文章目录
系列目录与传送门
1、什么是RAM
2、RAM IP核介绍
2.1、RAM的三种形式
2.2、RAM的实现方式与优化算法
2.3、读写模式
2.4、端口位宽/深度比
2.5、字节写(Byte-Writes)
2.6、访问冲突 (Collision Behavior)
2.7、可选输出寄存器(Optional Output Registers)
2.8、流水线输出(Optional Pipeline Stages)
2.9、对输出寄存器的可选控制
2.10、复位优先级
3、参考与总结
系列目录与传送门
《从底层结构开始学习FPGA》目录与传送门
此文仅仅对xilinx BRAM IP的参数做了详细解读,关于IP核的定制与使用方法请移步:从底层结构开始学习FPGA----Xilinx RAM IP的定制与测试
1、什么是RAM
随机存取存储器(Random Access Memory,RAM),也叫主存,是与CPU直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。RAM工作时可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。RAM在计算机和数字系统中用来暂时存储程序、数据和中间结果。
通俗来讲,RAM和ROM都可以看做是一张用来存储数据的表格,每个表格的位置则是通过地址线来确定的。只不过RAM即可以写数据,也可以读数据;而ROM则只能读数据(初始化数据不将其视为一次写操作)。
Xlinx系列FPGA,包含两种RAM:Block RAM和分布式RAM(Distributed RAM),他们的区别在于,Block RAM是内嵌专用的RAM,而Distributed RAM需要消耗组合逻辑资源LUT组成。
我们今天要学习的正是由BRAM资源构成的RAM IP核----Block Memory Generator。
2、RAM IP核介绍
2.1、RAM的三种形式
xilinx的RAM IP可以构建3种不同形式的RAM:
- 单口RAM(Single-port RAM)
- 简单双口RAM(Simple Dual-port RAM,也叫伪双端口RAM)
- 真双口RAM(True Dual-port RAM)
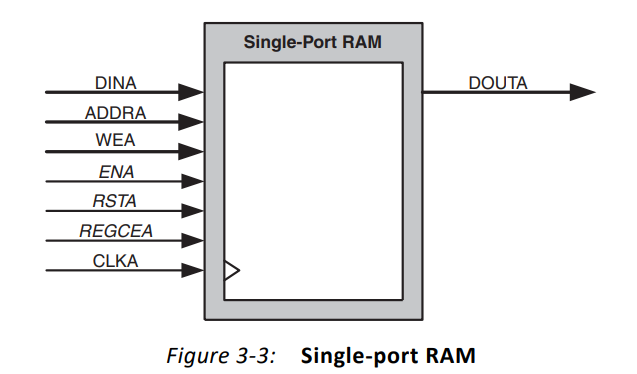
(1)单口RAM(Single-port RAM)
