train acc 0.764, test acc 0.809
epoch 3, loss 0.4948, train acc 0.818, test acc 0.836
epoch 4, loss 0.4394, train acc 0.836, test acc 0.839
epoch 5, loss 0.4031, train acc 0.850, test acc 0.862
3. 🌳为何丧失拟合能力
我刚刚是将初始权值参数全部设置为 1, 我也尝试了许多其它的数,无一例外,模型都无法成功训练。查了一些资料后,我发现了一个问题。
如果一层中,所有的参数都初始化为一样的,这一层就相当于只有一个神经元节点了。以一个简单的情况作为例子:
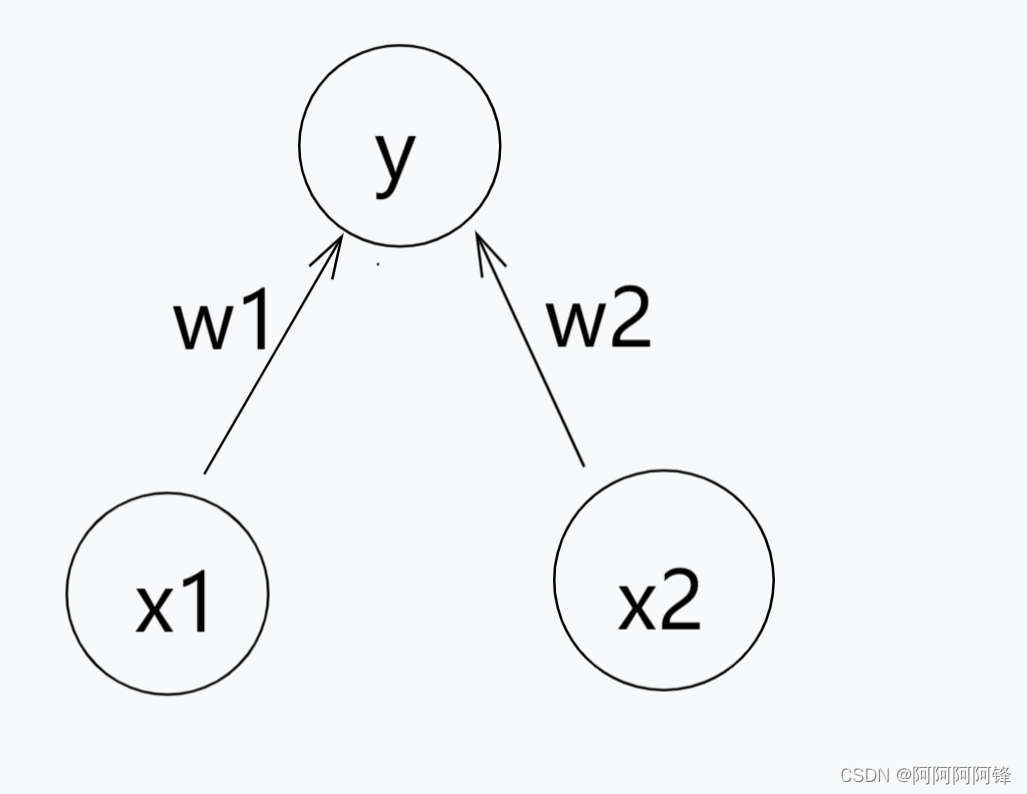
简单起见,这里我们也不考虑偏差参数(bias)。那么我们模型得到的函式就是:
f ( x 1 , x 2 ) = w 1 x 1 + w 2 x 2 f(x1, x2) = w1x1 + w2x2 f(x1,x2)=w1x1+w2x2
当权值参数都相同,即 w1 = w2 时,函数就可以写成:
f ( x 1 , x 2 ) = w ( x 1 + x 2 ) f(x1, x2) = w(x1+x2) f(x1,x2)=w(x1+x2)
再用 x 代替(x1 + x2):
f ( x ) = w x f(x) = wx f(x)=wx
而无论我们设置了多少节点,有多少权重参数,如果这些参数是相同的,那我们的模型仍然只拥有一元线性函式的拟合能力。
但是,我们只是初始权值参数是相同的,那么训练后的权值参数仍然一定是相同的吗?
在我的模型训练过程中,是使用通过梯度的反向传播,来更新模型参数的(lr为学习率):
w = w − l r Δ w w = w - lr Delta w w=w−lrΔw
如果不同节点得到的梯度反馈都是相同的,而初始值权值也相同,那么在训练过程中,权值自然会始终保持相同。而一维的线性模型,面对相对复杂的、非线性的分类任务,除了蒙,还能怎样呢?
