一 模型介绍
yoloV5主要是用于目标的检测,针对检测过程中,一些关键点的输出也是至关重要,其中有yolo-face等目标检测+关键点模型,但是目前所有模型都是单分类+关键点的检测,为了设置多分类+关键点检测,这里我在使用单分类+关键点(yolov5-car-plate)的代码基础上进行修改,实现多分类+关键点检测。
二 模型修改
1 数据代码修改
数据代码修改主要是在 utils/plate_datasets.py 代码下
- 读取数据部分
首先修改 LoadImagesAndLabels 类中方法,添加426行代码
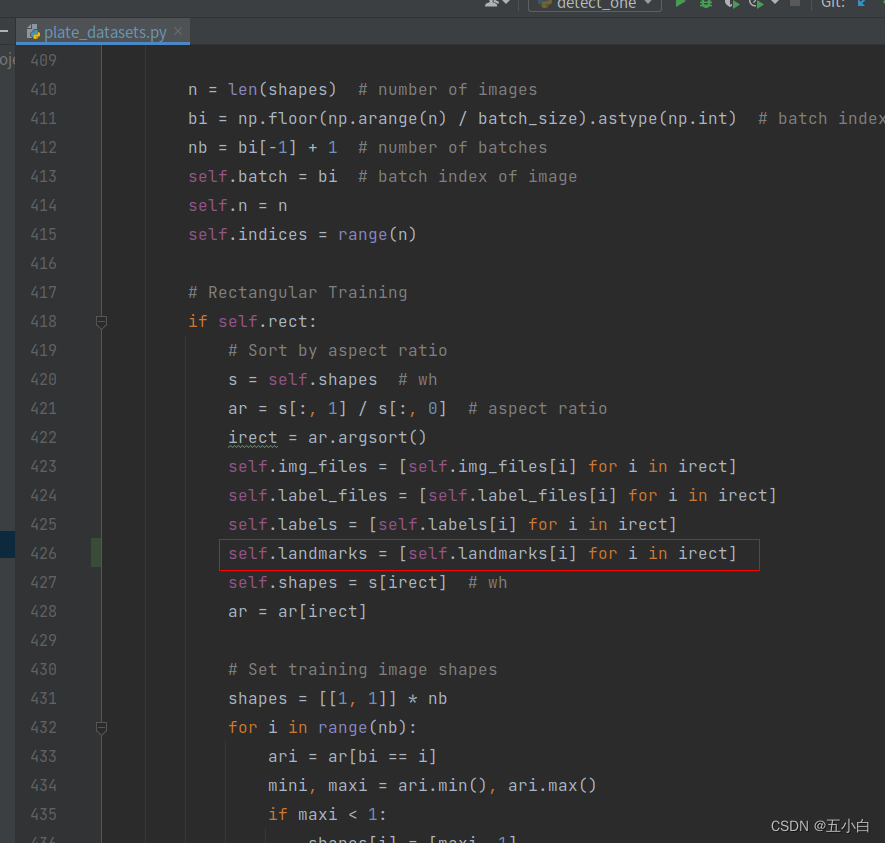
读取数据报错,做如下修改
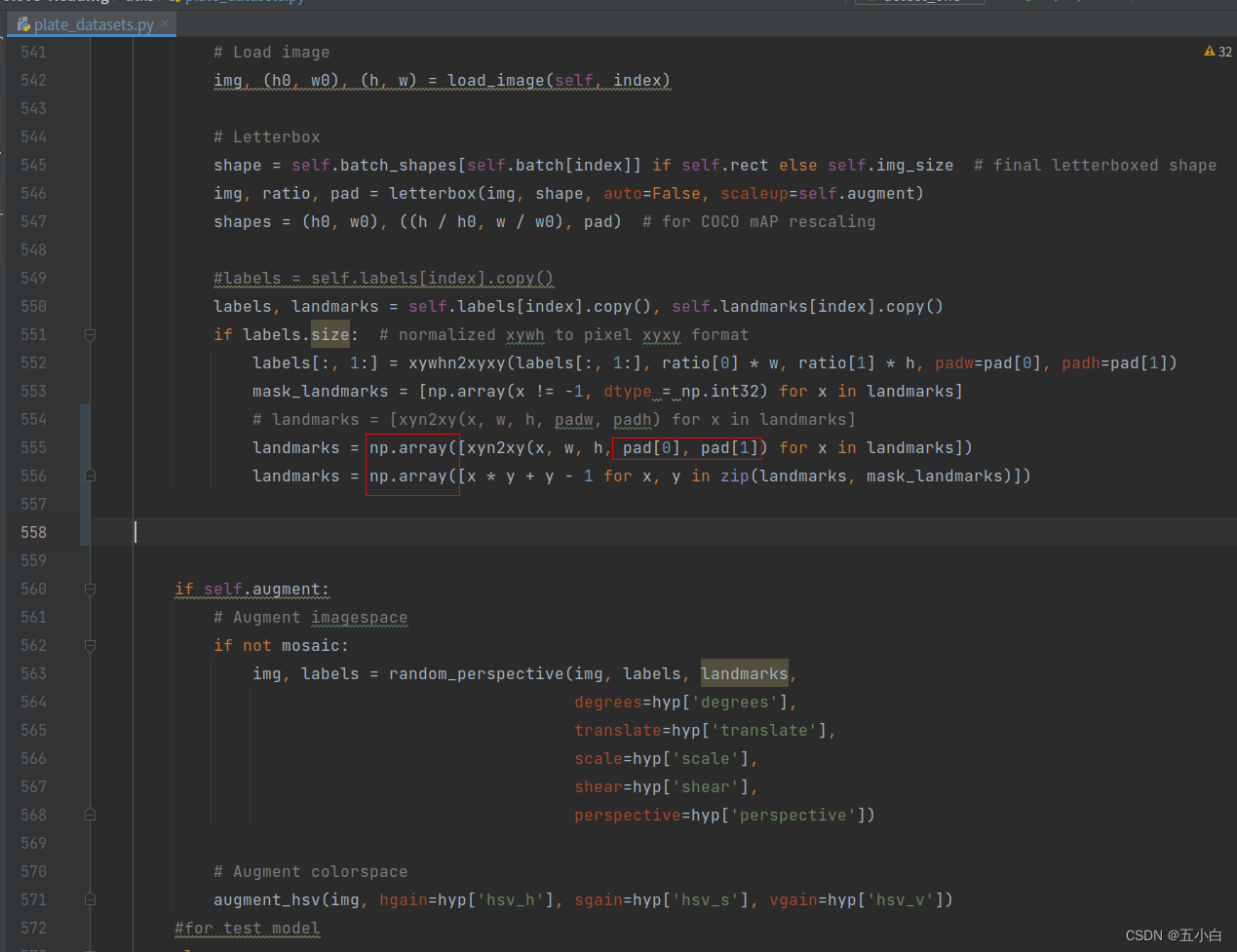
按照制作数据进行依次修改读取数据代码:
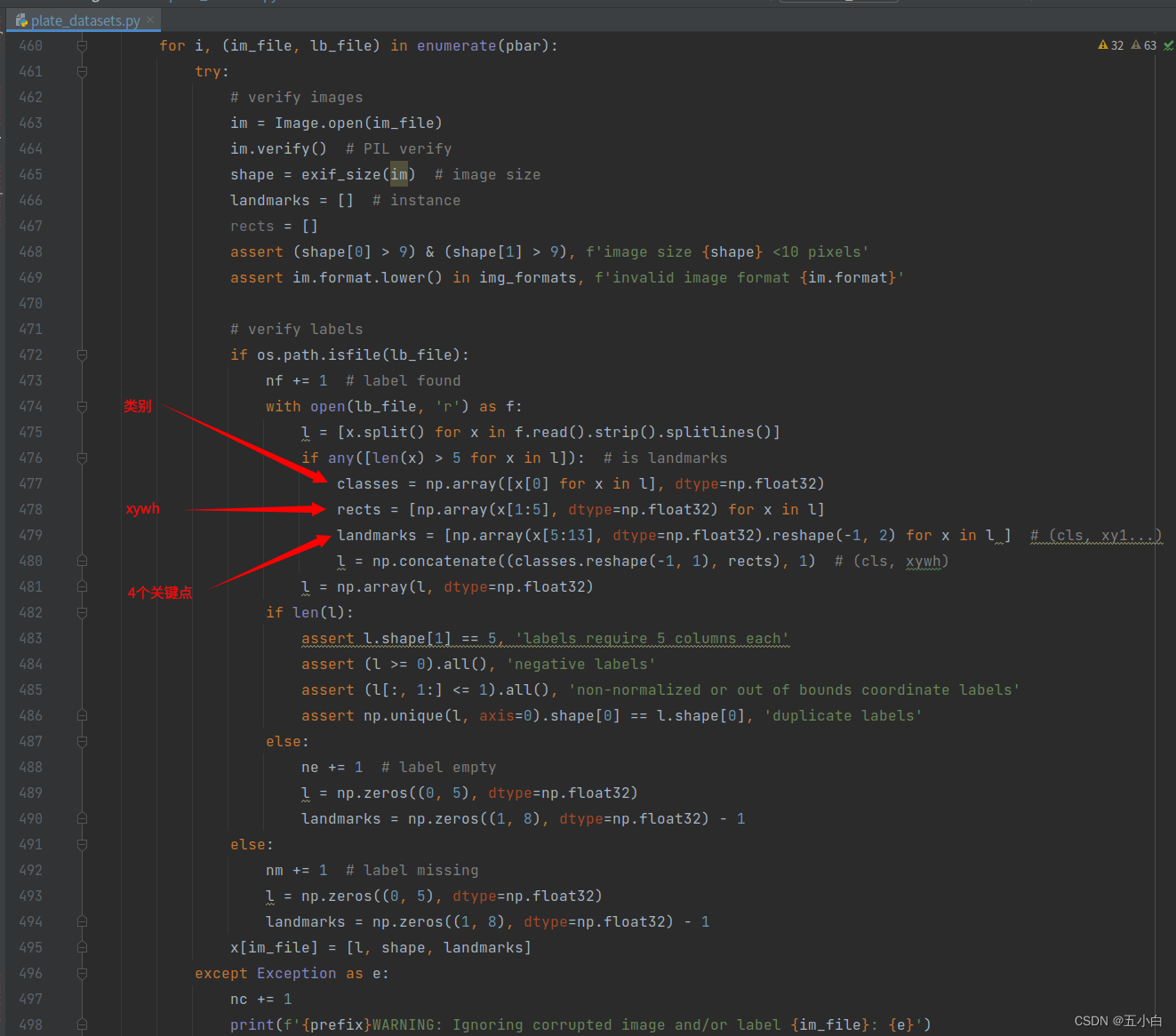
由于我自己的数据标签依次是 :
class,x , y ,w,h, x1 ,y1, x2, y2, x3, y3, x4, y4
所以这部分是没有修改的,这里根据自己的关键点数量进行修改。
数据示例:

-
数据增强-马赛克增强
我自己的数据和作者数据是一样的4个点,所以马赛克增强也是一样的,大家根据自己的点进行修改
