
大家好!我是保护小周ღ,本期为大家带来的是深度剖析数据在内存中的存储,不知道,大家学了这么久C语言,有没有想过一个问题,我们在程序设计中的数据是怎么在计算机中存储的?我们都知道 一个整型数据 int 在内存中占4个字节,一个char 类型占一个字节,包括float 、double、指针…… 那他们又是怎么被计算机读取的呢?接下来跟着博主在内存的视角看数据。

目录
一、计算机组成原理
1.1 一台完整的计算机由硬件和软件组成
1.2 计算机为什么采用二进制表示和存储信息
1.3 计算机的工作原理是“存储程序和程序控制”
1.4 总线
二、基本数据类型介绍
三、整型数据在内存中的存储
3.1 原码、反码、补码
3.2 进制转换
3.3 什么是大、小端存储?
3.4 程序深入理解
3.4.1 下面程序会得到怎样的结果
3.4.2 下面程序会得到怎样的结果
四、浮点型数据在内存中的存储
一、计算机组成原理
冯诺依曼领导的设计小组设计的计算机理论体系自1946年起一直沿用至今。
冯诺伊曼设计思想:

1.1 一台完整的计算机由硬件和软件组成,两者相辅相成,缺一不可。
硬件:构成计算机的物理实体。
软件:计算机工作所必须的程序、数据及相关文档的集合。软件又分为系统软件和应用软件。我们的操作系统就是系统软件,我们的各种app就是应用软件。
运算器(ALU):进行算数运算和逻辑运算
控制器(CU):控制各部件协调一致的工作
我们的CPU(中央处理器)其实主要就是运算器和控制器组成。
CPU:(Central Processing Unit,中央处理器),他是计算机的核心元件,CPU 生产厂商中比较著名的就是 Intel 和AMD 公司,想必大家都不陌生吧。
介绍CPU 的两种性能指标:
CPU的位和字长。位(bit)是计算机处理二进制数的基本单位,一个‘1’或者‘0’,就代表一位。字长就是CPU在指定单位时间内能一次处理的二进制位数,例如:32位的CPU 就能够在单位时间内处理字长位32位的二进制数据。
多核心:是指单芯片多处理器,可以理解为,一个CUP可以“同时”处理不同的程序(像我们开了qq,又可以开微信,还能听歌,就得益于这种技术),以前的CPU可一次只能运行一个程序。
存储器:用于存放程序数据的信息,分为内存和外存。
