强化学习
强化学习入门这一篇就够了万字长文带你明明白白学习强化学习...强化学习入门这一篇就够了
- 强化学习
- 前言
- 一、概率统计知识回顾
- 1.1 随机变量和观测值
- 1.2 概率密度函数
- 1.3 期望
- 1.4 随机抽样
- 二、强化学习的专业术语
- 2.1 State and action
- 2.2 policy-策略
- 2.3 reward
- 2.4 状态转移
- 2.5 agent与环境交互
- 三、强化学习的随机性
- 3.1 动作随机
- 3.2 状态转移的随机性
- 四、如何让AI自动打游戏?
- 五、强化学习基本概念
- 5.1 Return
- 5.2 价值函数
- 5.3 Q~π~
- 5.4 State-value function-状态价值函数
- 六、两种价值函数
- 6.1 动作价值函数
- 6.2 状态价值函数V~π~
- 七、强化学习如何打游戏
- 7.1 OpenAI Gym
- 总结
前言
学习强化学习,需要懂一些关于概率统计的知识,还要注意的就是基本概念的理解和记忆。 说明一下:这是我的一个学习笔记,课程链接如下:最易懂的强化学习课程
公众号:AI那些事

一、概率统计知识回顾
1.1 随机变量和观测值
随机变量:它是一个未知的量,它的值取决于一个随机事件的结果。
例如:我抛一个硬币,正面朝上为0,反面朝上记为1.抛硬币是一个随机事件,抛硬币的结果就记为随机变量X,随机变量有两种取值,有可能为0,也有可能为1,抛硬币之前我是不知道X是什么的,但是我知道这个随机事件的概率,P(X=0)=0.5,P(X=1)=0.5。
通常我们使用小写字母表示观测值,概率统计中普遍使用大小写来区分随机变量和它的观测值。
上面说到观测值?那么观测值是什么意思呢?当随机事件结束,会观测到硬币的哪一面朝上,这个观测值就记为字母x,x只是一个数而已没有随机性,举个例子我扔了4次硬币就得到了4个观测值,如下图:x1=1,x2=1,x3=0,x4=1。

1.2 概率密度函数
下面我们讲一下概率密度函数:
首先我们要了解概率密度函数物理意义:它意味着随机变量在某个确定的取值点附近的可能性,这听起来有点绕,我们来看一个例子:
我们用高斯分布来进行举例说明:
高斯分布,也叫正态分布,是一个连续的概率分布,随机变量的取值X可以使任何一个实数,高斯分布的概率密度函数为:
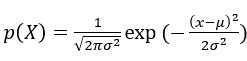
这里面μ是均值,σ是标准差, 下图坐标系中的横轴为随机变量的取值,纵轴为概率密度,其中的曲线为高斯分布的概率密度函数p(X),这个概率密度说明X在原点附近取值的概率比较大,远离原点的地方取值的概率比较小。

下图为:离散的概率分布,随机变量只能取{1,3,7}这几个值,如图右下角,X=1时的概率为0.2,X=3的概率为0.5,X=7的概率为0.3,其它任何地方概率都为0。

概率密度函数有这样的性质,把随机变量的定义域记作χ,如果p是个连续的概率分布,可以对p(X)做定积分,把所有X的取值都算法定积分得到的值为1,如果p是个离散的概率分布呢,随机变量在离散的χ取值,可以对p(x)做一个加和,把所有可能的取值都算上,结果等于1,这就是概率密度函数的基本性质,把所有可能的取值都算上,概率的积分和加和会等于1。

1.3 期望
接下来我们来了解一些期望是怎么定义的,这分为两种情况:
对于连续分布,函数f(x)的期望是这样定义的对p(x)和f(x)的乘积做定积分,这样就得到了f(x)的期望。这里的p(x)是概率密度函数。
对于离散分布,期望是用连加进行定义的,对p(x)和f(x)的乘积进行连加,这样就得到f(x)的期望。