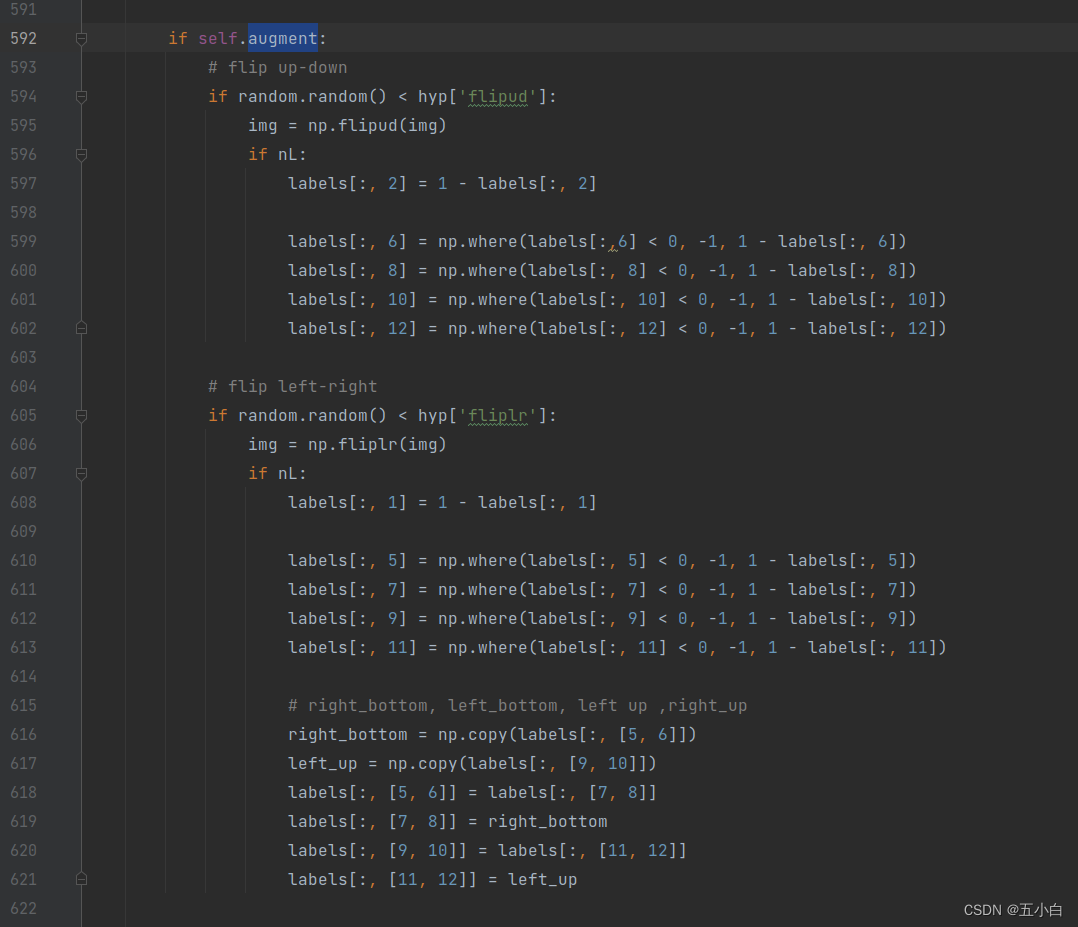
-
输入数据维度修改
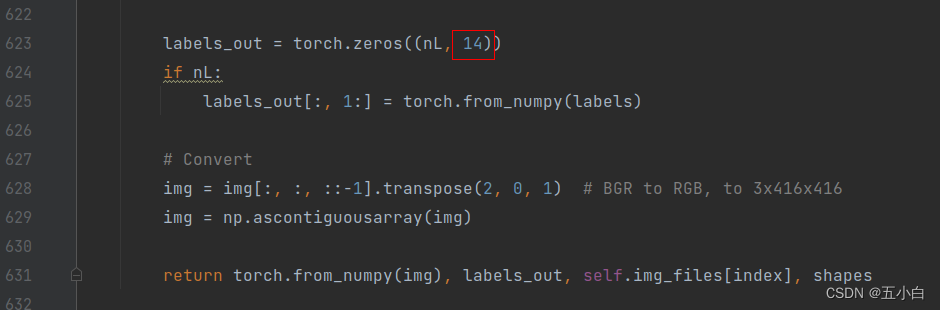
2 网络结构修改
网络结构代码位于 model/yolo_plate.py
-
修改总输出维度
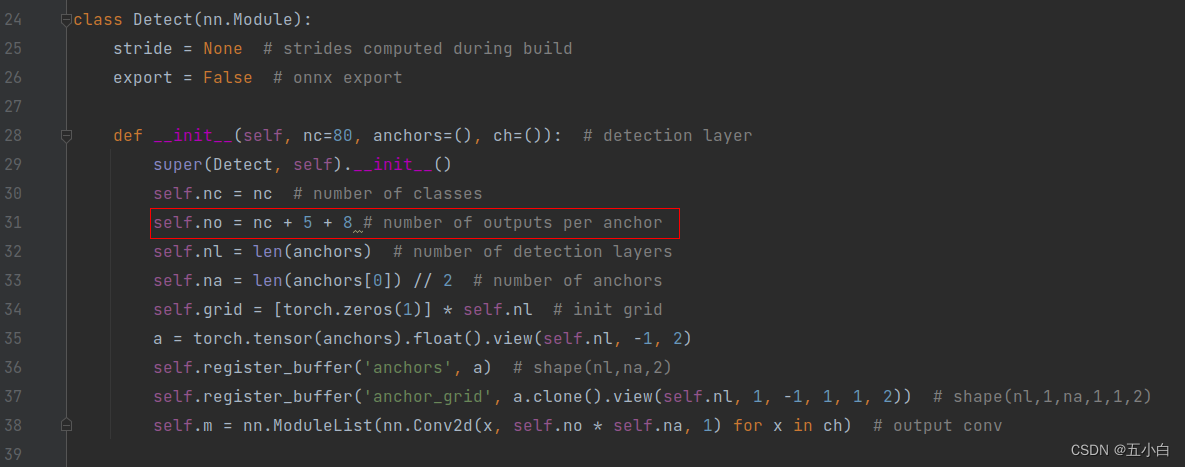
每个维度输出多4个点,也就是8个输出 -
网络结构修改
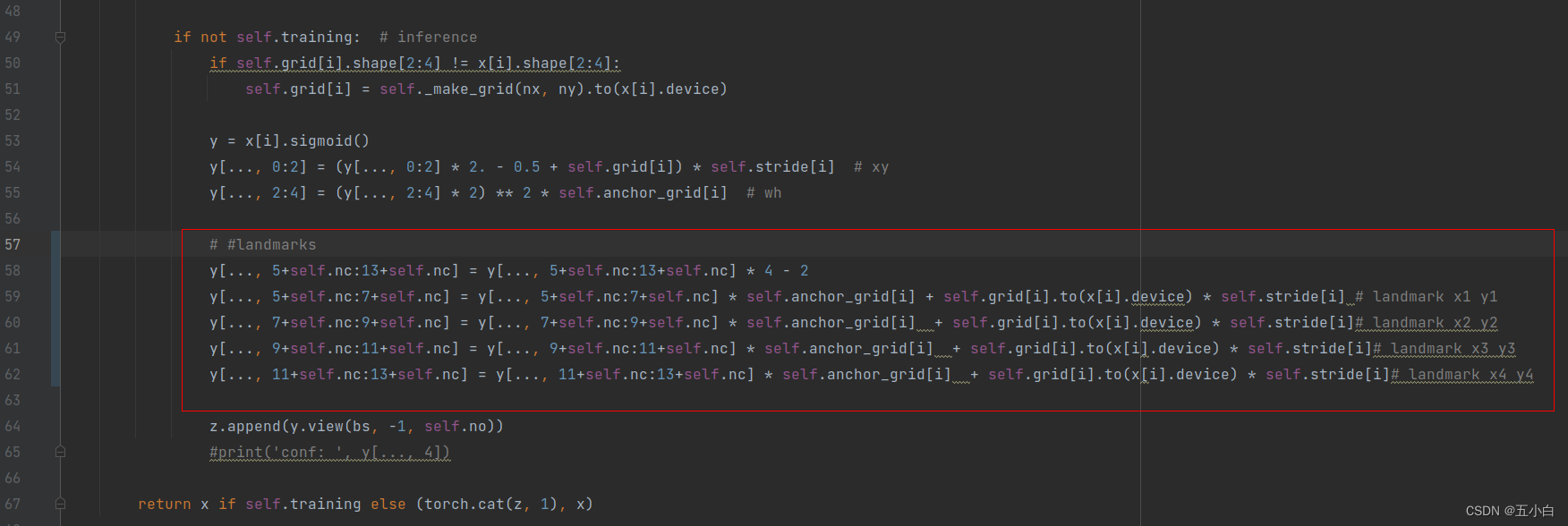
主要是确定点的输出位置,后面根据点的输出计算loss -
完整修改代码
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 + 8 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# #landmarks
y[..., 5+self.nc:13+self.nc] = y[..., 5+self.nc:13+self.nc] * 4 - 2
y[..., 5+self.nc:7+self.nc] = y[..., 5+self.nc:7+self.nc] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[i] # landmark x1 y1