(1)内存:又称为内部存储器和主存储器,他是相对外存而言的,我们日常使用的程序,操作系统,游戏,各种app,其实都是放在外存(硬盘,U盘等)中的,但是使用他们必须要调入到内存中运行,只有内存可以和CPU直接进行数据交换,外部信息经内存进入CPU,我们能使用的是内存的RAM和高速缓存(Cache)。RAM既可以读也可以写,当计算机断电时,存储在其中的信息就会丢失,这也是为什么我们写完文档之后要保存的原因,保存之后其实就是数据由CPU控制经内存写入外存。读取的时候反过来。高速缓存的目的,是为了解决CPU处理数据的速度高于内存的读取速度,提升CPU的利用率,所以说,内存质量的好坏于容量大小会影响计算机的运行速度(玩游戏的同学应该有体会)。
(2)外存就是硬盘,U盘,光盘啥的嘛,即使断电也不会丢失信息,相对于内存价格便宜。
输入/输出设备,也就是我们口中的 I/O 设备,输入:用于接收用户输入的数据和程序,存入计算机。输出:就是反着来嘛,像我们的显示器,音箱啥的就是经典的输出设备,鼠标键盘就是输入设备。
那么硬盘属于什么设备呢?答案是 I/O 设备,因为他既可以输入数据,也可以输出数据,我们的读盘,写盘的操作嘛。
1.2 计算机为什么采用二进制表示和存储信息
最主要的原因:二进制数在物理上最容易实现,就像电路中可以用高、低电平来表示1和0,此时我们就可以用这些0和1组成的数据,来代表信息,数据是信息的载体,是信息的具体表现形势。其次是二进制进行算数、逻辑运算,运算规则简单。
1.3 计算机的工作原理是“存储程序和程序控制”
工作过程:将程序和数据通过输入设备输入计算机,并保存在存储器中,计算机执行程序时,按照程序的指令的逻辑,顺序的、自动的、连续的把指令依次取出来并执行,无须人为干涉。
1.4 总线
主板上的总线(Bus)是连接CPU 和计算机上各种器件的一组信号线,用来在各部件之间传递数据和信息。主板上的总线按功能可以分为三类:
控制总线(CB):用来发送CPU命令信号到存储器或 I/O设备的总线。
地址总线(AB):由CPU向存储器传送“地址”的是地址总线。
数据总线(DB):CPU、存储器和 I/O等设备之间数据传送的是数据总线。
经过上文,博主的计算机基础知识的讲解,相信大家应该对我们的计算机有了一个初步的了解,现在跟着博主,一起站在内存的角度看C语言。
二、基本数据类型介绍
基本的C语言数据类型,我们也掌握的许多。