只有一个端口,可读可写,但无法同时进行。
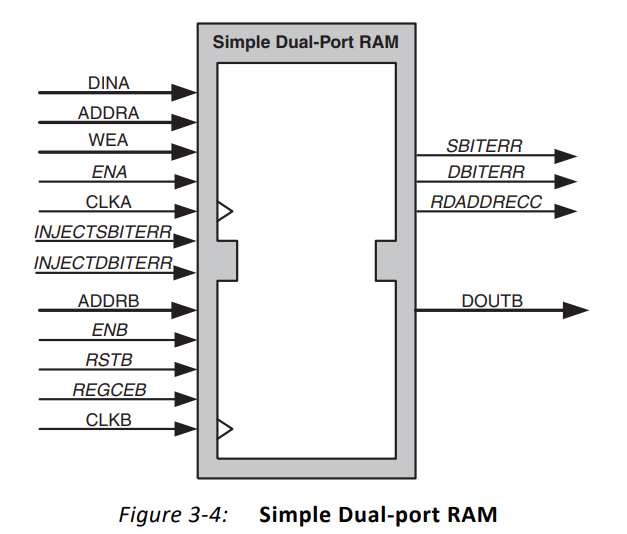
(2)简单双口RAM(Simple Dual-port RAM)
有两个独立的端口A、B,其中一个端口只读,另一个端口只写。
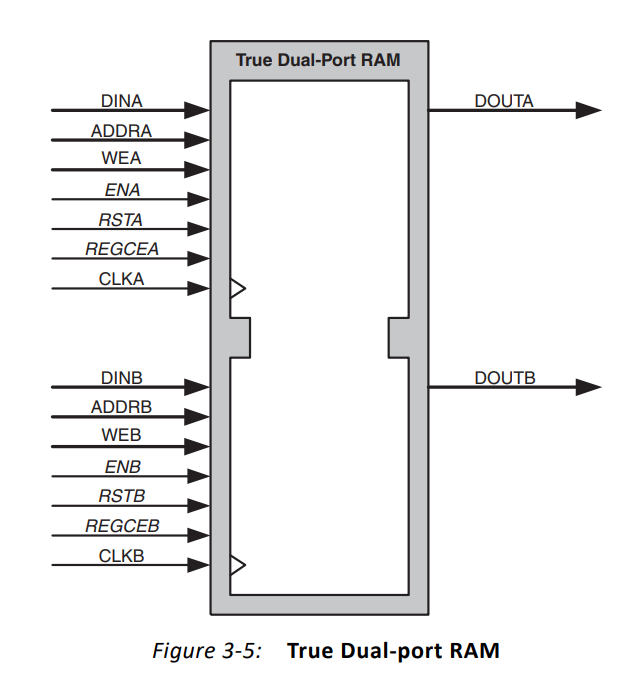
(3)真双口RAM(True Dual-port RAM)
有两个独立的端口A和端口B,2个端口都可以读、写。
2.2、RAM的实现方式与优化算法
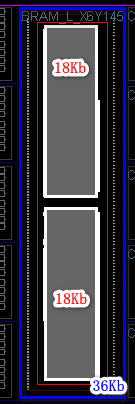
本文所谈到的是由BRAM组成的RAM,所以其基本单元是FPGA底层的固有存储资源----Block RAM(BRAM)。BRAM在FPGA底层以1块36KbBRAM、或者2块18KbBRAM组合而成。
18KbBRAM可以被配置成16K x 1, 8K x 2, 4K x 4, 2K x 9, 1K x 18, 512 x 36和256 x 72的模式,但其内部总容量仍为18Kb。
RAM IP核提供了三种优化方式来优化大容量的RAM实现。比如要实现,宽度为16bit, 深度为4K的RAM,仅仅使用一块36K的BRAM是无法实现的,必须要用到多块36KBRAM和18KBRAM的组合形式,下面三种算法针对不同的需求来优化RAM的实现。
(1)面积最小算法(Minimum Area Algorithm)
该算法使得实现RAM所使用的基本BRAM块数量是最小的,同时此种算法实现的运行频率也是比较高的,一般情况下默认使用该算法。
下面两种需求的RAM均是使用了最小数量的BRAM模块来实现。

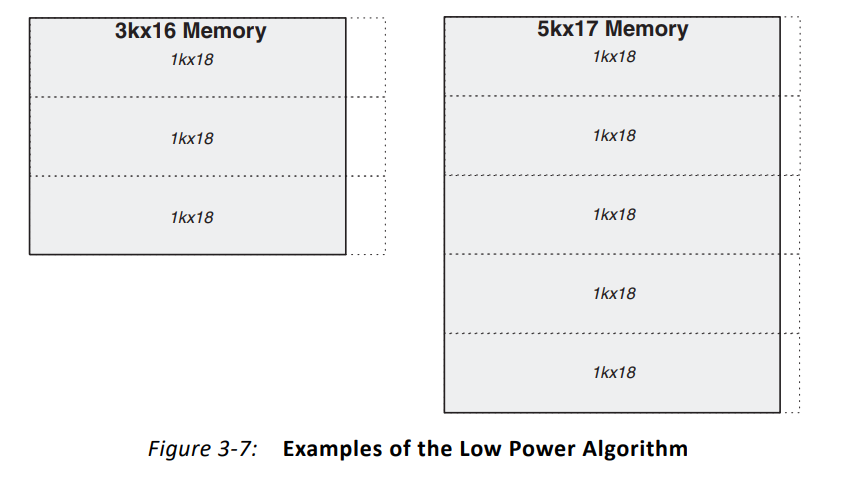
(2)低功耗算法(Low Power Algorithm)
该算法就是要实现最小的功耗,即适用于低功耗要求。
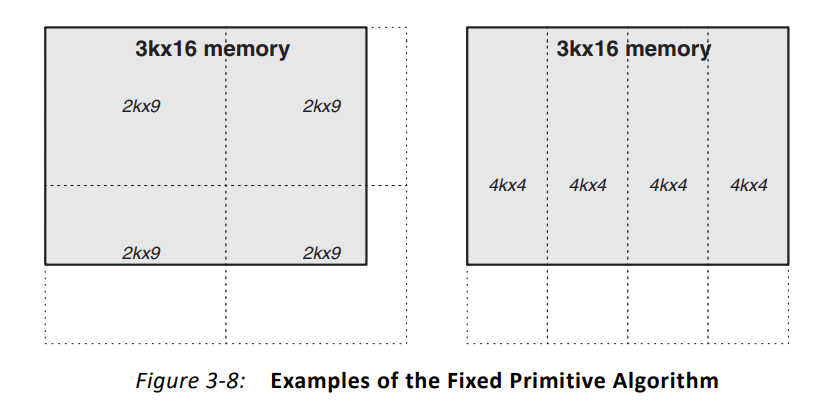
(3)固定模块算法(Fixed Primitive Algorithm)
此算法可以让开发者自己指定某个固定的源语模块来RAM的单一实现模块,如16K x 1, 8K x 2, 4K x 4, 2K x 9, 1K x 18, 512 x 36和256 x 72。
下面两种RAM的实现则使用了固定的两种BRAM块:2K x 9和4K x 4。
2.3、读写模式