y[..., 7+self.nc:9+self.nc] = y[..., 7+self.nc:9+self.nc] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[i]# landmark x2 y2
y[..., 9+self.nc:11+self.nc] = y[..., 9+self.nc:11+self.nc] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[i]# landmark x3 y3
y[..., 11+self.nc:13+self.nc] = y[..., 11+self.nc:13+self.nc] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[i]# landmark x4 y4
z.append(y.view(bs, -1, self.no))
#print('conf: ', y[..., 4])
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
3 loss代码修改
loss修改代码位于: utils/plate_loss.py
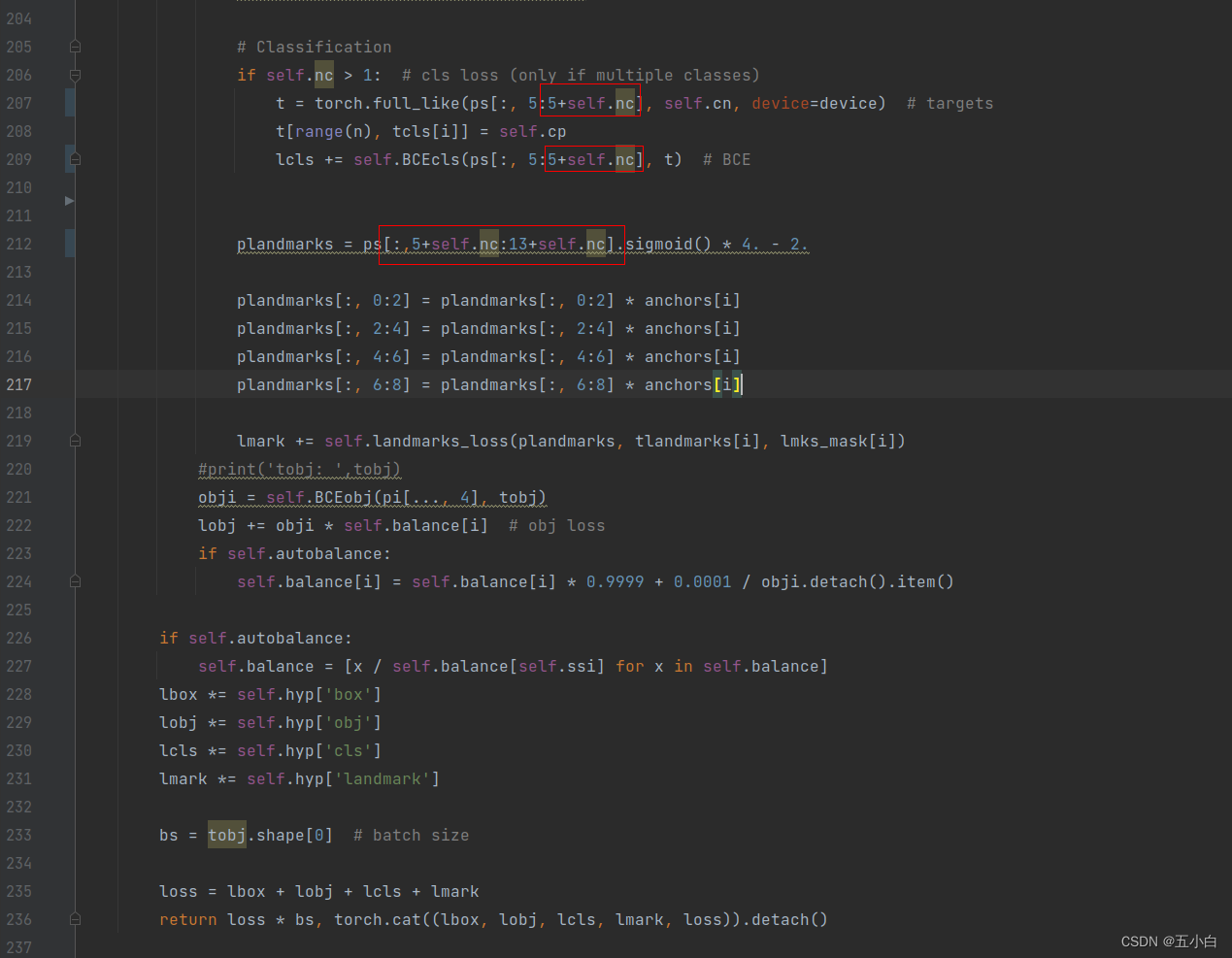
框出来的位置注意查看,代码修改主要是确定坐标点的位置,然后将坐标点进行loss计算,进行反向传播。
# 修改后的__call__代码块 :
def __call__(self, p, targets): # predictions, targets, model
device = targets.device
lcls, lbox, lobj, lmark = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors, tlandmarks, lmks_mask = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
#print('pi: ', pi.shape)
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
#print('tobj: ',tobj[b, a, gj, gi] )