1.4 随机抽样
对于随机抽样,我举个例子,箱子里面有10个球2个红色,5个绿色,3个蓝色,我现在把箱子摇一摇,把手伸进箱子里,闭着眼睛摸出来一个球,这个球是什么颜色的呢?
三种球都有可能被我摸到,摸到红色概率为0.2,摸到绿色的为0.5,摸到蓝色为0.3,在我摸之前,摸到的颜色就是随机变量X,现在我摸出来一个球,我睁开眼睛看到球是红色的,红色就是观测值x,这个过程就称为随机抽样。
我从箱子里面摸出来一个球,并且观测到它的颜色,这样一次随机抽样就完成了。

现在我换一种问法,箱子里面有很多个球,但我也不知道多少个,我现在做随机抽样,抽到红色球的概率为0.2,绿色球的概率为0.5,蓝色为0.3,我现在把手伸进箱子里摸一个球,摸到球是什么颜色的呢?这个问题其实和刚才的问题是一样的,所以应该和刚才有一样的答案,三种球都有可能被摸到,如果我只摸一次,什么球都可能被摸到。
假如我现在摸出来一个球,记录它的颜色,然后放回去,然后把箱子使劲摇,把球打散,然后重新摸一次,我重复这个过程100次,那我记录下来的颜色有什么特点呢,由于记录了100次具有统计意义了,大约20次是红色,50次是绿色,30次是蓝色,用0.2,0.3,0.5的概率来抽一个彩球,就是Random Sampling-随机抽样。
如下图,用python语言当中的numpy.random包里面的choice函数就能做这种抽样。

二、强化学习的专业术语
2.1 State and action
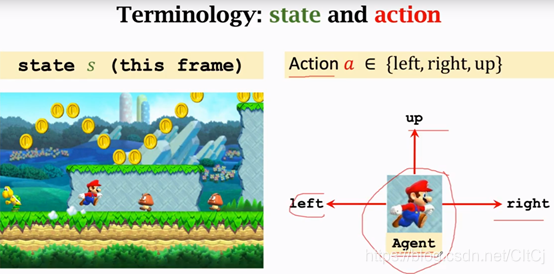
State可以理解成状态(环境状态),当我们在玩超级玛丽我们可以认为当前的状态就是下图中,超级玛丽游戏的画面,当然这样说不太严谨,我们观测的observation和state未必是相同的东西,为了方便我们理解,我们认为这张图片就是当前的状态,我们玩超级玛丽的时候观测到屏幕上的状态,就可以操纵马里奥做出相应的动作,马里奥做的动作就是action,假设马里奥会做三个动作,向左走、向右走和向上跳,这个例子里面马里奥就是agent,如果在自动驾驶的领域中汽车就是agent,总之在一个应用里面动作是谁做的谁就是agent,agent通常被翻译为智能体。
2.2 policy-策略
下面一个概念policy记为 π函数,policy是什么意思呢就是我们观测到屏幕上这个画面的时候,你该让马里奥做什么样的action呢,是往上还是左还是右,policy的意思就是根据观测到的状态来进行决策,来控制agent运动。
在数学上policy函数π是这样定义的,这个policy函数π是个概率密度函数:
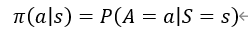
这个公式的意思就是给定状态s做出动作a的概率密度。
我举个例子,观测到马里奥这张图片agent(马里奥)会做出三种动作中的一种,把这张图片输入到policy函数π它会告诉我向左的概率为0.2,向右的概率为0.1,向上跳的概率为0.7。如果你让这个policy函数自动操作它就会做一个随机抽样,以0.2的概率向左走,0.1的概率向右走,0.2的概率向上跳,三种动作都有可能发生,但是向上跳的概率最大,向左的概率较小,向右的概率更小,强化学习学什么呢就是学这个policy函数只要有了这个policy函数,就可以让它自动操作马里奥打游戏了,我举的这个例子里agent的动作是随机的,根据policy函数输出的概率来做动作,当然也有确定的policy,那样的话动作就是确定的,为什么让agent动作随机呢,超级玛丽这个游戏里面马里奥的动作不管是随机还是确定都还没有问题都可以,但如果是和人博弈最好还是要随机,要是你的动作很确定别人就有办法赢,我们来想想剪刀石头布的例子,要是你出拳的策略是固定的那就有规律可循了,你的对手就能猜出你下一步要做什么,你很定会输,只有让你的策略随机,别人无法猜测你的下一步动作,你就会赢,所以很多应用里面policy是一个概率密度,最好是随机抽样得到的要有随机性。