IP核提供的读写模式有3种:
- Write First Mode 写优先模式
- Read First Mode 读优先模式
- No Change Mode 无变化模式
(1)Write First Mode--写优先模式
要被写入的数据会被写入到对应的地址里,同时输出线上的数据也会变成刚刚写入的数据。(需要注意的是:DOUTA中所出现的数据改变均需要一定的时间)
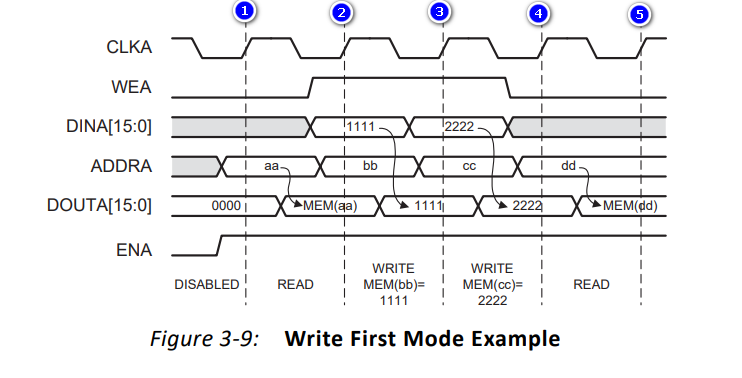
- 在上升沿①:ENA为1,WEA为0,地址为aa,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据
- 在上升沿②:ENA为1,WEA为1,地址为bb,所以对该地址进行写操作;数据1111会被写入该地址,同时输出总线DOUTA会输出刚刚写入的数据1111
- 在上升沿③:ENA为1,WEA为1,地址为cc,所以对该地址进行写操作;数据2222会被写入该地址,同时输出总线DOUTA会输出刚刚写入的数据2222
- 在上升沿④:ENA为1,WEA为0,地址为dd,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据
(2)Read First Mode--读优先模式
要被写入的数据会被写入到对应的地址里,同时输出线上输出该地址未被写入新数据之前的旧数据。
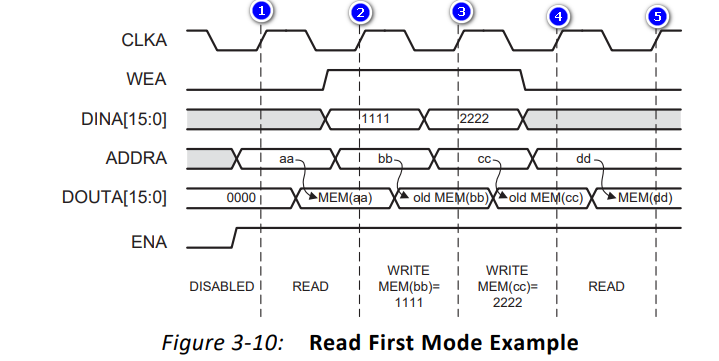
- 在上升沿①:ENA为1,WEA为0,地址为aa,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据
- 在上升沿②:ENA为1,WEA为1,地址为bb,所以对该地址进行写操作;数据1111会被写入该地址,同时输出总线DOUTA会输出地址bb的上一个存储的数据(旧数据)
- 在上升沿③:ENA为1,WEA为1,地址为cc,所以对该地址进行写操作;数据2222会被写入该地址,同时输出总线DOUTA会输出地址cc的上一个存储的数据(旧数据)
- 在上升沿④:ENA为1,WEA为0,地址为dd,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据
(3)No Change Mode--无变化模式
要被写入的数据会被写入到对应的地址里,同时输出线上则会保持上一次读出的数据不变,直到新的一次读操作发生