C语言基本的数据类型(32位) :
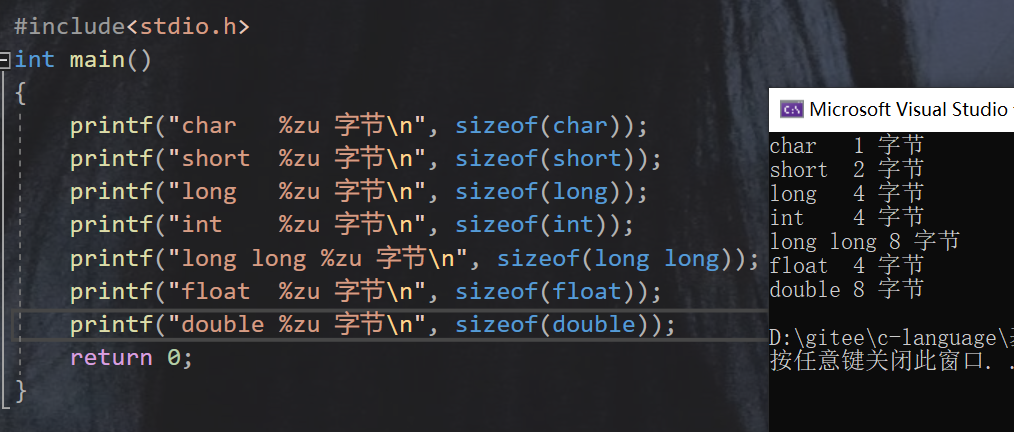
实际上整型数据还有,signed(有符号),unsigned(无符号)之分,例如:unsigned int ,后面讲。
数值中有正数和负数,但也有些数值只有正数。这就是我们有符号,和无符号的意义,两者之间的存储数据的范围不一样。
char 类型有三种之分:
char , signed char ,unsigned char ,char 其实就是后两种的一种,要么有符号,要么无符号,这个取决于编译器,VS 2019 char == unsigned char ;
其他的默认是有符号的, int == signed int ……

三、整型数据在内存中的存储
定义变量是要在内存中开辟空间的,开辟空间的大小是根据不同的类型而决定的。
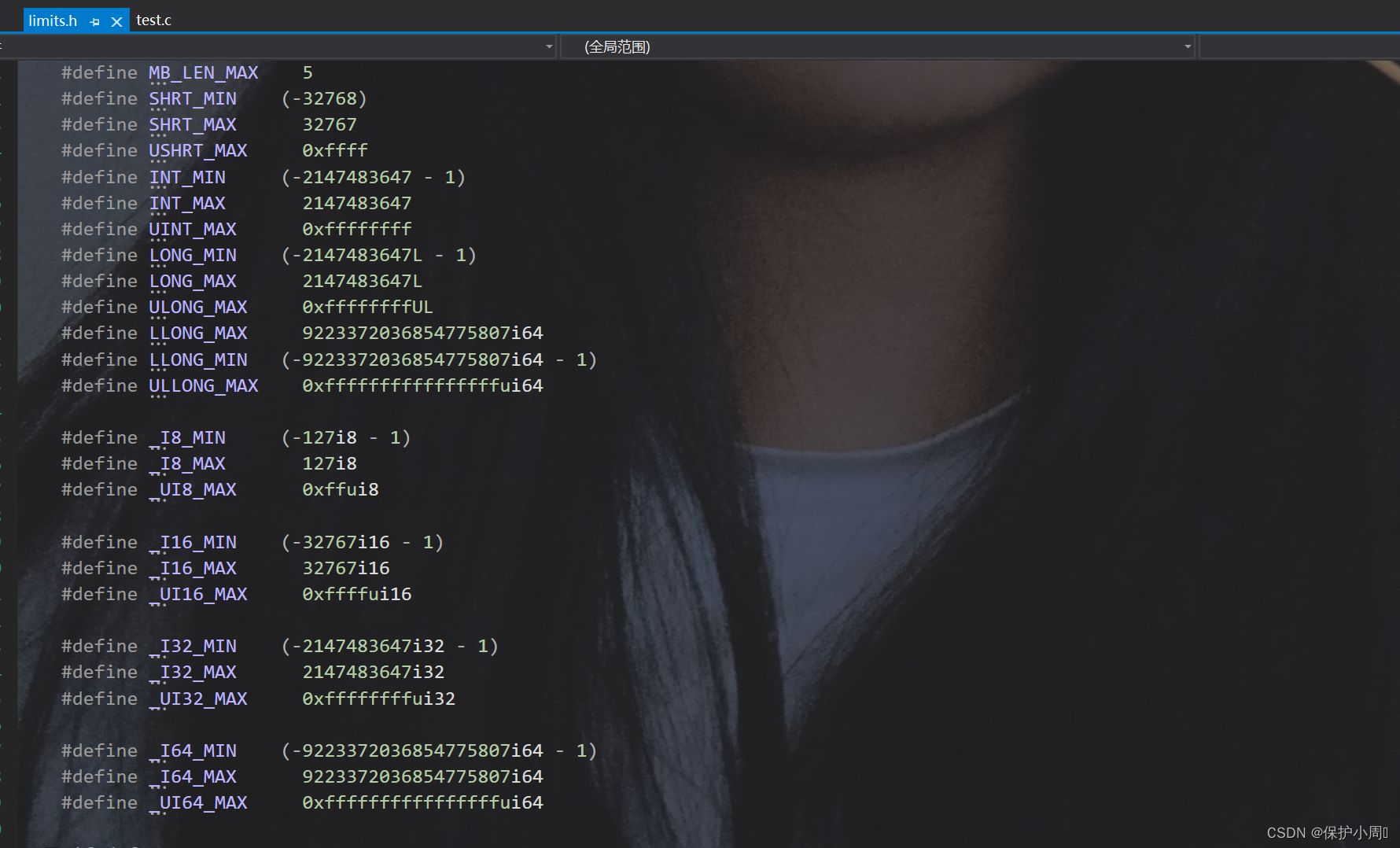
整型类型数据的取值范围限定的取值范围 Limits.h 文件中
3.1 原码、反码、补码
整型数据在计算机中的数据保存和运算都是以二进制的形势,但是不是直接使用数据的原码,而是数据的补码。也就是说数据的运算存储都是数据的补码进行的。


那么两个整型数据怎么进行运算的呢?
CPU—运算器,只有加法器,所以加法和减法都是统一用加法器运算而且是由补码的形势运算的。
如果 a=10,b=10;
那么 a - b= a + (-b) =10 +(-10)

补码到原码的方法(主要是负数)
计算机虽然存储运算的时候用补码,但显示数值的时候还是会用原码的形势显示出来
(1)采用逆运算,补码最后一位减1,符号位不变,数值位逐位取反,即可得到原码。
(2)补码符号位不变,数值位逐位取反,最后一位加1 ,即可得到原码。
char 型数据一般采用ASCLL码的形势存储, 一个ASCLL码占用存储空间一个字节,最高位固定为0,所以ASCLL码的取值范围为[0,127];
3.2 进制转换
那么是十进制数,如何转换为二进制数呢,最简单的办法,我们抄起计算器,但是我们还是要知道怎么算。
(1)将(57.345)十进制数,转换为二进制计算方法如下:
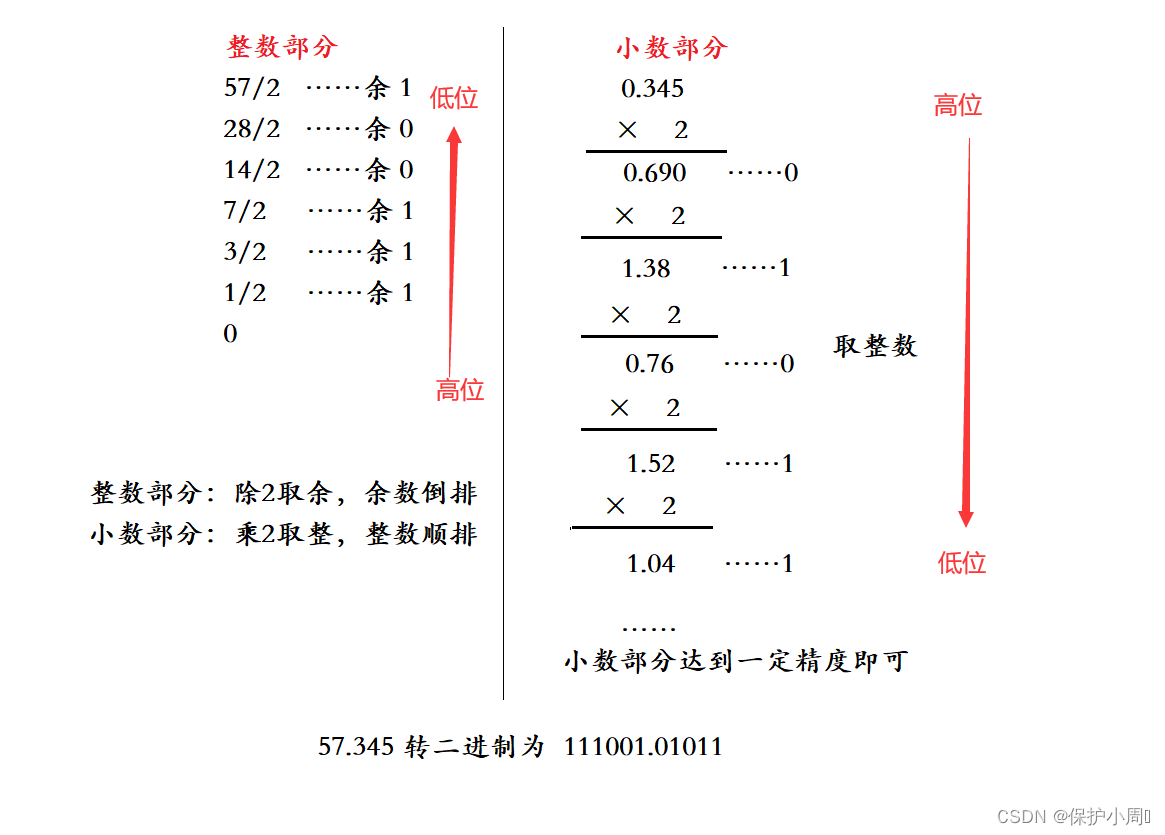
(2)如何将 111001.01011 转换为十进制呢?

