文章目录
系列目录与传送门
一、半加器与全加器
1.1、半加器
1.2、全加器
二、多bit加法(以4bit为例)
2.1、串行(行波)进位加法器(RCA)
2.2、超前进位加法器(Carry-Lookahead Adder,CLA)
三、进位链CARRY4
3.1、端口
3.2、内部组成
3.3、推断
3.4、测试实例
系列目录与传送门
《从底层结构开始学习FPGA》目录与传送门
一、半加器与全加器
FPGA底层的CARRY4本质上就是用来实现最基本的加、减法运算的,在了解CARRY4之前,我们需要对1bit以及多bit的二进制加法及其FPGA实现做一个了解。
1bit的二进制加法可以分为两类:无底层进位的半加器与有底层进位的全加器。减法运算本质上仍是一种加法运算,在二进制电路中采用加上负数的补码实现。
1.1、半加器
半加器电路是指对两个输入数据位相加,输出一个结果位和进位,没有进位输入的加法器电路。
半加器有两个1位2进制数输入,输出1个进位、1个结果位。真值表如下:
| A | B | Carry | Sum |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 |
从真值表,我们可以推断出其实现:
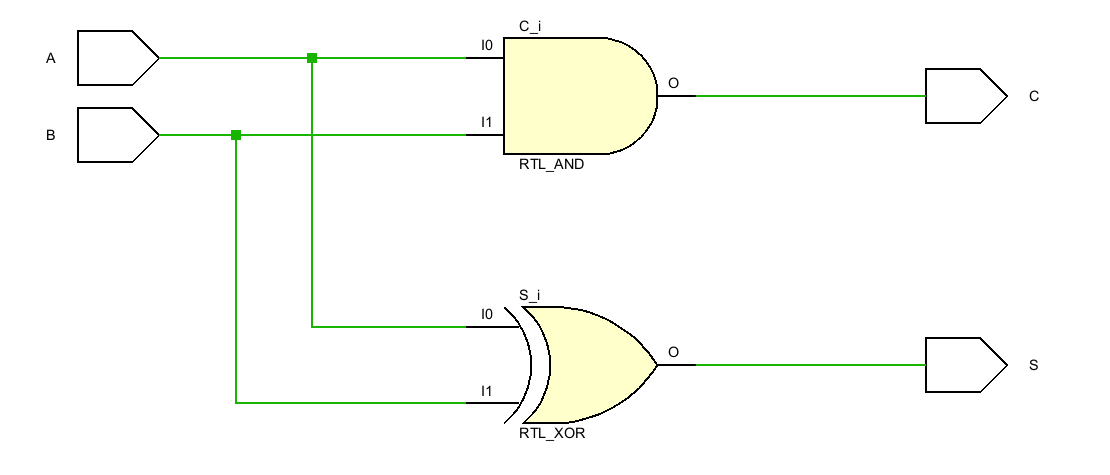
- 结果 S = A ^ B;
- 进位 C = AB;
映射到电路就是一个2输入异或门加一个2输入与门:
1.2、全加器
全加器是在半加器的基础上的升级版,除了加数和被加数加和外还要加上前上一级传进来的进位信号。全加器真值表为:
| A | B | Cin | Cout | Sum |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 |
从真值表,我们可以推断出其实现:
- 结果 S= A ^ B ^ Cin;
- 进位 C = (A&B) | (Cin & (A^B) ;
映射到电路的实现:
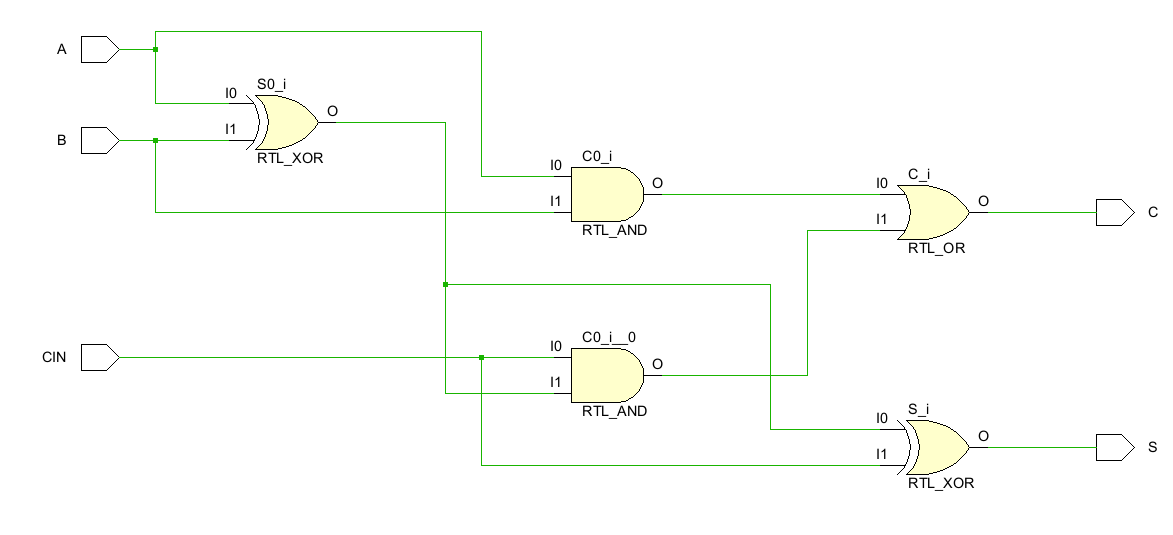
比半加器要复杂一些,构成为2个异或门+2个与门+1个或门。
二、多bit加法(以4bit为例)
有了单个bit的二进制加法电路(全加器)后,我们就可以通过级联来实现多bit的二进制加法了,但是多个全加器如何级联则是一个需要考虑的问题。
2.1、串行(行波)进位加法器(RCA)
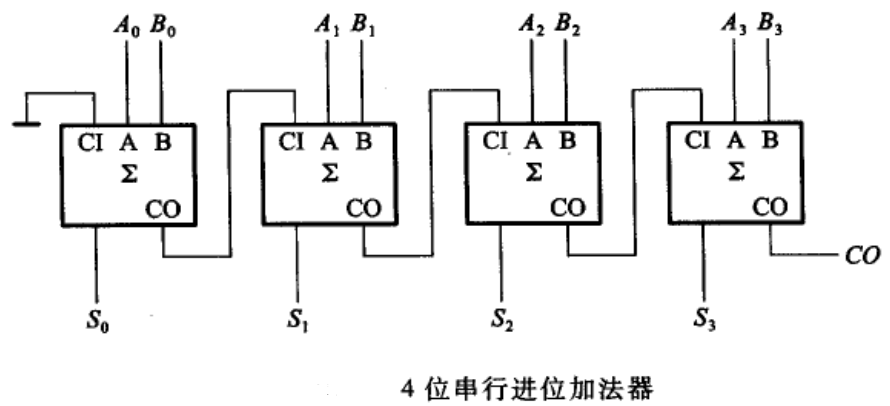
进行两个4bit的二进制数相加,就要用到4个全加器。那么在进行加法运算时,首先准备好的是1号全加器的3个input。而2、3、4号全加器的Cin全部来自前一个全加器的Cout,只有等到1号全加器运算完毕,2、3、4号全加器才能依次进行进位运算,最终得到结果。 这样进位输出,像波浪一样,依次从低位到高位传递, 最终产生结果的加法器,也因此得名为行波进位加法器(Ripple-Carry Adder,RCA)。
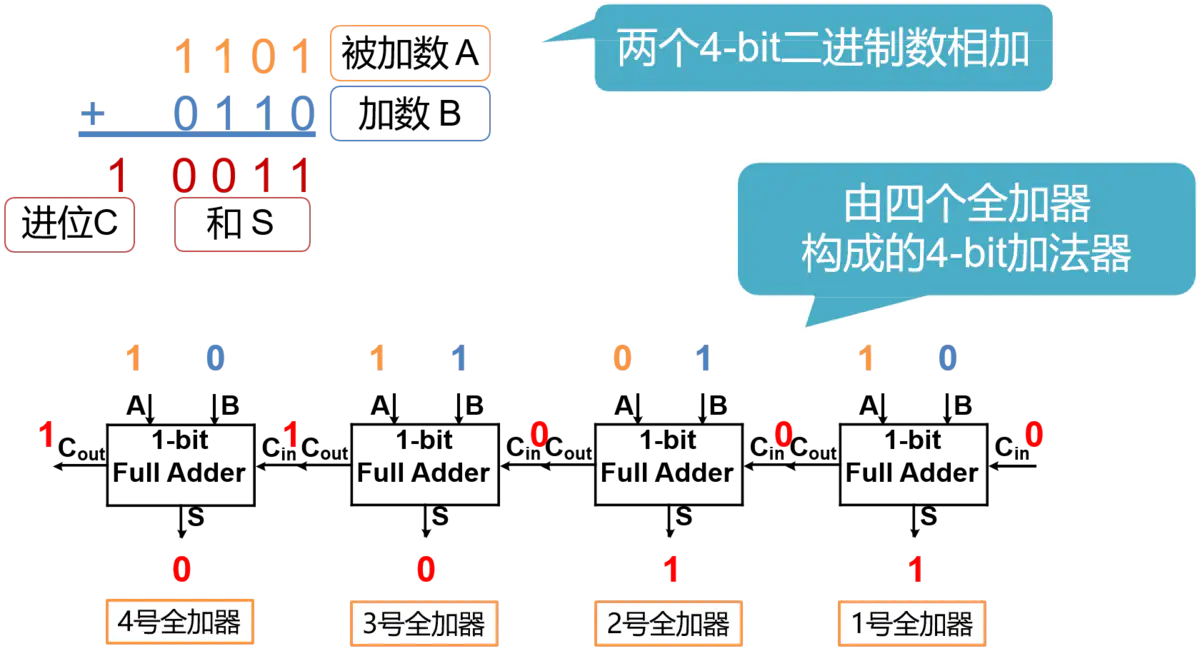