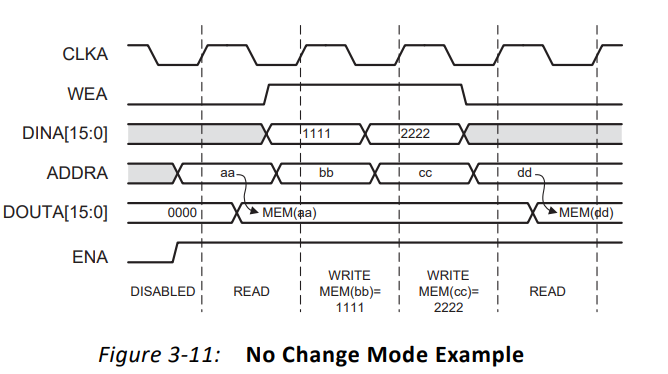
- 在上升沿①:ENA为1,WEA为0,地址为aa,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据
- 在上升沿②:ENA为1,WEA为1,地址为bb,所以对该地址进行写操作;数据1111会被写入该地址,同时输出总线DOUTA会保持输出不变,仍旧输出上一个数据
- 在上升沿③:ENA为1,WEA为1,地址为cc,所以对该地址进行写操作;数据2222会被写入该地址,同时输出总线DOUTA会保持输出不变,仍旧输出上一个数据
- 在上升沿④:ENA为1,WEA为0,地址为dd,所以对该地址进行读操作;DOUTA数据会输出该地址所存储的数据(此时为一次新的读操作,所以数据输出会输出新的读到的数据)
2.4、端口位宽/深度比
RAM IP核支持两个端口的位宽不同,只要满足以下比例条件即可:1:32, 1:16, 1:8, 1:4, 1:2, 1:1, 2:1, 4:1, 8:1, 16:1, 32:1。当然位宽成正比,则深度就成反比,因为总得容量大小是不变的。
下面的端口A配置是位宽32bi,深度2048bit。而B端口位宽设置为8(32/4),则其深度则为2048*4=8192bit。下面可以看到,由于端口B位宽仅仅为端口A位宽的四分之一,所以一个端口A的数据空间可以容纳4个端口B的数据,即A0包含B3, B2, B1, B0。

2.5、字节写(Byte-Writes)
RAM IP还具备字节写功能,这样可以只对某一个字节进行修改,从下图时序图可以看出,只要控制WEA就可以控制对具体哪一个BYTE进行写控制。
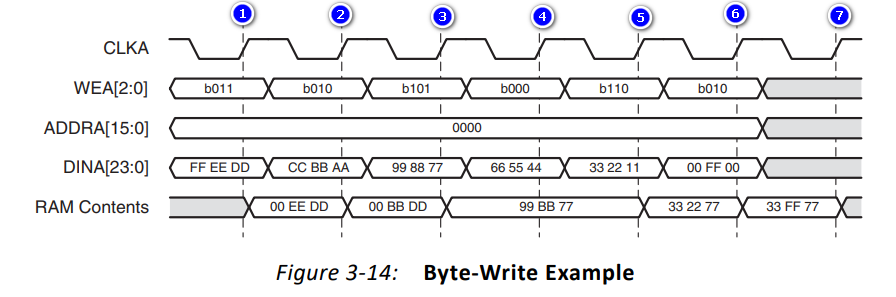
- 在上升沿①: 准备写入的数据为FF EE DD,写使能为011,所以最高字节的数据不会被写入,而低2字节的数据会被写入;RAM中的对应地址的内容会变为 00 EE DD
- 在上升沿②: 准备写入的数据为CC BB AA,写使能为010,所以最高和最低字节的数据不会被写入,只有中间字节的数据会被写入;RAM中的对应地址的内容会变为00 BB DD
- 在上升沿③: 准备写入的数据为99 88 77,写使能为101,所以最高字节和最低字节的数据会被写入,而中间字节的数据不会被写入;RAM中的对应地址的内容会变为99 BB 77