2.3 reward
下一个知识点是奖励reward:
Agent做出一个动作,游戏就会给一个奖励,这个奖励通常需要我们来定义,奖励定义的好坏非常容易影响强化学习的结果,如何定义奖励就见人见智了,我举个例子:
马里奥吃到一个金币奖励R=+1,如果赢了这场游戏奖励R=+10000,我们应该把打赢游戏的奖励定义的大一些,这样才能激励学到的policy打赢游戏而不是一味的吃金币,如果马里奥碰到敌人Goomba,马里奥就会死,游戏结束,这时奖励就设为R=-10000,如果这一步什么也没发生,奖励就是R=0,强化学习的目标就是使获得的奖励总和尽量要高。

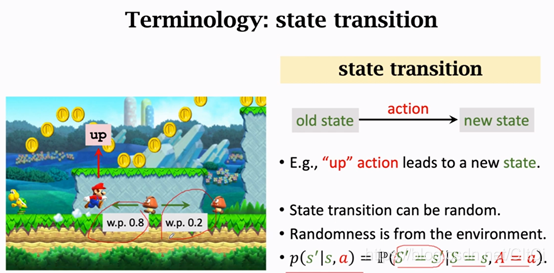
2.4 状态转移
当前状态下,马里奥做一个动作,游戏就会给出一个新的状态,比如马里奥跳一下,屏幕上下一个画面就不一样了,也就是状态变了,这个过程就叫做State transition(状态转移)状态转移可以是固定的也可以是随机的,通常我们认为状态转移是随机的,如果你学过马尔科夫链状态转移的随机性应该很容易理解,状态转移的随机性是从环境里来的。环境是什么呢?在这里环境就是游戏的程序,游戏程序决定下一个状态是什么,我举个例子来说明状态转移的随机性。
如果马里奥向上跳,马里奥就到上面去了,这个地方是确定的,而敌人Goomba可能往左,也可能往右,Goomba的状态是随机的这也造成下一状态的随机性。可以将状态转移用p函数来表示:
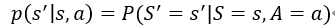
这是一个条件概率密度函数,意思是如果观测到当前的状态s以及动作a,p函数输出s’的概率,我举的这个例子里,马里奥跳到上面,Goomba往左的概率为0.8,往右为0.2,但是我们不知道这个状态转移函数,我知道Goomba可能往左也可能往右,但是我不确定它往左或者往右的概率有多大,这个概率转移函数只有环境自己知道,我们玩家是不知道的。
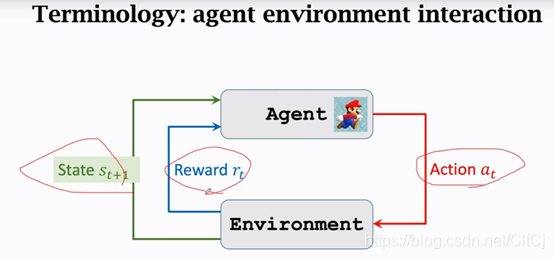
2.5 agent与环境交互
最基本的概念讲的差不多了,我们来看一下agent和环境是怎么进行交互的,agent是马里奥,状态St是环境告诉我们的,在超级玛丽的例子里面,我们可以把当前屏幕上显示的图片看做状态St,agent看到状态St之后要做出一个动作at,动作可以是向左走、向右走和向上跳,agent做出动作at之后环境会更新状态St+1,同时环境还会给agent一个奖励rt,
要是吃到金币奖励是正的,要是赢了游戏奖励就是一个很大的正数,要是马里奥over了奖励就是一个很大的负数。
三、强化学习的随机性
我们来看一下强化学习的随机性,搞明白随机性的两个来源,对之后的学习很有帮助。
3.1 动作随机
第一个随机性是根据动作来的,因为动作函数是根据policy函数π随机抽样得到的,我们用policy函数来控制agent,给定当前状态 S, agent的动作A是按照policy函数输出的概率来随机抽样,比如当前观测到的状态s,policy函数会告诉我们每个动作的概率有多大,agent有可能做其所存在的任何一种动作(向左,右,上)但这些动作的概率有大有小。