1.从某进制转换成某进制,可以先,转换成 2进制数,在利用二进制按权展开。
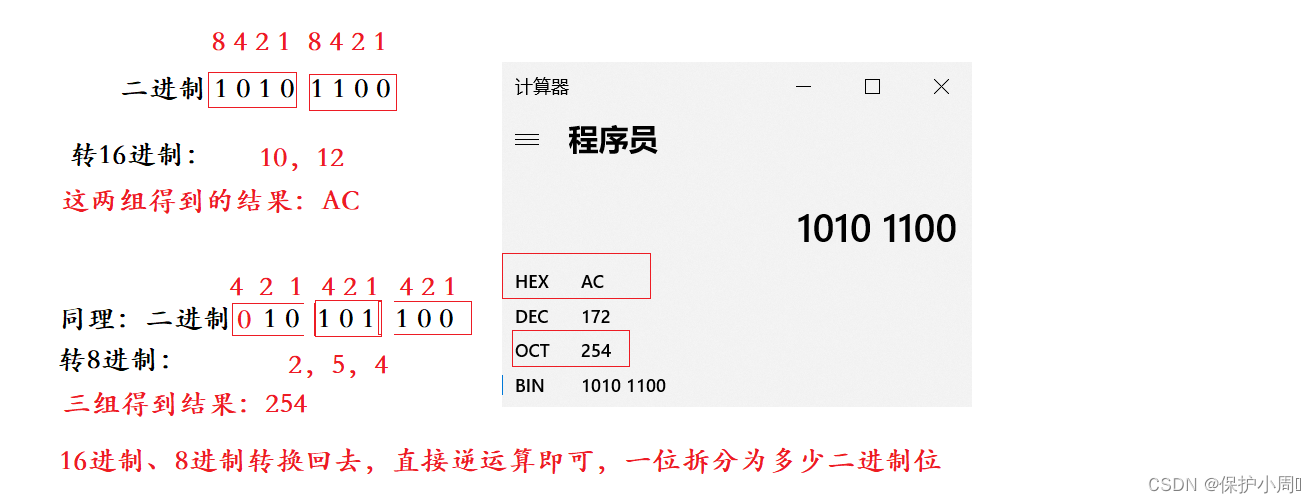
2.二进制转 16进制可以用 8 4 2 1码,因为1位16进制数最大是15,也就是F,刚好就是二进制4位全1 1111 这四个1的权重展开就是8 4 2 1,所以我们遇到一串二进制数,转换成16进制,就可以每四个二进制位一组(不够的补0),可以得到一位16进制数,注意从低位开始,小数部分也可。
3.八进制也是同样的道理,但是他的只能使用 4 2 1,最大为7,刚好就是三个二进制位 111 =7;
所以是三个二进制位一组。
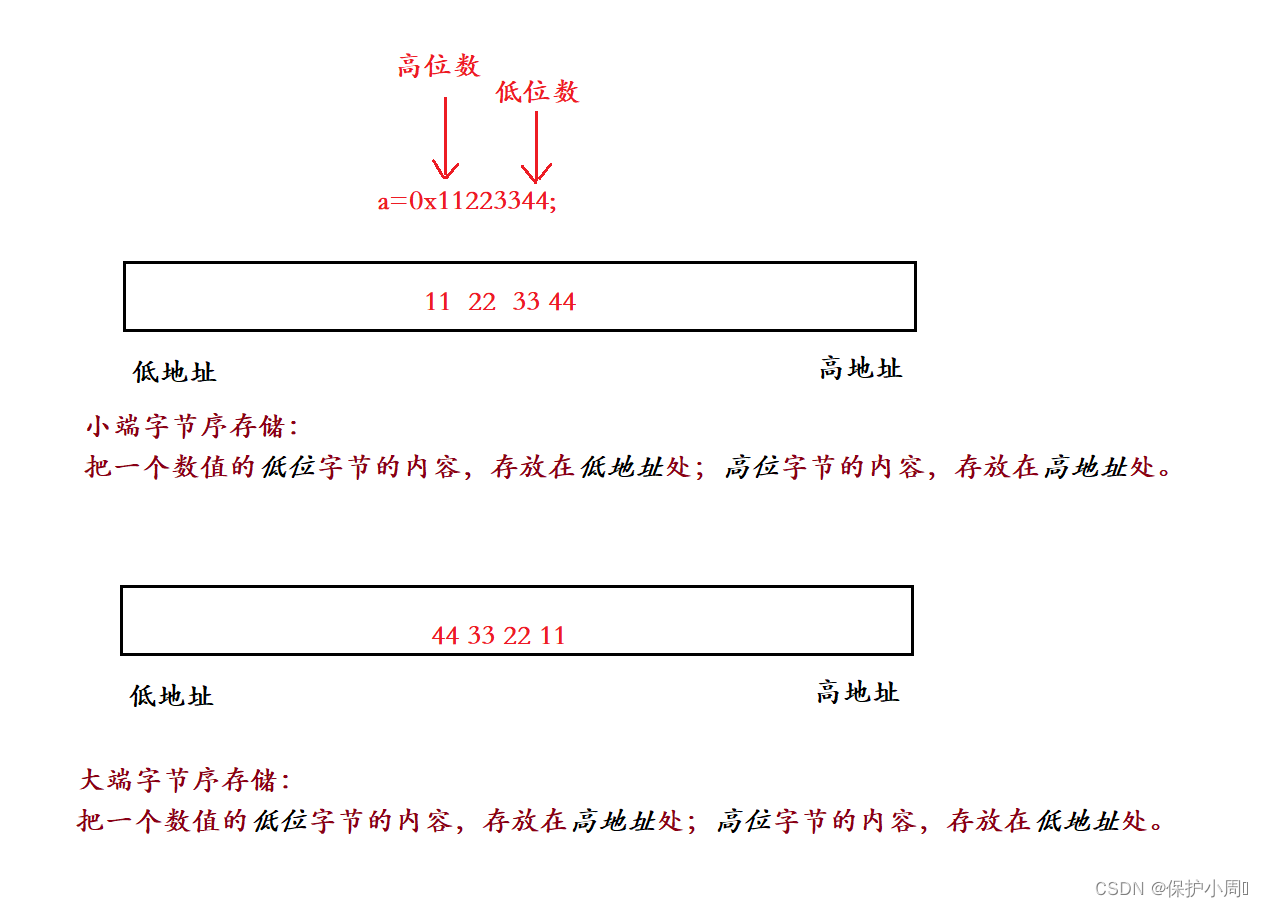