- 在上升沿④: 准备写入的数据为66 55 44,写使能为000,所以所有字节的数据都不会被写入;RAM中的对应地址的内容不变,仍为99 BB 77
- 在上升沿⑤: 准备写入的数据为33 22 11,写使能为110,所以最高字节和次高字节的数据会被写入,而最低BYTE的字节不会被写入;RAM中的对应地址的内容会变为33 22 77
- 在上升沿⑥: 准备写入的数据为00 FF 00,写使能为010,所以最高字节和最低字节的数据不会被写入,只有中间字节的数据会被写入;RAM中的对应地址的内容会变为33 FF 77
2.6、访问冲突 (Collision Behavior)
如果两个端口,同时对一个地址进行操作的话,则会产生读写冲突或者写写冲突(没有读读冲突,两个端口完全可以同时都读到正确的数据)。在实际的应用中,我们一般是用逻辑设计来尽量避免这种冲突行为,以免引入BUG。
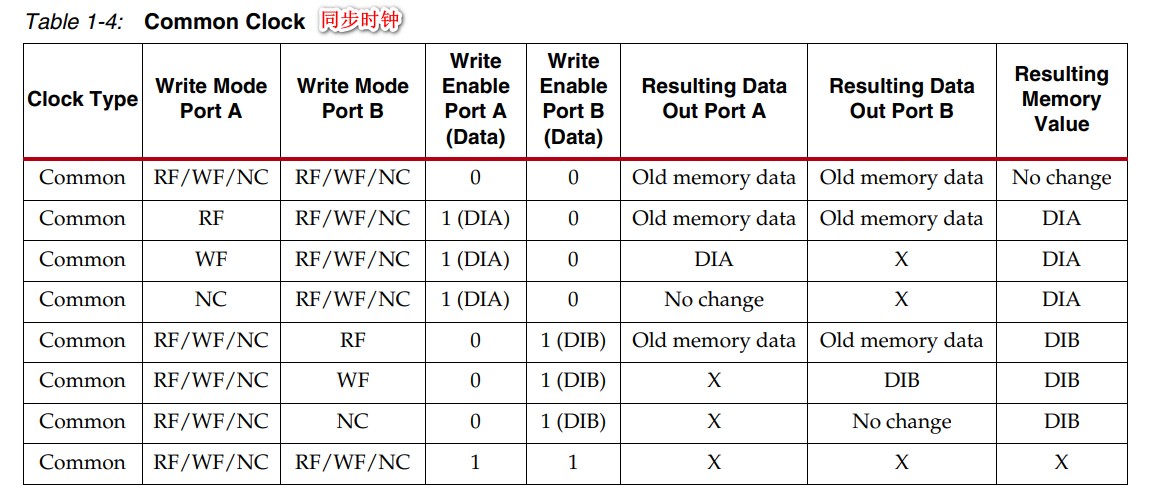
关于冲突行为,可以看下下面两个表的处理结果,其中:
- Write enable高有效,1 = Write, 0 = Read
- RF = READ_FIRST, WF = WRITE_FIRST, NC = NO_CHANGE
- X = 不定态
- DIA = 端口A输出输入
- DIB = 端口B输出输入

2.7、可选输出寄存器(Optional Output Registers)
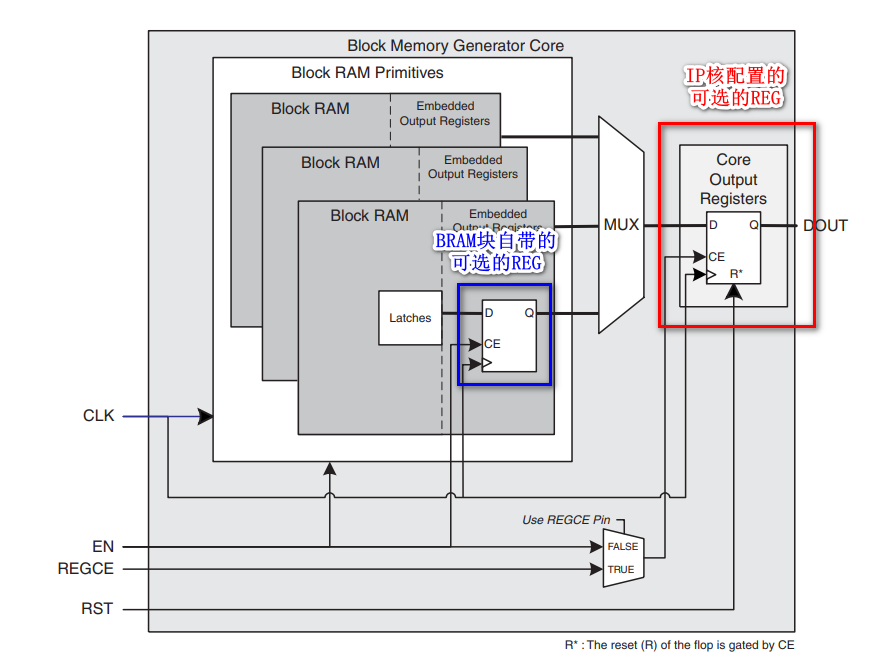
RAM IP核可以设置有寄存器输出和无寄存器输出,下图是RAM IP核的框图结构:
- 一个大容量的RAM由多个BRAM块组成,每个BRAM块都配置了一个内部的、可选的输出寄存器来改善时序,而无需消耗额外的逻辑资源
- 多个BRAM块的输出链接到MUX来进行选择输出
- IP核配置了一个可选的IP核输出寄存器来改善时序(因为接MUX引入了延迟)
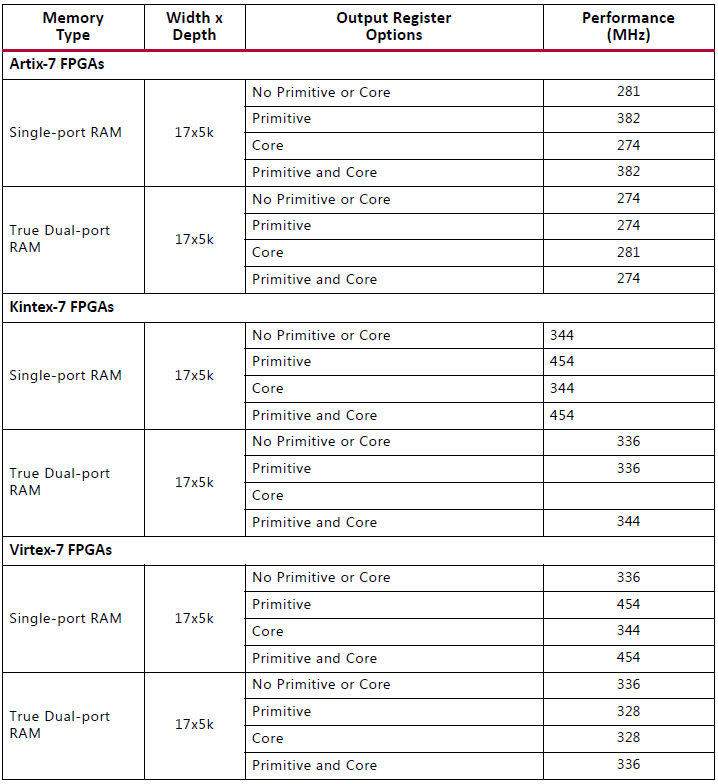
下图是有寄存器输出和无寄存器输出,可以达到的最高时钟频率的数据表。可以看到增加输出寄存器可以提高最高时钟频率,但是相应的,也会增加输出延迟(latency)。
2.8、流水线输出(Optional Pipeline Stages)