RCA的优点是电路布局简单,设计方便, 我们只要设计好了全加器,连接起来就构成了多位的加法器。 但是缺点也很明显,也就是高位的运算必须等待低位的运算完成, 这样造成了整个加法器的延迟时间很长。将4bit的RCA内部结构全部打开,就得到了如图所示的4-bit RCA的门电路图。要对一个电路的性能进行分析,我们就要找出其中的最长路径。 也就是找出所有的从输入到输出的电路连接中,经过的门数最多的那一条,也称为关键路径。
我们来做一个简单的分析, 对于最低位的全加器,它在A、B和Cin都已经准备好。其实,输入信号进入到这块电路之后,在连接线上传递需要花时间。 称为线延迟,而经过这样的门,也需要花时间,称为门延迟。
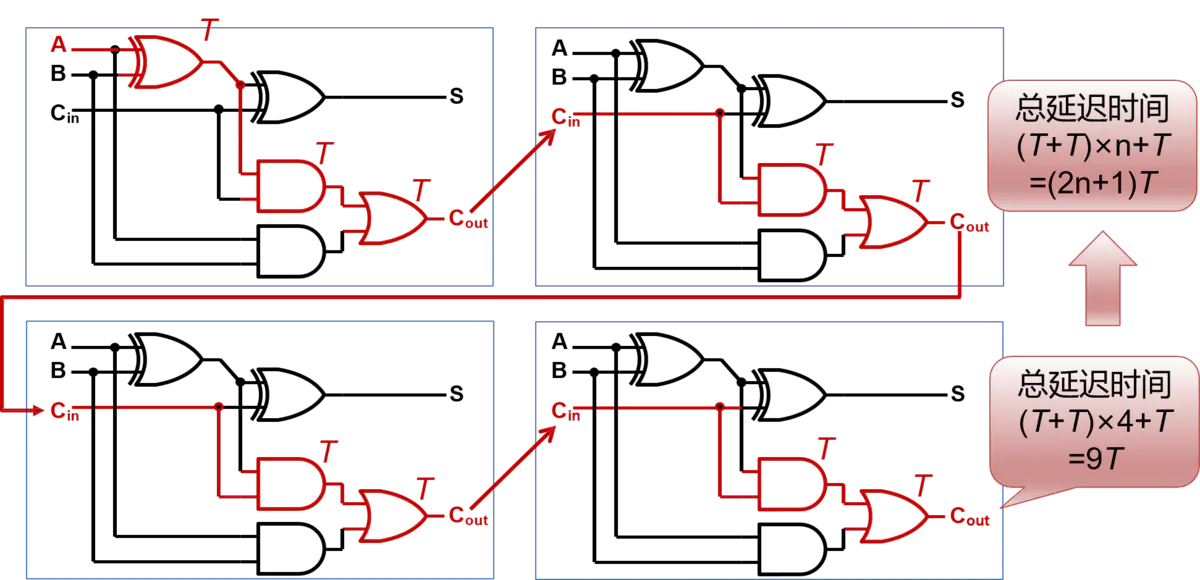
对于第一个全加器,它的最长路径,是红色线标记的那条。
那么,假设经过一个门电路的延迟时间为T,那么经过4个全加器所需要的总延迟时间就是:2T x 4 + T(第一个全加器产生3个T) = 9T。所以推出,经过n个全加器所产生的总延迟时间为2T x n + T = (2n+1)T。从此可以看出来RCA电路的最大问题就是组合逻辑延迟太高。
2.2、超前进位加法器(Carry-Lookahead Adder,CLA)
用前一个全加器的参数来表示后面的进位输出(Cout),即:
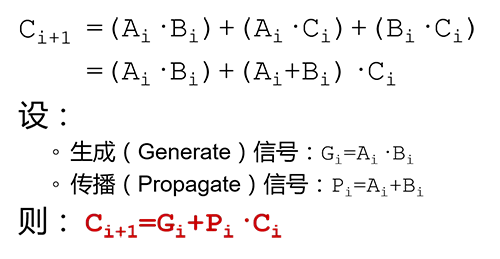
由此来表示4个全加器的进位输出为:

最终需要得到的是C4,经过换算,C4=G3+P3·G2+P3·P2·G1+P3·P2·P1·G0+P3·P2·P1·P0·C0,而这些参数,全部已知!并不需要前一个全加器运算输出,就可以提前计算进位输出, 用这样的方法实现了加法器就被称为超前进位加法器(Carry-Lookahead Adder,CLA)。
重新绘制CLA的布线方式:
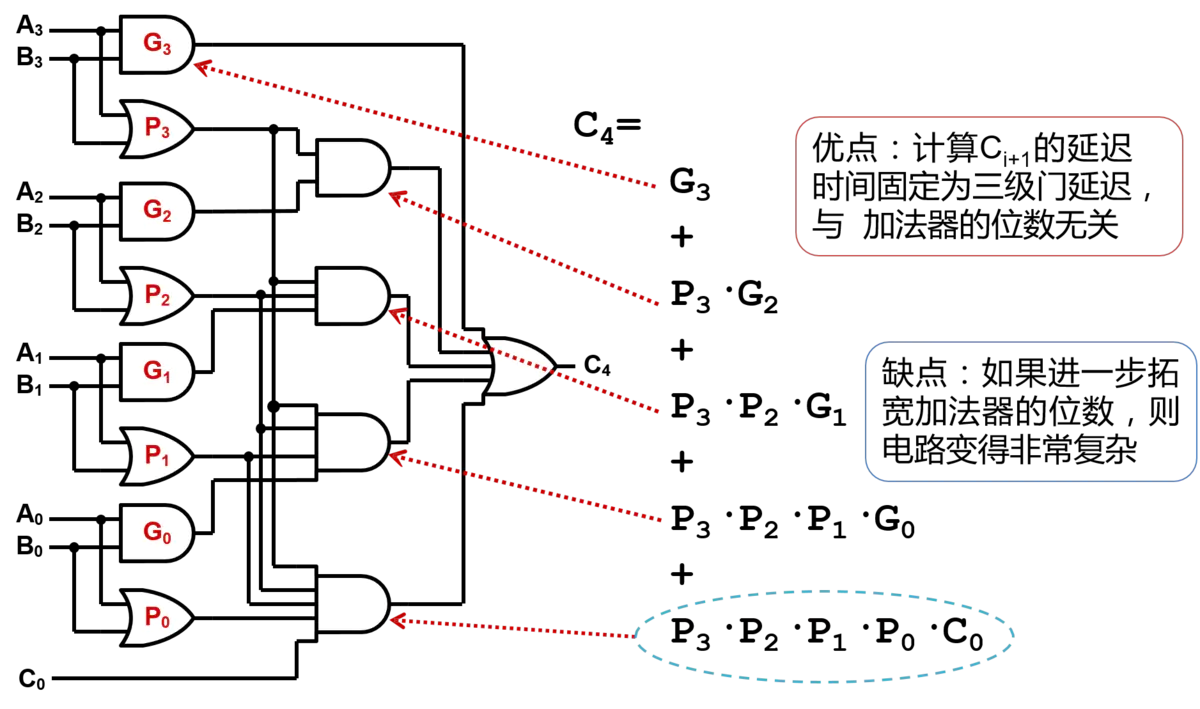
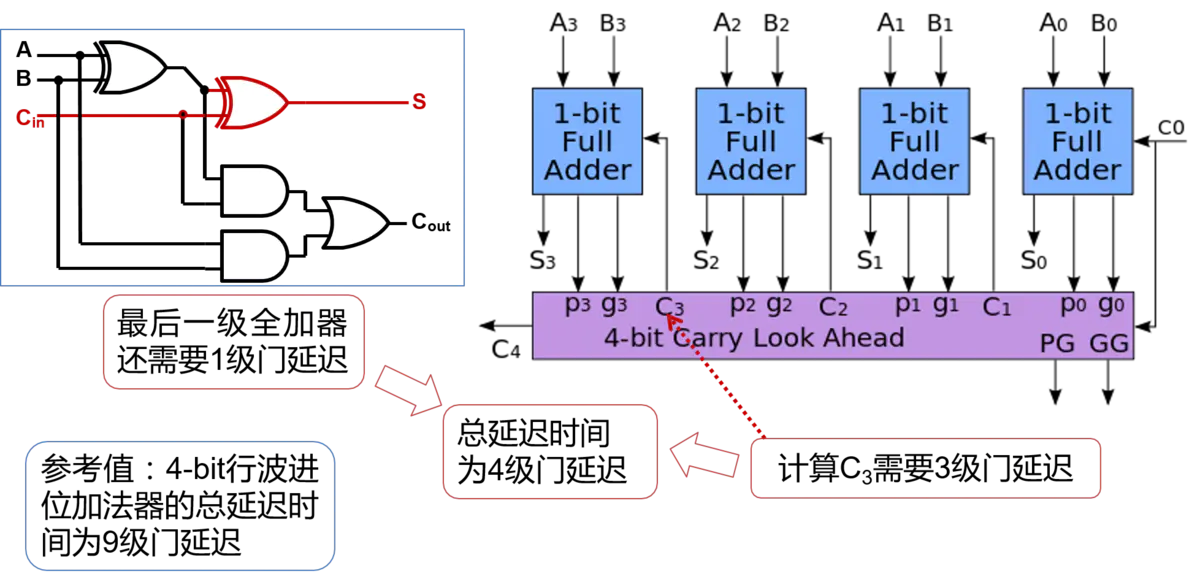
CLA的方式获得了较短的组合逻辑延迟,但是电路的面积却大了非常的多,这就是FPGA设计中非常经典的“面积换时间”。
同时需要注意的是,上面的门电路实现仅仅是求得C4,而如果要同时求C3 C2 C1的话,电路面积还会增大许多。
所以在FPGA内部会是使用CLA这种方式来实现加法器吗?答案是也不是。
三、进位链CARRY4
Xilinx FPGA底层的加法器(进位链)CARRY4是一种超前进位的加法器,但是为了面积与普适性其实现原理与上述的CLA电路还是有一点区别。
每个SLICE中都有1个(每个CLB则有2个)CARRY4用来实现进位逻辑,不同的进位链可级联以形成更宽的加/减逻辑:
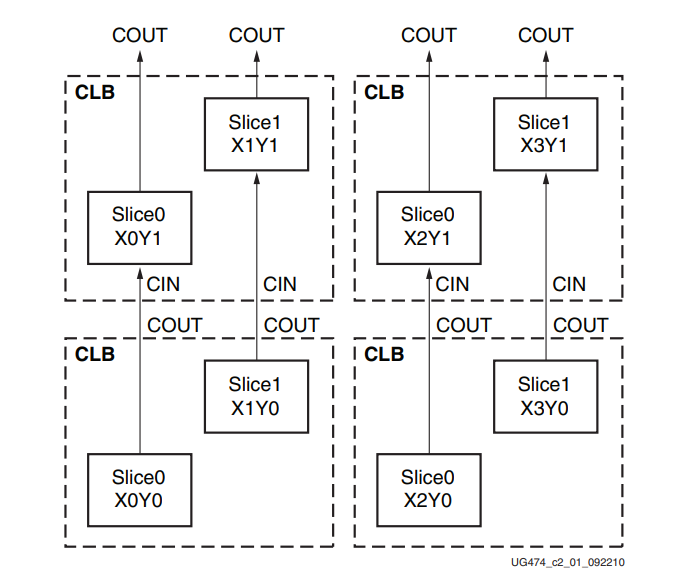
3.1、端口
先来看下CARRY的整体构成及其端口:
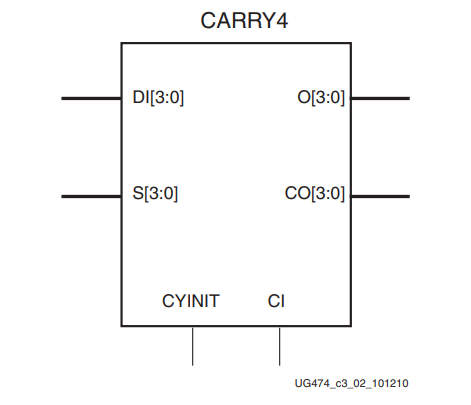
端口含义:
- CI:是上一个 CARRY4 的进位输出,位宽为1;可级联构成更大的加法逻辑
- CYINT:是进位的初始化值,位宽为1;0为加法,1为减法