关于梯度下降导致模型失去足够的拟合能力,下面提供我个人的一种稍稍形象一些的理解方式,仍然以我们之前的简单模型作为例子:
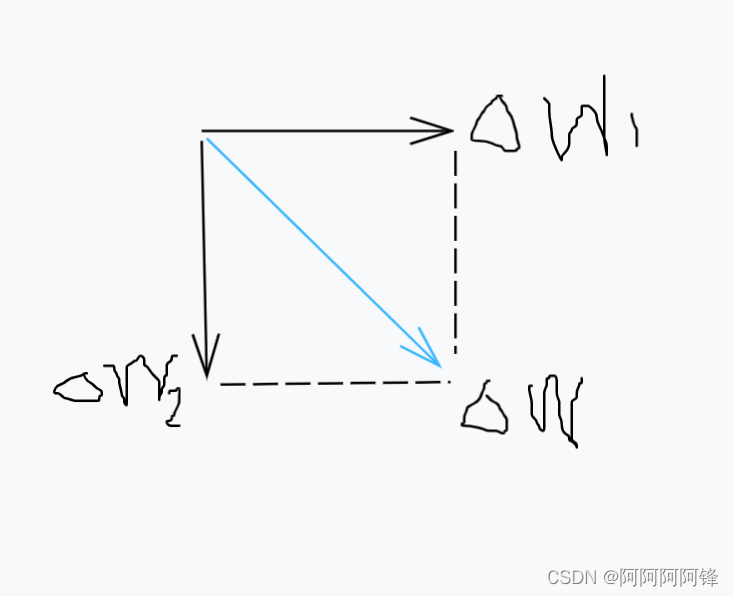
因为两个权值参数的初始值相等会导致:这两个参数的更新方向和幅度也是相等的。那么整个模型的训练过程中,权值参数向量的更新方向
(Δw1, Δw2)就是恒定的。这样会造成什么问题呢?
l
o
s
s
=
f
(
w
1
,
w
2
)
loss = f(w1, w2)
loss=f(w1,w2)
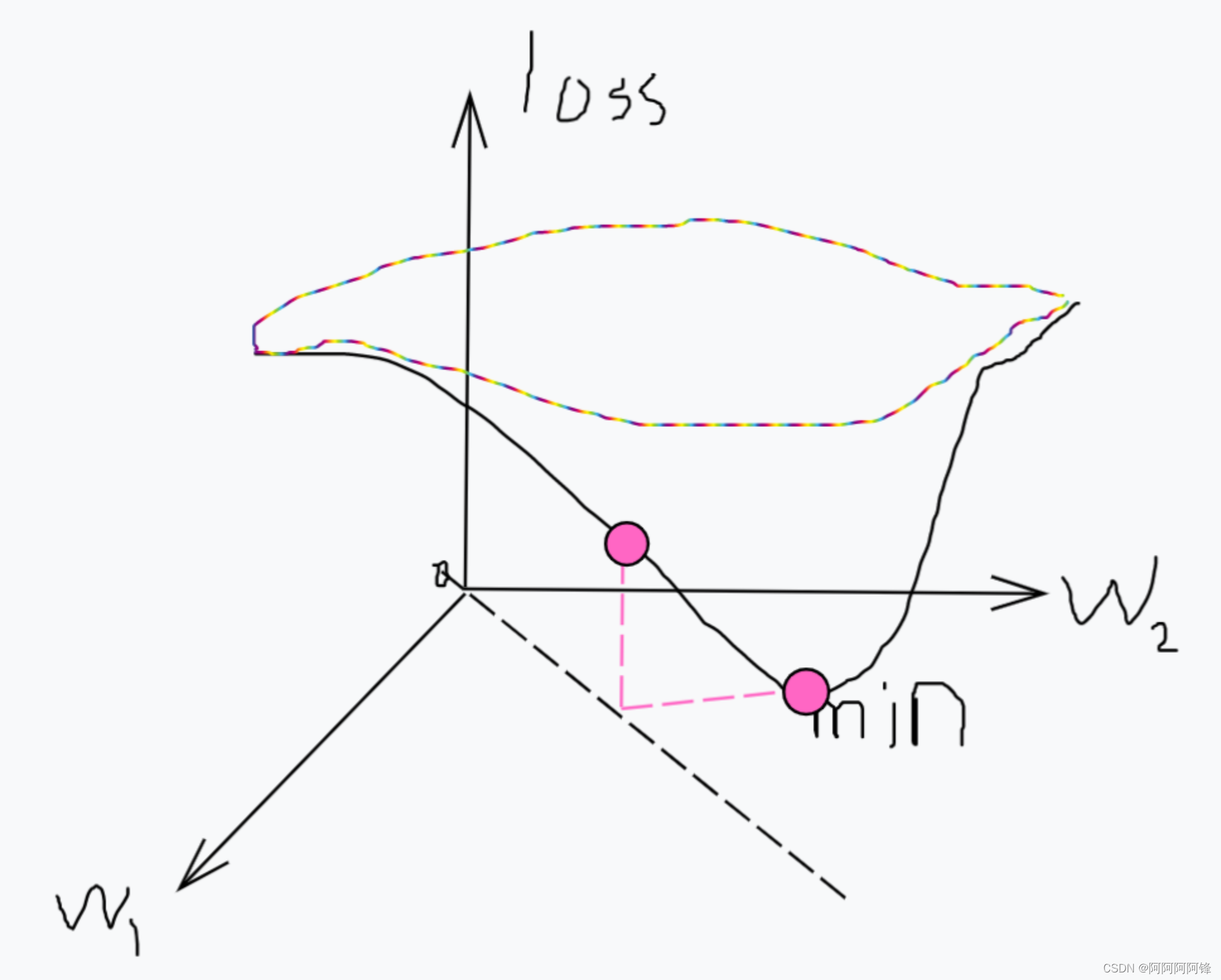
设图中的min就是我们要找的全局最优点(损失最小的点),而点
(w1, w2)就只能在图中的虚线上移动。它可以移动到一个比较靠近min的位置,而使得损失值loss变得较小。但显然模型的整个拟合效果常常是很差的。这样的分析也比较符合我们之前的运行结果:损失值变小一次后就不再改变,而模型的预测准确率则完全像是蒙的。
当然,这也只是我自己一个用来帮助理解的想法,供大家参考一下。
4. 🌴赋不同值初始化
不要忘了最初的目标,我只是想着用固定的初始权值参数,调超参数时,可能好观察和比较结果一点。那是不是只要我为这些参数都附上不同的值,模型就可以正常进行训练了呢?
理论上应该是可以的。我尝试用下面的代码来对一层权值参数的所有元素逐个来进行初始化:
k = 0.0000001
sum = 0.01
flag = 1
for i in range(num_inputs):
for j in range(num_hiddens):
W1[i][j] = sum * flag
flag = -flag
sum += k
但是,我发现这段代码运行起来实在是慢得可怜。python执行矩阵运算会比逐个元素的运算慢很多(是为什么我现在也还不知道)。希望到这里暂时就破灭了。哈哈。
5. 🌵附录:初完整代码
注:代码来自《动手学深度学习》
%matplotlib inline
import d2lzh as d2l
from mxnet import nd
from mxnet.gluon import loss as gloss