除了BRAM自带的寄存器和IP核配置的可选输出寄存器外,IP核还配置了可选的流水线输出。
这是因为大容量的RAM往往是由多个BRAM组成,而多个BRAM则势必会有多个MUX来控制选择对应地址下由哪个BRAM进行输出。MUX作为一个组合逻辑器件,无疑会增加输出路径上的组合逻辑延时,为了改善时序,IP核配备了0~3个可选的流水线性质的寄存器输出如下:
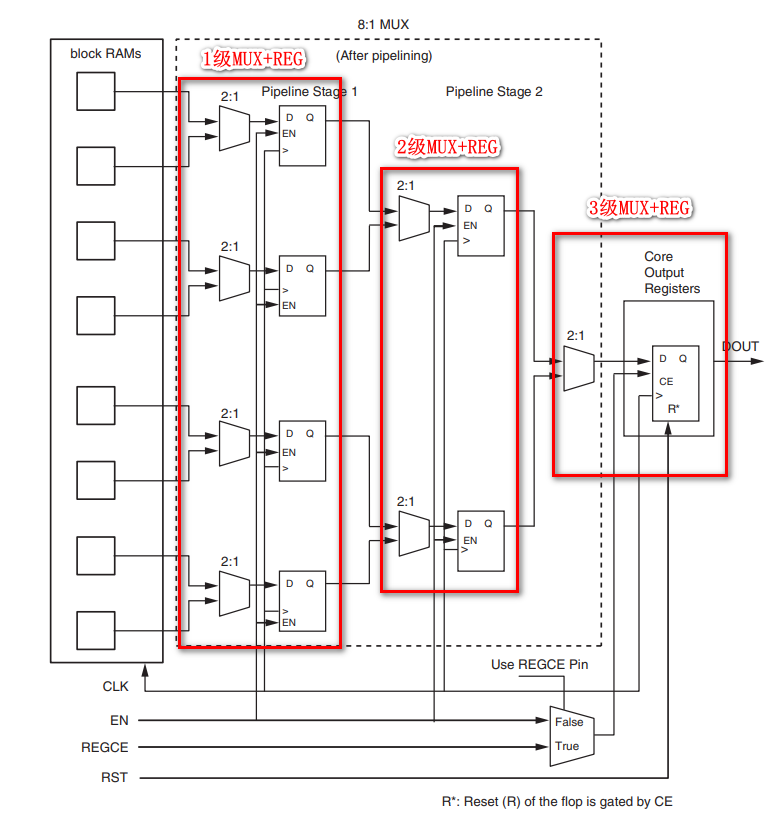
需要注意的是只有当core output register被勾选的时候,才能选择这个属性。而且虽然会改善时序,但是同样的会增加输出延迟(latency),所以一般建议只在BRAM的这几条路径是关键路径(critical path)的时候才视需要而使用。
2.9、对输出寄存器的可选控制
在2.7节中提到,对于IP核的输出我们可以选择配置一个寄存器来改善时序,同样的我们还可以对这个寄存器的控制信号进行配置来实现对IP核输出的更灵活控制。
(1)可选时钟使能信号(clock enable,CE)
默认情况下,输出寄存器的控制是由使能信号en控制,但是也可以选择激活各个端口的输出寄存器的时钟使能信号CE,达到控制数据路径最后一环输出寄存器的时钟信号,从而独立于en信号来控制整个IP核的输出。
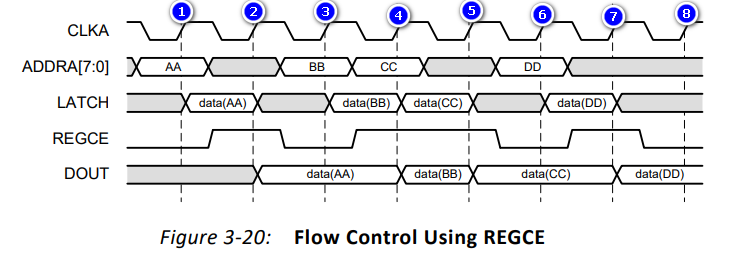
上图是使用寄存器的时钟使能信号来控制输出寄存器从而控制输出流的例子:
- 在上升沿①:地址为AA,所以输出LATCH上的值变为地址AA的值data(AA);REGCE为0,输出寄存器DOUT无输出
- 在上升沿②:未指定地址,所以输出LATCH上的值变为未知;REGCE为1,输出寄存器DOUT输出当前(时钟上升沿采样时)LATCH的值data(AA)
- 在上升沿③:地址为BB,所以输出LATCH上的值变为地址BB的值data(BB);REGCE为0,输出寄存器DOUT保持上一个值data(AA)不变
- 在上升沿④:地址为CC,所以输出LATCH上的值变为地址BB的值data(CC);REGCE为1,输出寄存器DOUT输出当前(时钟上升沿采样时)LATCH的值data(BB)
- 在上升沿⑤:未指定地址,所以输出LATCH上的值变为未知;REGCE为1,输出寄存器DOUT输出当前(时钟上升沿采样时)LATCH的值data(CC)
- 在上升沿⑥:地址为DD,所以输出LATCH上的值变为地址DD的值data(DD);REGCE为0,输出寄存器DOUT保持上一个值data(CC)不变
- 在上升沿⑦:未指定地址,所以输出LATCH上的值变为未知;REGCE为1,输出寄存器DOUT输出当前(时钟上升沿采样时)LATCH的值data(DD)
(2)可选的复位/置位信号(set/reset)
通过配置复位/置位信号,可以完成对RAM的复位和置位。这个置位信号一般是连接到最后一级的输出寄存器(实际上就是控制输出寄存器的复位/置位);如果没有使能输出寄存器,则控制倒数第二级的LATCH(实际上就是控制LATCH的复位/置位)。
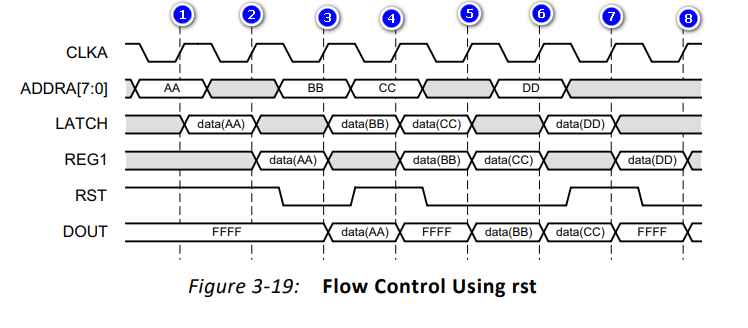
上图是使用复位来控制输出寄存器从而控制输出流的例子:
- 在上升沿①:地址为AA,所以输出LATCH上的值变为地址AA的值data(AA);REG1是LATCH打了一拍,所以其波形整体落后LATCH一个时钟,当前为未知值;RST为高,表示处于复位状态,所以DOUT的值被复位到设定的复位值FFFF
- 在上升沿②:未指定地址,所以输出LATCH上的值变为未知;RST为高复位,寄存器输出DOUT为复位值FFFF
- 在上升沿③:地址为BB,所以输出LATCH上的值变为地址BB的值data(BB);RST为低不复位,寄存器输出DOUT为当前采样到的REG1的值data(AA)
- 在上升沿④:地址为CC,所以输出LATCH上的值变为地址CC的值data(CC);RST为高复位,寄存器输出DOUT为复位值FFFF
- 在上升沿⑤:未指定地址,所以输出LATCH上的值变为未知;RST为低不复位,寄存器输出DOUT为当前采样到的REG1的值data(BB)
- 在上升沿⑥:地址为DD,所以输出LATCH上的值变为地址DD的值data(DD);RST为低不复位,寄存器输出DOUT为当前采样到的REG1的值data(CC)
- 在上升沿⑦:未指定地址,所以输出LATCH上的值变为未知;RST为高复位,寄存器输出DOUT为复位值FFFF
(3)输出读出的延迟(latency)
在组合逻辑延迟高的路径中插入寄存器可以有效的改善时序,同时也会增加数据输出的延迟,各延迟情况如下:
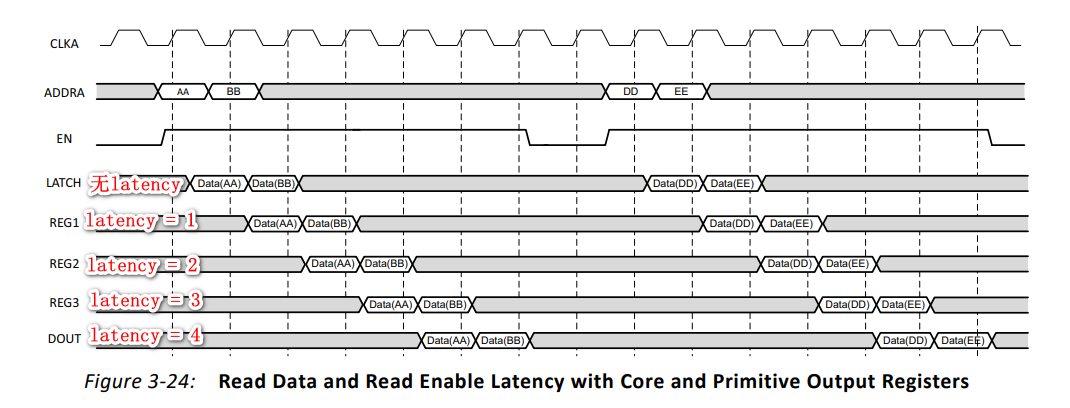
2.10、复位优先级
如果您定制IP的时候,选择了输出寄存器、输出寄存器的时钟使能CE和寄存器的复位/置位SR的话,就可以通过选择CE或者SR来设定复位的优先级了。
(1)CE高优先级
当选择CE的优先级高于SR,其波形如下:
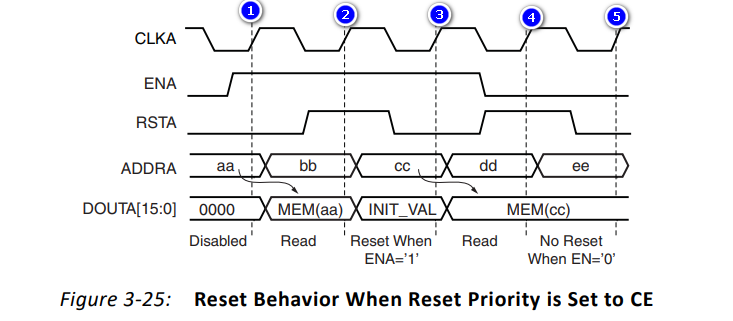
在上图中波形:
- 在上升沿①:ENA为高,RSTA为低,不需要复位;地址为aa,输出DOUTA为地址aa的值MEN(aa)
- 在上升沿②:ENA为高,RSTA为高,需要复位且复位成功;地址为bb,输出DOUTA为初始值INIT_VAL
- 在上升沿③:ENA为高,RSTA为低,不需要复位;地址为cc,输出DOUTA为地址cc的值MEN(cc)
- 在上升沿④:ENA为低,RSTA为高,需要复位但是复位不成功(ENA优先级更高);地址为dd,输出DOUTA由于CE为低,只能输出上一个值MEN(cc)
- 在上升沿⑤:ENA为低,RSTA为低,不需要复位;地址为ee,输出DOUTA由于CE为低,只能输出上一个值MEN(cc)
(2)SR高优先级
当选择SR的优先级高于CE,其波形如下:
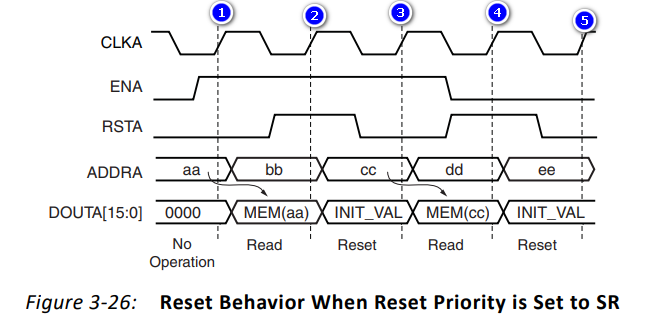
在上图中波形:
- 在上升沿①:ENA为高,RSTA为低,不需要复位;地址为aa,输出DOUTA为地址aa的值MEN(aa)
- 在上升沿②:ENA为高,RSTA为高,需要复位且复位成功;地址为bb,输出DOUTA为初始值INIT_VAL
- 在上升沿③:ENA为高,RSTA为低,不需要复位;地址为cc,输出DOUTA为地址cc的值MEN(cc)
- 在上升沿④:ENA为低,RSTA为高,需要复位且复位成功(RSTA优先级更高);地址为dd,输出DOUTA为初始值INIT_VAL
- 在上升沿⑤:ENA为低,RSTA为低,不需要复位;地址为ee,输出DOUTA由于CE为低,只能输出上一个值初始值INIT_VAL
3、参考与总结
- RAM IP核是个很常用也挺简单的IP核,但是其参数还有不少,虽然某些参数和功能都不常用,但是最好还是要了解一下。
- 创作不易,如果本文对您有帮助,还请多多点赞、评论和收藏。您的支持是我持续更新的最大动力!
参考资料1:Block Memory Generator v8.4
参考资料2:7Series_Memory_Resources
参考资料3:Vivado Design Suite 7 Series FPGA and Zynq-7000 SoC Libraries Guide