3.3 什么是大、小端存储?
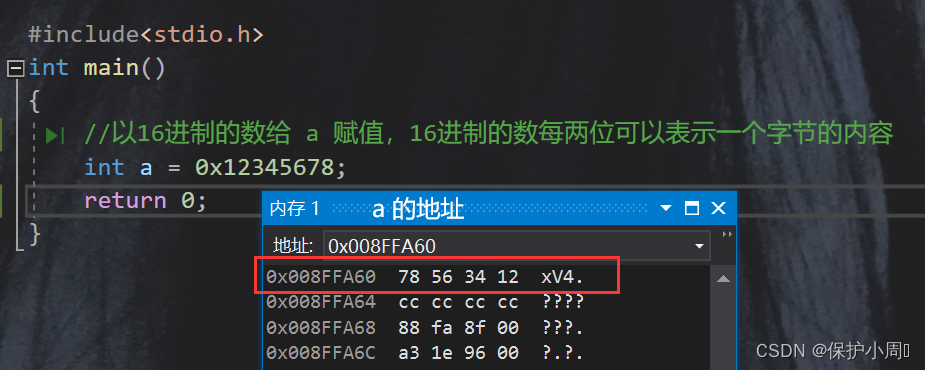
根据上图,我们发现,我们的值以字节为单位(我们的存储单元最基本的单位就是字节),在内存中是倒着存贮的,嘶~,好奇怪啊。
一个数值超过1个字节,要在内存中存储,那就有了存储顺序的问题。
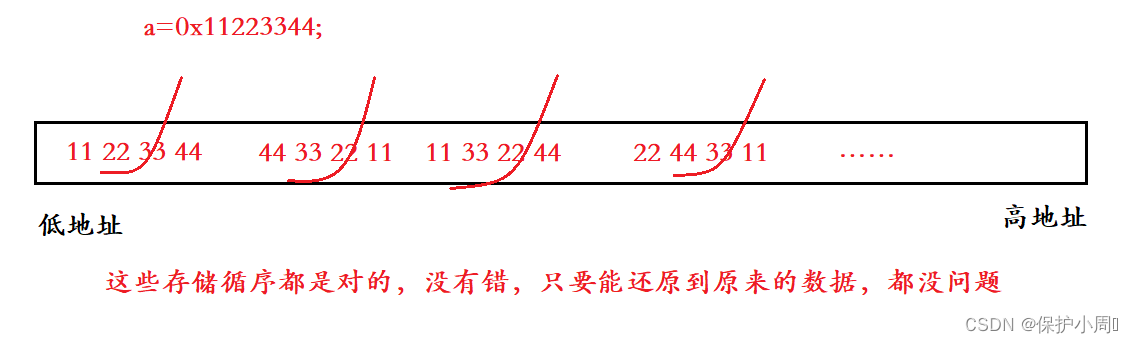
所以大小端存储更像是一种标准。不同的编译器有着不同得存储顺序,但是一般都是大端或者是小端存储。
博主用的是VS 2019 ,所以这个编译器是小端字节序存储。我们能不能用代码的形势来判断目前使用的编译器,是小端存储还是大端存储呢?