- DI:是数据的输入(可以是两个加数的任意一个,至于为什么后面再解释),位宽为4;
- SI:是两个加数的异或结果,位宽为4;
- O:是加法结果输出,位宽为4;
- CO:是进位输出,位宽为4;(这里的进位代表每一位加法的进位,比如CO0代表最低位的加法进位,而CO3则代表最高位的加法进位,这样就可以同样实现小于4bit的加减法)
3.2、内部组成
仅仅只看端口无法理解CARRY4是如何实现进位算法的,接下来看下内部的具体实现:
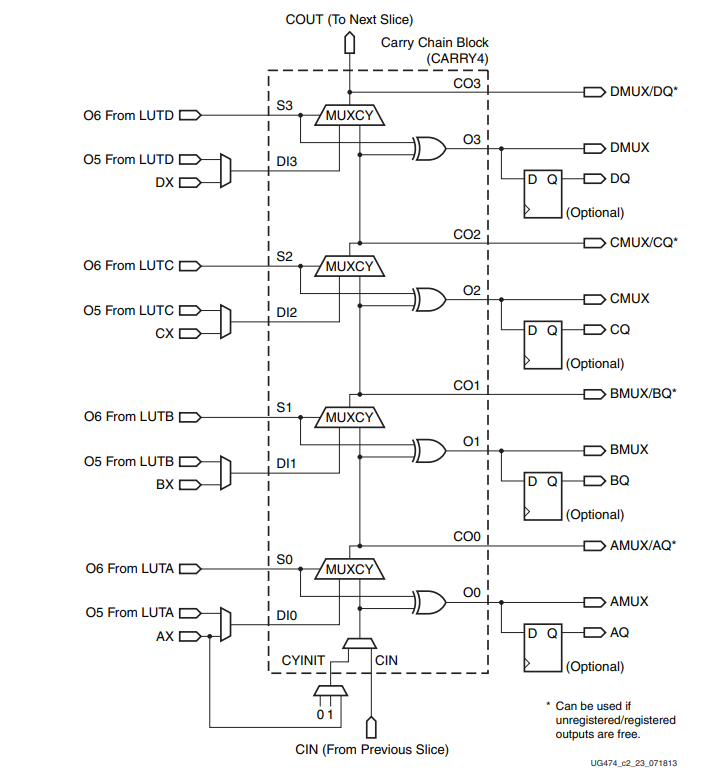
从上图可以看到,实际上CARRY4是分为相同的4个部分的,每个部分都用MUX2加异或门来实现进位逻辑。
这里需要说明的是,上述MUX2的实现逻辑均为:S = 0,结果为左侧输入; S = 1,结果为则右侧输入。
一步一步来看:
(一:O0、CO0)
最底层的结果O0等于S0异或CIN,S0则为两个加数的异或,也就是O0 = A0 ^ B0^ CIN。
若S0 = 0,则意味着两个加数相等,即00或11,此时O0的结果与CIN一致。若S0 = 1,则意味着两个加数不相等,即01或10,此时O0的结果与CIN相反。
当S0 = 0,则意味着两个加数相等,即00或11,此时MUX2选择DI0作为进位CO0的结果。若DI0为0,则意味着A0,B0,CO0都为0;若DI0为1,则意味着A0,B0,CO0都为1;