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs = 784, 10
num_hiddens, num_hiddens2 = 256, 30
W1 = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens))
b1 = nd.zeros(num_hiddens)
W2 = nd.random.normal(scale=0.01, shape=(num_hiddens, num_hiddens2))
b2 = nd.zeros(num_hiddens2)
W3 = nd.random.normal(scale=0.01, shape=(num_hiddens2, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
def relu(X):
return nd.maximum(X, 0)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(nd.dot(X, W1) + b1)
H2 = relu(nd.dot(H, W2) + b2)
return nd.dot(H2, W3) + b3
loss = gloss.SoftmaxCrossEntropyLoss()
num_epochs, lr = 5, 0.5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
🚩 总结
折腾了挺久,后面感觉我想使用固定的初始参数,来方便观察和比较实验结果的想法,本身可能也不是很好。每次都从相同的地方开始,即使通过调整超参数,取得了优秀的训练效果,取得这个效果可能是 依赖于初始参数的(当然,训练的结果本身仍然是优秀的)。
如果又换到随机的初始参数下训练,大概率会取得更差而不是更好的训练效果。
继续加油!!!学习本身就是一个不断试错的过程。
在学习的过程中,也参考了一些好文章。它们不是都与我本次的问题直接相关,但我觉得对我整体上的理解是有帮助的。
- 独家 | 初学者的问题:在神经网络中应使用多少隐藏层/神经元?(附实例)
- 深层神经网络的权值初始化问题
- 常用的激活函数汇总-Sigmoid, tanh, relu, elu