#include
int check_sys()
{
int i = 1;
char* pi = (char*)&i;//将整型空间强转为字符型,并交给字符型指针pi维持
return *pi;//只能访问一个字节的内容。
}
int main()
{
int ret = check_sys();//调用函数
if (ret == 1)
{
printf("小端序字节存储n");
}
else
{
printf("大端序字节存储n");
}
return 0;
}
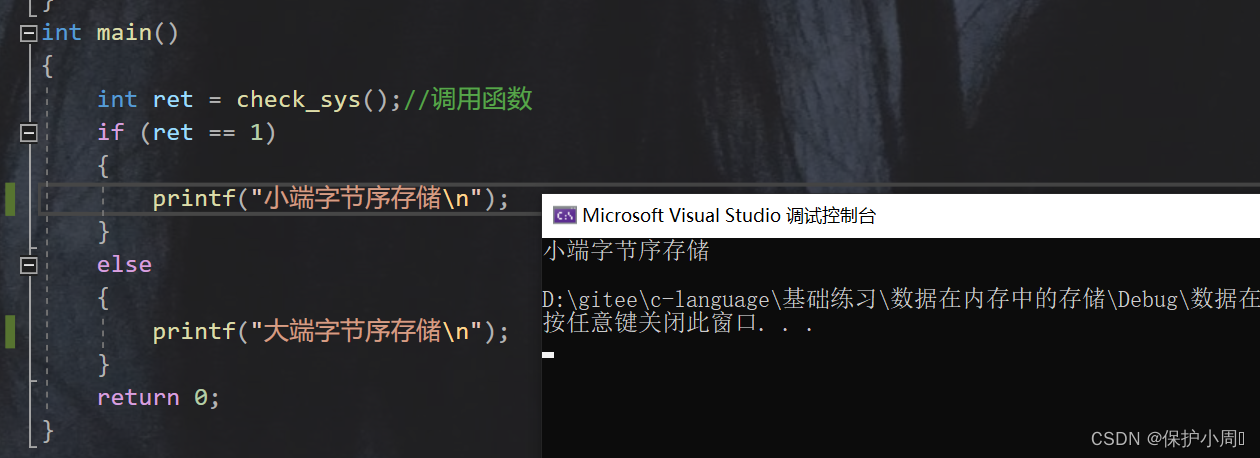
1.在 int 四个字节得整型空间里,只使用其中一个字节的内容存一个1;要么1在左边,要么1在右边。
2.我们把这个整型空间强转为字符型的指针维持,字符型指针只会访问一个字节的空间,所以根据字符型指针pi 解引用操作的得到的值即可判断是否是大端存储或者是小端存储。
3.字符型指针虽然在32位平台下有4个字节,但是他会根据自己的类型决定访问多少字节,所以 char* 的指针解引用操作只会访问一个字节的内容,如果是int * 的指针解引用可以访问4个字节的内容。
4.此时呢,字符型指针解引用操作访问一个字节的内容,如果访问到了1,表示小端存储,否则就是大端存储。
本题就是利用这个特性,巧妙地判断。
这是一道笔试题哦~
3.4 程序深入理解
3.4.1 下面程序会得到怎样的结果
#include
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%dnb=%dnc=%dn",a,b,c);
return 0;
}
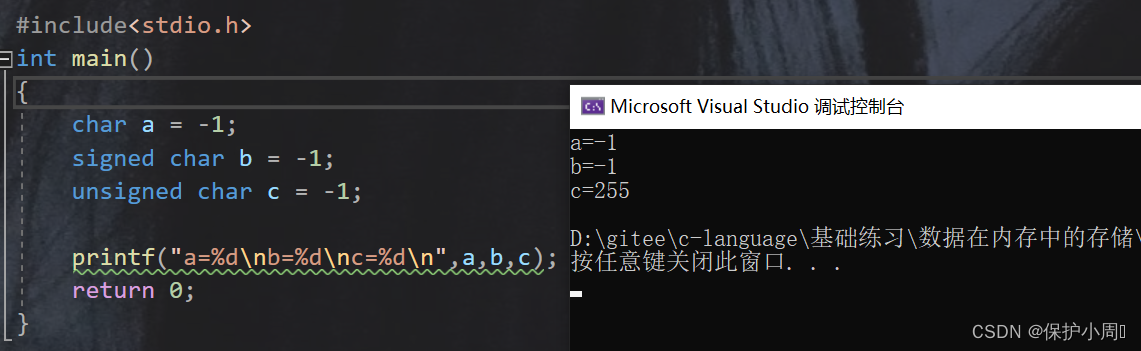