3.2 状态转移的随机性
另外一个随机性是状态转移,假定agent做出了向上跳的动作,环境就要生成下一个状态S’,这个状态S’具有随机性,环境用状态转移函数p算出概率,然后用随机抽样得到下一个状态S^’,比如说下一个状态有两种可能,根据状态转移函数的计算,一种状态的概率是0.8,另外一种状态的概率是0.2,这两个都有可能成为下一种状态,系统会做一个随机抽样来决定下一个状态是什么。
概括一下,强化学习中有两种随机性的来源,一种来源是agent的动作,,因为动作函数是根据policy函数π随机抽样得到的,另一种来源是状态转移,下一个状态是环境跟状态转移函数p来随机抽样的。

四、如何让AI自动打游戏?
怎么让AI自动打赢游戏呢?
我们通过强化学习学出policy函数π,我之后会讲怎么样学习policy函数,AI就是用policy函数来控制agent的,观测到游戏当前这一帧的状态s1,AI用policy函数来计算概率,然后随机抽样得到动作a1,然后环境会生成下一状态s2,并且给agent一个奖励r1,再然后AI就会拿新的状态作为输入,用policy函数来算概率然后随机抽样得到新的动作a2,这样一直循环下去直到打赢游戏或者game over,这样我们就会得到一个游戏的trajectory(轨迹),这个轨迹是每一步的状态,动作,奖励。

接下来我要讲几个很重要的概念,reward、return、,后面的课要反复使用这几个概念,我们需要记住,对于初学者来说这几个概念非常容易混淆,所以我们需要理解记忆。
五、强化学习基本概念
5.1 Return
Return翻译为回报,Return的另一个名字是cumulative future reward(未来的累计奖励),我们把t时刻的return叫做Ut,return这样定义的把t时刻的奖励全都累计加起来,一直加到游戏结束时的最后一个奖励。

这里,我问一个问题,你们觉得奖励R_t和+R_(t+1)同样重要吗?
假如,我给你两个选项:
1、 我立刻给你100块钱和我一年后我给你100块钱。你会选择哪一个?
理性的人应该都会选择现在立刻得到100块钱,这是因为未来的不确定性很大,即使我现在答应给你明年给你100,你也未必拿得到,大家都明白这个道理,明年得到这100块钱不如现在立刻得到这100块钱。
2、 是我换一个问题,现在我立刻给你80块钱,和我明年给你100块钱,你会选择哪一个,或许大家会做不同的选择,有人选择前者,有人选择后者。
所以呢,未来的奖励100不如现在的100好,未来的100恐怕只值现在的80,因此我该给未来的奖励打一个折扣,比如打一个8折,未来Rt+1的权重要比Rt低才可以,由于未来的奖励不如现在的奖励值钱,所以强化学习中常使用Discounted return(折扣回报),把折扣率记作𝛾,这个值要介于0和1之间,如果未来和现在的权重一样那么γ=1要是未来的奖励不重要γ就比较小,这就是折扣回报的定义:当前的奖励Rt没有折扣,下一时刻Rt+1的折扣率是𝛾,依次类推,折扣率是一个超参数需要我们自己来调,折扣率的设置对强化学习有一定的影响。

我们来看一下return Ut的随机性,假如游戏已经结束了,所有的奖励都观测到了,那么奖励就是数值用小写字母表示,如果在t时刻游戏还没有结束,这些奖励还是随机变量,还没有被观测到,我们就用大写字母R来表示奖励,由于return Ut依赖于奖励R所以return Ut也是一个随机变量,也用大写字母表示,随机变量有两个来源:
第一个是动作A,我们回忆一下,policy函数π,用状态S作为输入,输出一个正概率分布,动作a就是从这个随机抽样中得到的。
第二个随机性的来源的状态转移-下一个状态,给定了当前的状态s和动作a下一个状态s’是随机的,这个状态转移函数p输出一个概率分布,环境从这个概率分布中随机抽样得到新的状态s’。
对于任意的未来时刻i奖励Ri,会取决于状态Si和动作Ai
这是为什么呢?我们想一下超级玛丽游戏,当前马里奥处在一个状态,马里奥做什么动作就决定了奖励是什么,马里奥往上跳得到金币就得到一个正的奖励,马里奥往右走碰到了敌人挂掉了就得到一个很大的负的奖励,所以得到什么奖励和现在的状态和动作有关。我们回顾一下一下return的定义:
刚才说了,每一个奖励Ri,都和状态Si和动作Ai有关,那么Ut就跟t时刻开始未来所有的状态和动作都有关,return Ut的随机性就是和未来所有的状态和动作有关。
假设我们观测到状态St,那么return Ut 就依赖于这些随机变量未来的动作和状态。

5.2 价值函数
我们刚才定义了折扣回报Ut是未来奖励的总和,当要打个折扣,越久远的未来折扣越大,权重越低,为什么我们要定义return Ut呢,Ut非常有用,Ut是未来奖励的总和,所以agent就是让Ut尽量大,越大越好,除此之外,我从知道的Ut我就知道是快赢了还是快数输了,其实我是逗你玩的,(卧槽!!!)
其实Ut只是个随机变量,在t时刻你并不知道Ut是什么,打个比方你抛硬币,正面记为1,反面为0,在t时刻你还没有将硬币抛出去,你并不知道你是得到1还是0。
Ut是一个随机变量,它依赖所有的动作和状态,由于Ut是一个随机变量,在t时刻我并不知道Ut是什么,那我该如何去评估当前的形式呢?
我们可以对Ut求期望,把里面的随机性都积掉,得到的就是个实数,打个比方虽然在抛硬币之前你并不知道会得到什么,但你知道正反面各有一半的概率,如果正面记作1反面为0得到的期望就是0.5,同样得到了对随机变量Ut求期望会得到一个数记作Qπ,这个期望是怎么求的呢,把期望Ut当中未来所有的状态S和所有的动作A的一个函数,未来的动作A和状态S都有随机性,动作A的概率密度函数是policy函数π(a|s),状态S的概率密度函数是状态转移函数p(s’ |s,a),期望就是对未来的动作和状态求的,把这些随机变量都用积分积掉除了St和At其余的随机变量都被积掉了,被积掉的随机变量是A(t+1),A(t+2)…等动作和S(t+1),S(t+2)…等状态。求期望函数得到的Qπ称为Action-value function(动作价值函数),Qπ和当前的状态和动作(St和At)有关,为什么呢?因为其余的动作和价值都被积掉了,但是St和At没有被积掉,St和At被作为观测到的数值来对待,而不是作为随机变量。
Qπ的值依赖于St和At,函数Qπ还和policy函数π有关,为什么呢?因为积分的时候会用到policy函数,如果policy函数不一样,积分得到的函数Qπ就不一样。
5.3 Qπ
动作价值函数Qπ有什么直观意义呢?函数Qπ告诉我们如果用policy函数π,那么在t时刻这个状态St下做at这个动作是好还是坏,已知policy函数π,Qπ就会给当前状态下所有的动作进行打分,然后我们就知道哪个动作好,哪个动作不好。

刚才我们讲了动作价值函数Qπ和policy函数π有关,用不同policy函数就会得到不同Qπ,怎么样把动作价值函数中的π去掉呢,可以对π关于Qπ求最大化,意思就是我们有无数种policy函数π,但是我们应该使用最好的那一种函数,最好的policy函数是什么呢?就是让Qπ最大化的那个π,我们把得到的函数Q* 称为Optimal action-value function(最优动作价值函数),Q和policy函数π无关因为π已经被这个最大化max去掉了。
Q 有什么意义呢,它可以对动作a做评价,如果当前的状态是st,这个Q* 函数就会告诉我们这个动作at好不好,比如下围棋的时候状态就是这个棋盘,Q* 函数就会告诉我们了,如果你把棋子放在这个位置你的胜算有多大,如果把棋子放在别的位置你的胜算有多大,Q* 函数非常有用,假如有了Q* ,agent就能根据Q* 对动作的评价来做决策了,观测到一个状态,如果Q* 认为往上跳这个动作的分数最高,agent就应该往上跳,总之Q* 认为哪个动作的分数最高,agent就怎么动。

Note:强化学习里面概念比较多,没有捷径,我们只有理解然后记住。接下来介绍状态价值函数。
5.4 State-value function-状态价值函数
状态价值函数:

Vπ是动作价值函数Qπ的期望,Qπ和policy函数π,状态St,动作At有关,可以把这里的动作A作为随机变量,然后关于A求期望把A消掉,求期望得到的Vπ只和π和s有关。
函数Vπ有什么直观的意义呢?它能告诉我们当前的局势好不好。
假如我来根据policy函数π来下围棋,让Vπ看一下棋盘,它就会告诉我,当前我的胜算有多大,是快赢了快输了还是和对手不分高下,这里的期望都是根据随机变量A来求的,A的概率密度函数是π,根据期望的定义能够把期望写成连加或积分的形式。
如果动作都是离散的,比如上下左右,这样就能把期望写成连加,把π和Q的乘积做连加把所有的动作a都算上。
如果动作是连续的那么就可以把期望写成积分形式,期望等于π和Q的乘积做积分把a积掉。
六、两种价值函数
总结一下,主要有两种价值函数value-function:
6.1 动作价值函数
一种是动作价值函数,它主要和policy函数π有关,和状态s和动作a有关,它是Ut的条件期望,这里的Ut是个随机变量,它等于未来所有奖励的加权求和,期望把未来的动作和状态都消除了,只留下St和At这两个变量。
函数Qπ能告诉我们什么信息呢?如果使用policy函数π,那么Qπ说明agent处在状态s时做出动作a是否明智,Qπ可以给动作a打分。

6.2 状态价值函数Vπ
我们还定义了状态价值函数Vπ,Vπ是把Qπ中的变量A用积分去掉,这样变量就只剩下状态s,Vπ跟policy函数π和状态s有关和动作a无关。
如果使用policy函数π,那么Vπ能够评价当前状况是好是坏,我们是快赢了还是其它。如果π是固定的那么状态s越好Vπ的数值就越大,Vπ还能评价policy函数π的好坏,如果π越好,那么Vπ的平均值就越大。

七、强化学习如何打游戏
如果我们玩超级玛丽,那么我们的目标是什么呢?我们的目标就是操作马里奥多吃金币,避开敌人,向前走,打赢每一关,我们想写个程序用AI来控制agent,我们应该怎么做呢?
一种办法是学习policy函数π,这在强化学习里面叫做policy-based learning 基于策略的学习,我后面会讲,假如我们有了policy函数π,我们就可以用π函数控制agent做动作了,每观测到一个状态st就将st作为π函数的输入,π函数会输出每一个动作的概率,然后用这些概率做随机抽样得到at,最后agent执行这个动作at,AI就是用这种方式控制agent打游戏的。

另外一种方法是optimal action-value function(最优动作-价值函数)Q* ,这在强化学习里面称为value-based learning 价值学习,我们将在下一章讲,假如我们有了Q* agent就能根据Q* 函数来做动作了,Q* 函数告诉我们如果处在状态s,那么做动作a是好还是坏,每观测到一个状态st就将这个状态st作为Q* 函数的输入,让Q* 函数对每一个动作进行评价,这样我们就知道向左、向右、向上每一个动作的Q值,假如向上跳的Q值最大,那么agent就应该向上跳,为什么呢?Q值是对未来奖励的期望,如果向上跳这个动作的Q值比其它动作的Q值大,就意味着向上跳这个动作将在未来获得更多的奖励,我们需要马里奥吃到更多的金币打赢游戏,所以就应该选择向上跳这个动作,用数学公式可以这样表示,有了Q* 函数,选择让Q* 函数最大化的a作为下一个动作at。

概括一下有两种方式用AI控制agent玩游戏,一种是policy函数π,另外一种是optimal action-value function(最优动作-价值函数)Q* ,两种方法都可行,所以强化学习的任务就学习π函数或学习Q* 函数。只要学到两者之一就可以了。

后面我们就是讲怎么样学习这两种函数:
如果你设计的一种算法是学到了π函数或者Q*函数,你就可以把算法用在控制问题上或者用在小游戏上。
7.1 OpenAI Gym
OpenAI Gym是强化学习常用的标准库如果你用强化学习,你很定会用到这个
Gym有几大控制问题如:
Cart Pole、Pendulum
Pong、Space Invader

连续问题:Ant、Humanoid、Half Cheetah

总结
期待大家和我交流,留言或者私信,一起学习,一起进步!麻烦大家可用关注公众号:AI那些事,感谢!!!