当S0 = 1,则意味着两个加数不相等,即01或10,此时MUX2选择CIN作为进位CO0的结果。若CIN为0,则意味着A0,B0,CIN为100,此时不需要进位,与CIN相等;若CIN为1,则意味着A0,B0,CIN为101,此时需要进位,仍与CIN相等;
省略(O1、CO1),(O2、CO2)的推断过程······
(四:O3、CO3)
结果O3等于S3异或CO2,S3则为两个加数的异或,也就是O3 = A3 ^ B3 ^ CO2。
若S3 = 0,则意味着两个加数相等,即00或11,此时O3的结果与CO2一致。
若S3 = 1,则意味着两个加数不相等,即01或10,此时O3的结果与CO2相反。
当S3 = 0,则意味着两个加数相等,即00或11,此时MUX2选择DI3作为进位CO3的结果。若DI3为0,则意味着A3,B3,CO3都为0;若DI3为1,则意味着A3,B3,CO3都为1;
当S3 = 1,则意味着两个加数不相等,即01或10,此时MUX2选择CO2作为进位CO3的结果。若CO2为0,则意味着A3,B3,CO2为100,此时不需要进位,与CO2相等;若CO2为1,则意味着A3,B3,CO2为101,此时需要进位,仍与CO2相等;
这样的结构看起来很像行波进位加法器RCA,最高层的进位需要从最底层一步步往上传递,实则不然。
可以举例,假如两个加数的最高位A3,B3为00或11,即S3=0时,此时的CO3直接等于DI3(因为00+0不进位和11+1要进位),也就是A3或者说B3(相等的),此时就不需要从下一层传递进位信号过来参与运算,这一情况出现的概率为50%。而另外50%的情况A3,B3不相等,即01或10(S3=1)时,此时的CO3取决于CO2(因为10或01+1进位;+0则不进位)。在次高位到最低位的情况均与上述一致。