根据这一题,我们可以得到 3 个知识点:
1 . 原码,反码、补码之间的相互转换
2 . 截断:例如:高字节类型强转为低字节类型,就会发生截断,保留低位,舍去高位
3. 整型提升:一般用于不足整型的数据,有符号位根据符号位,高位补齐,无符号位,直接高位补0。
4. 一个字节的内容如果有符号位,数值位就只有7位有效,2^7-1=127,加入符号位,数据范围就是[-128,127]。
一个字节的内容如果无符号位,数值位,8位全部有效,2^8-1=255; 因为没有符号,所以数据取值范围[0,255]。
3.4.2 下面程序会得到怎样的结果
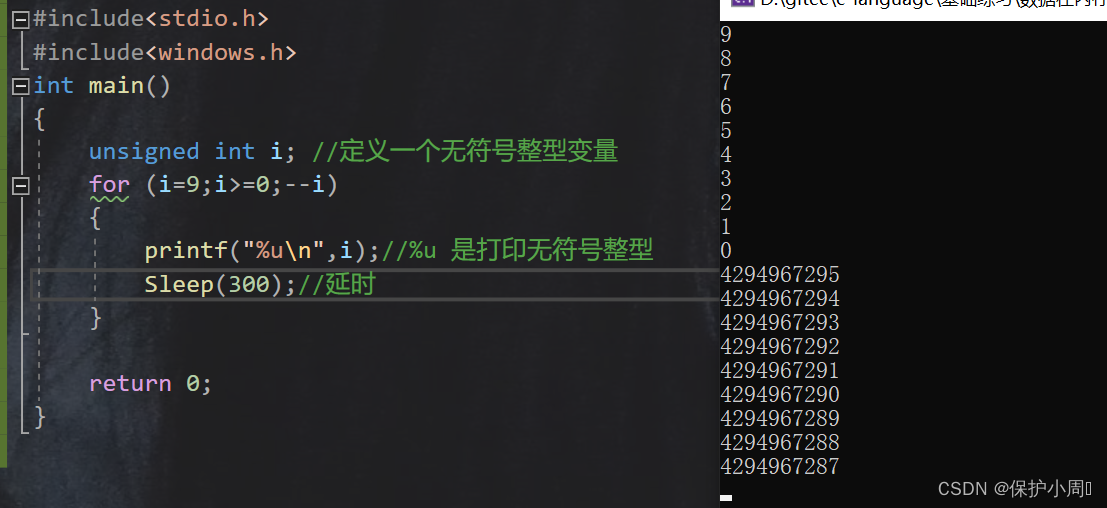
为什么程序会造成死循环?
因为,变量 i 是无符号整型数据,无符号整型数据的取值范围一定是 >=0,没有符号位,也就无法表示负数。所以,循环的结束条件为 >= 0,条件是恒成立的, 当 i 等于 -1 的时候,在内存中的补码是全 1,但是没有符号位,所以就代表是正数,正数的原码,反码,补码相同。所以 i 会是一个很大的数,再逐渐递减。
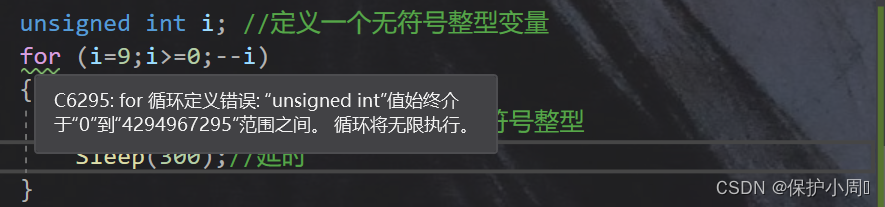
我们的编译器也会跟我们报错。
四、浮点型数据在内存中的存储
来到这里,就说明浮点型数据在内存中的存储规则跟整型数据的不一样。
跟着博主的节奏,来深度解剖浮点型数据的秘密。
浮点型类型数据的取值范围限定在 float.h
浮点数的类型啊,大致有 float ,double , long double 这几种。
那么浮点型的数据在内存中是怎么存储的呢?原码,反码,补码? NO!大NO特NO。

假设我们有一个浮点型数据 5.5,按照上图的表示方式,应该是怎么样的呢?

但是有些小数部分无法使用二进制数精确描述,需要不断的凑,比如说 0.3,你会发现无限循环了,不管怎么凑,都无法精确描述。我们能够用来存储小数的位数有限,所以就不得不舍弃一部分,取一个近似值,这就是浮点型数据精度丢失的原因。
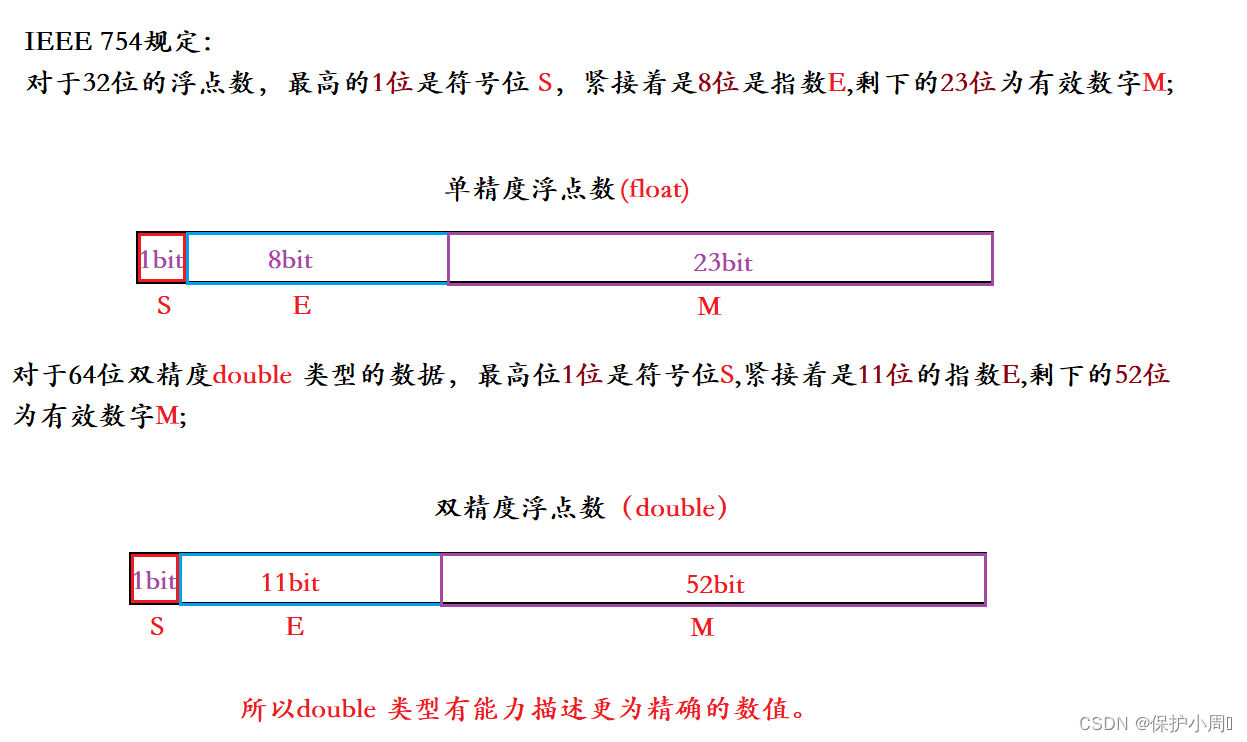
IEEE 754 对有效数字M和指数E,还有一些特别规定。
有效数 M:
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxx 的形式,其中xxxxx表示小数部分。在计算机内部保存M时,默认这个数的第一位总是1,所以就可以将其舍去,比保留小数部分(xxxxx),等到读取的时候再把1填回去还原,这样M 描述的精度就可以多存储一位。
指数 E(E为一个无符号整数):
科学计数法E是可能出现负数的,所以在存储的时候E的真实值必须加上一个取值范围的中间数,例如:单精度 (float)E 占8位,取值范围 [0,255],中间数是127,存储的是 E=E+127;
指数E从内存中取出分成三种情况:
E不全为0或不全为1
还原嘛,那就减去中间数(根据给E分配的位数),得到真实值。
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。
E全为0
浮点数的指数E等于1 - 中间数,即为真实值。
如果有效数字M全为0,表示±无穷大(正负取决于符号位S。
好了做个简单的了解即可,认真那就要找专业的师傅学习了,我是小学员。
至此,C语言的深度剖析数据在内存中的存储博主已经分享完了,希望对大家有所帮助,如有不妥之处欢迎批评指正。

本期收录于博主的专栏——C语言,适用于编程初学者,感兴趣的朋友们可以订阅,查看其它“C语言基础知识”。C语言_保护小周ღ的博客-CSDN博客
感谢每一个观看本篇文章的朋友,更多精彩敬请期待:保护小周ღ *★,°*:.☆( ̄▽ ̄)/$:*.°★*
文章存在借鉴,如有侵权请联系修改删除!