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:5+self.nc], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:5+self.nc], t) # BCE
plandmarks = ps[:,5+self.nc:13+self.nc].sigmoid() * 4. - 2.
plandmarks[:, 0:2] = plandmarks[:, 0:2] * anchors[i]
plandmarks[:, 2:4] = plandmarks[:, 2:4] * anchors[i]
plandmarks[:, 4:6] = plandmarks[:, 4:6] * anchors[i]
plandmarks[:, 6:8] = plandmarks[:, 6:8] * anchors[i]
lmark += self.landmarks_loss(plandmarks, tlandmarks[i], lmks_mask[i])
#print('tobj: ',tobj)
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
lmark *= self.hyp['landmark']
bs = tobj.shape[0] # batch size
loss = lbox + lobj + lcls + lmark
return loss * bs, torch.cat((lbox, lobj, lcls, lmark, loss)).detach()
三 注意事项
1 训练问题,原代码没有修改val的代码,所以val的过程是错误的。
增加 non_max_suppression_landmark 方法修改val过程中nms计算
# 新建non_max_suppression_landmark 方法, 注意阅读代码后半部分文字。
def non_max_suppression_landmark(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=True, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
nc = prediction.shape[2] - 13 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
#print('xc: ', prediction[..., 4] )
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, nc +14 ), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 13), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + nc + 13] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:5+nc] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, landmarks, cls)
if multi_label:
i, j = (x[:, 5:5+nc] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], x[i, 5:13+nc], j[:, None].float()), 1) # 5+nc:12+nc
else: # best class only
conf, j = x[:, 5:5+nc].max(1, keepdim=True)
x = torch.cat((box, conf, x[:, 5:13+nc], j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)