也就是说只有在最极端的情况下,才需要在每一位考虑来自下一级的进位(如1010+0101,也就是每一位的两个加数均不一致),此时的进位组合逻辑是可能存在的最长组合逻辑路径。但是这种架构和上述的超前进位加法器比起来,其面积减少了非常多,仅使用了4个MUX2 + 4个XOR门,且这8个门电路均位于CLB的同一个SLICE里边,不同与传统的门电路的延迟,其线延迟可以控制得非常小。
3.3、推断
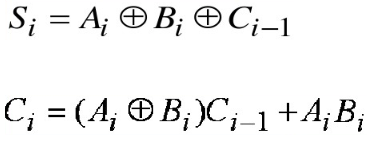
为什么说其本质还是超前进位加法器,我们可以从其逻辑式入手进行推断:
对于CARRY4,S=a ^ b端口D可以任选a、b输入当中的一个,如选择b
输出端:那么O端即表示输出端:O = S ^ cin = a ^ b ^ cin
进位端:
CO=(a^b)'b +(a^b)cin //多路复用器:y=s’b+scin
=(a’b+ab’)‘b+(a^b)cin
=(a’b)’(ab’)‘b+(a^b)cin
=(a+b’)(a’+b)b+(a^b)cin
=(ab+b’b)(a’+b)+(a^b)cin
=ab(a’+b)+(a^b)cin
=(a^b)cin+ab
假设有十进制的4bit数 4 + 8 =12,则二进制为 0100 + 1000 = 1100,用CARRY4的端口:
- 异或S = A ^ B = 0100 ^ 1000 = 1100
- 进位:CO0 = DI0 = B0 = 0;CO1 = DI1 = B1 = 0;CO2 = CO1 = 0;CO3= CO2 = 0,所以进位CO= 0000,与实际相符
- 位结果:O0 = S0 ^ CIN = 0 ^ 0=0;O1 = S1 ^ CO0 = 0 ^ 0=0;O2 = S2 ^ CO1 = 1 ^ 0=1;O3 = S3 ^ CO2 = 1 ^ 0=1;所以位结果O = 1100,也与实际相符
3.4、测试实例
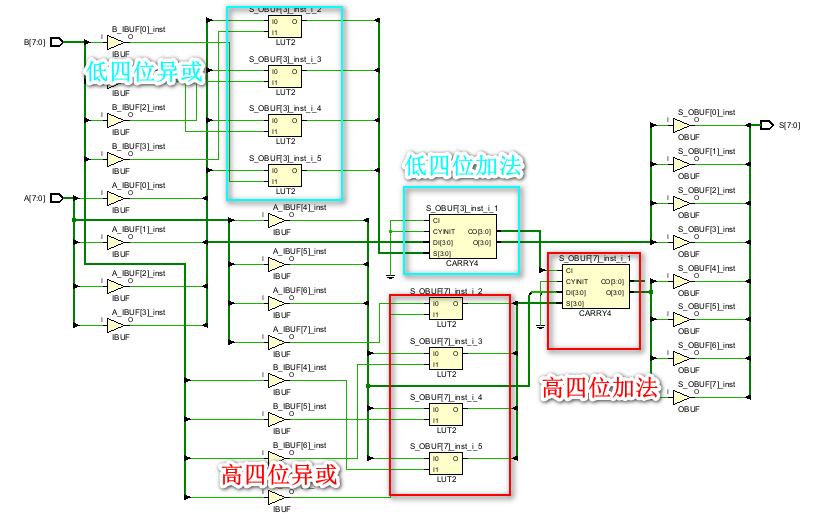
接下来写个简单的实例测试一下(2个8位数相加):
module test(
input [7:0] A,
input [7:0] B,
output [7:0] S
);
assign S = A + B;
endmodule 由于是8bit的加法,所以其综合结果是2个CARRY4级联组成。
`timescale 1ns / 1ns
module tb_test();
reg [7:0] A;
reg [7:0] B;
wire [7:0] S;
//例化test模块
test test_inst(
.A (A),
.B (B),
.S (S)
);
initial begin
A =0;
B =0;
#200 $finish;
end
always #10 begin
A ={$random }%64;
B ={$random }%64;
end
endmodule测试结果不说了,一目了然:





