文章目录
- 零、参考链接
- 一、前言
- 1.1 YOLO vs Faster R-CNN
- 二、YOLOv1(448*448)
- 2.1实现方法
- 2.2 损失函数
- 2.3 leak RELU激活函数
- 2.4总结
- 三、YOLOV2
- 3.1 YOLOv2介绍(320—608)
- 3.2 YOLOv2的改进点
- 3.2.1 Batch Normalization(批量归一化)
- 3.2.2 High resolution classifier(高分辨率图像分类器)
- 3.2.3 Convolution with anchor boxes(使用先验框)
- 3.2.4 Dimension clusters(聚类提取先验框的尺度信息)
- 3.2.5 Direct location prediction (约束预测边框的位置)
- 3.2.6 Fine-Grained Features (passthrough层检测细粒度特征)
- 3.2.7 Multi-ScaleTraining(多尺度图像训练)
- 3.3 YOLOV2的网络结构
- 3.3.1 Draknet19
- 3.3.2 Training for classification
- 3.3.3 Training for detection
- 3.3.4 Hierarchical classification(分层分类)
- 四、YOLOV3
- 4.1更好的backbone:Darknet53
- 4.2使用FPN与多级检测
- 4.3 预测原理
- 4.3 bounding box prediction
- 4.4 loss function
- 4.5 改进总结
- 五、YOLOV4
- 5.1 输入端改进
- 5.1.1 mosaic数据增强
- 5.1.2 cmBN
- 5.1.2自对抗训练(SAT)
- 5.2 BackBone主干网络
- 5.2.1 CSPDarknet53
- 5.2.2 Mish 激活函数
- 5.2.3 DropBlock正则化
- 5.2.4 label smoothing标签平滑
- 5.3Neck部分
- 5.3.1空间金字塔池化SPP模块
- 5.3.2 FPN+PAN结构
- 5.4检测头部分
- 5.4.1 C-IOU损失函数
- 5.4.2 非极大值抑制DIOU-NMS
- 六、YOLOV5
- 1、自适应锚框
- 2、自适应图片缩放
- 3、损失函数
- 七、名词解释
- 1、批量归一化Batch Normalization
- 2、梯度消失和梯度爆炸
- 3、特征金字塔FPN
零、参考链接
说明: 本文档是为了自己学习YOLO相关知识进行梳理的一份笔记,为了防止文档丢失整理成线上的方式,包括从YOLO到YOLOV5的网络结构、算法原理、版本间的改进措施等进行了整理,关于YOLOX、YOLOV7等算法因为时间关系,暂时放下。该文主要是参考了各位大佬们的技术博客,然后加以整合梳理而成,现将各位大佬们的专栏主页、文章链接一一列下放到文章最前面,表示对大佬的敬佩,如要详细学习请关注各位大佬们的相关专栏。对于文中引用的相关图片,如果侵权,请联系我删除,谢谢。
[1]YOLO系列详解:YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5
[2]深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
[3]YOLO-从零开始入门目标检测
[4]目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5,YOLObile,YOLOF,YOLOX详解
[5]搞懂YOLO v1看这篇就够了
[6]YOLOv1 前向推断后处理——NMS非极大值抑制
[7]一文读懂Faster R-CNN
一、前言
YOLO系列是one-stage且是基于深度学习的回归方法,而R-CNN、Fast-RCNN、Faster-RCNN等是two-stage且是基于深度学习的分类方法。
YOLO官网:https://github.com/pjreddie/darknet
1.1 YOLO vs Faster R-CNN
- 统一网络:YOLO没有显示求取
region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络。相对于R-CNN系列的"看两眼"(候选框提取与分类),YOLO只需要Look Once. - YOLO统一为一个回归问题,而Faster R-CNN将检测结果分为两部分求解:物体类别(分类问题)、物体位置即bounding box(回归问题)。
二、YOLOv1(448*448)
论文地址:https://arxiv.org/abs/1506.02640
官方代码:https://github.com/pjreddie/darknet
YOLOv1的核心思想:
YOLOv1的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
Faster RCNN的核心思想:
Faster RCNN中也直接用整张图作为输入,但是Faster-RCNN整体还是采用了RCNN那种proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLOv1则采用直接回归的思路。
Faster R-CNN学习参考网址:https://zhuanlan.zhihu.com/p/31426458
2.1实现方法
- 将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
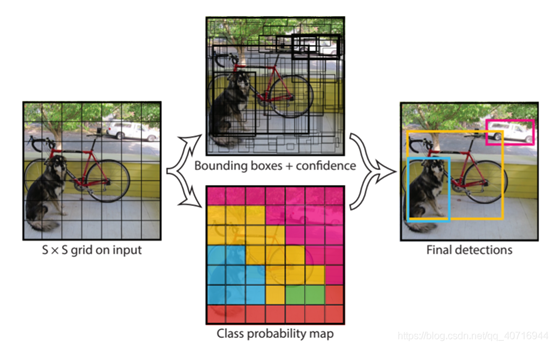
- 每个网格要预测B(YOLOV1中使用2个) 个
bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:
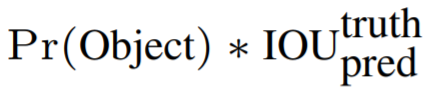
该表达式含义: 如果有object落在一个grid cell里,则第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。 - 每个bounding box要预测(x, y, w,h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。
注意: class信息是针对每个网格的,confidence信息是针对每个bounding box的。
举例说明:
在PASCAL VOC中,图像输入为448x448像素,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x(2x5+20)的一个tensor。整个网络结构如下图所示:
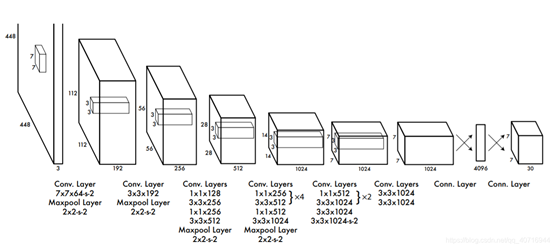
网络结构借鉴了GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
- 在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score,得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
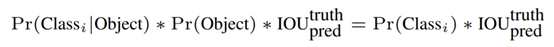
该表达式含义: - 等式左边第一项就是每个网格预测的类别信息
- 第二三项就是每个bounding box预测的confidence。
- 这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
YOLO前项推断后处理——非极大值抑制NMS:
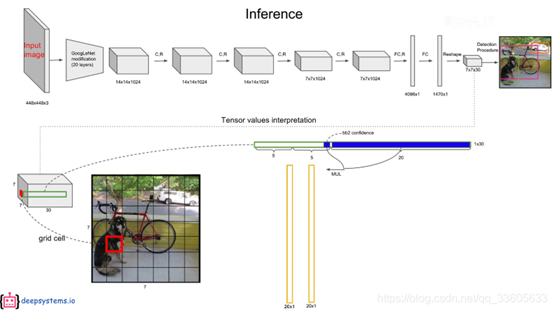
- 每个grid cell包含2个bounding box(每个bounding box包含4个box位置坐标和1个box置信度)和20个类别的条件概率。
- 将box置信度和20个类别的条件概率分别相乘,得到一个权概率(20*1)。
- 因此每个bounding box有一个权概率,1个grid cell有2个权概率,总共输出有772=98个权概率(上图竖条)。

- 把98个权概率分别以颜色(类别)和粗细(box置信度)加持,可视化就得到了中间的98个框。
接下来是正题——后处理——NMS非极大值抑制,把98个框变为最终的目标检测结果
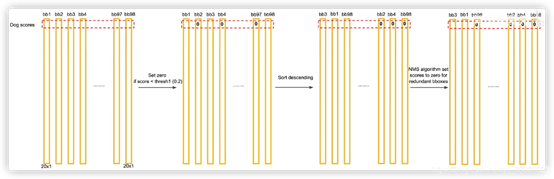
- 假设第一个类是狗,我们设一个阈值0.2,所有小于0.2的全设为0。
- 将所有权概率按狗的权概率重新按大到小进行排序。
- 非极大值抑制将多余的bounding box也设为0。
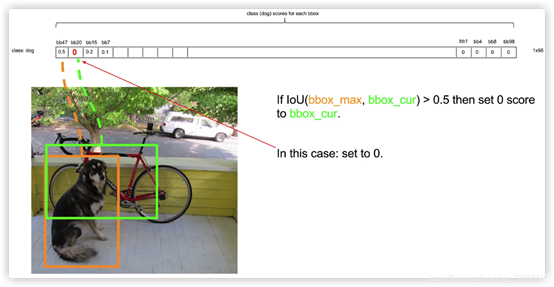
- 最左边的最大的bounding box和后面的bounding box分别计算ioU,设ioU阈值为0.5,如果ioU>0.5就将小的bounding box设为0。
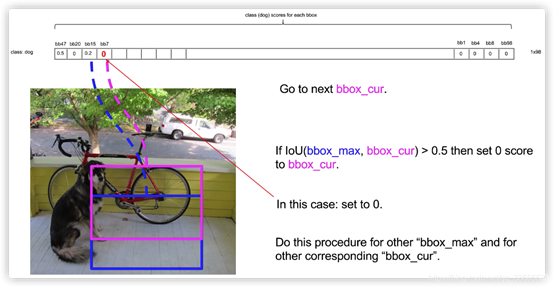
- 上一轮结束后,将第二大的bounding box分别和后面的计算,以此类推。
- 狗这一类结束后,重复操作猫类,飞机类等等,以上为NMS。
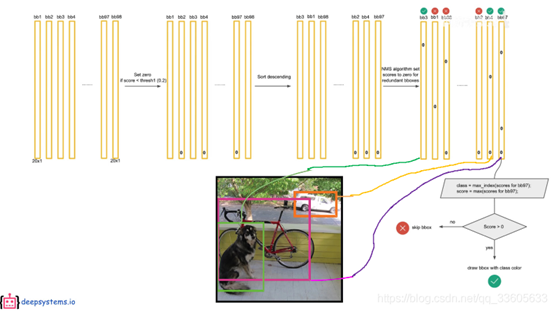
- 经过处理后,98个bounding box中有很多概率为0的类,分别对每个bounding box取最大值,如果最大值也是0就跳过这个bounding box,如果最大值大于0就记下这个概率以及对应的类,然后将这个bounding box中的(x,y,w,h)进行绘框,在框上写上刚刚记下的概率和类,对98个bounding box重复以上操作,至此前向推断完成。
2.2 损失函数
每个grid有30维,这30维中,8维是回归box的坐标,2维是box confidence,还有20维是类别。其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。
这种做法存在以下几个问题:
- 第一,8维的localization error和20维的classification error同等重要显然是不合理的;
- 第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决方法:
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight,记为λ_coord,在pascal VOC训练中取5;
- 对没有object的box的confidence loss,赋予小的loss weight,记为λ_noobj;
- 有object的box的confidence loss和类别的loss的loss weight正常取1。
YOLOv1在对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。这个参考下面的图很容易理解,小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。(也是个近似逼近方式)
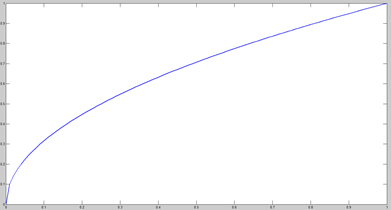
一个网格预测多个box,希望每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。

这个损失函数中:
- 只有当某个网格中有object的时候才对classification error进行惩罚。
- 只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。
其他细节,例如使用激活函数使用leak RELU,模型用ImageNet预训练等等。
2.3 leak RELU激活函数
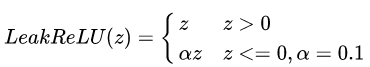
与ReLU函数不同的是在负值部分采用一个较小的斜率,而非直接等于0
2.4总结
注意:
- 由于输出层为全连接层,因此在检测时,YOLOv1模型的输入只支持与训练图像相同的输入分辨率(448*448)。
- 虽然每个格子可以预测B个bounding box,但是最终只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
简单的概括就是:
- 给个一个输入图像(448448),首先将图像划分成77的网格;
- 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率);
- 根据上一步可以预测出772个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
优缺点:
- YOLOV1对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 对测试图像中,同一类物体出现的新的不常见的长宽比时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
三、YOLOV2
论文地址:https://arxiv.org/abs/1612.08242
官方代码:http://pjreddie.com/darknet/yolo/
3.1 YOLOv2介绍(320—608)
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。
文章提出了一种新的训练方法–联合训练算法,这种算法可以把这两种的数据集混合到一起。使用一种分层的观点对物体进行分类,用巨量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
联合训练算法的基本思路就是: 同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用检测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
YOLO9000就是使用联合训练算法训练出来的,他拥有9000类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自COCO检测数据集。
YOLOv1有很多缺点,作者希望改进的方向是:改善recall,提升定位的准确度,同时保持分类的准确度。目前计算机视觉的趋势是更大更深的网络,更好的性能表现通常依赖于训练更大的网络或者把多种model综合到一起,但是YOLOv2则着力于简化网络。具体的改进见下表:
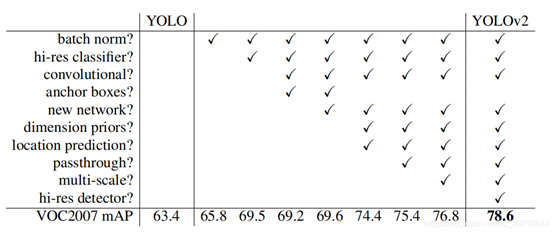
3.2 YOLOv2的改进点
3.2.1 Batch Normalization(批量归一化)

批量归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLOv2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。
使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。通过对YOLOv2的每一个卷积层增加Batch Normalization,最终使得mAP提高了2%,同时还使model正则化。使用Batch Normalization可以从model中去掉Dropout,而不会产生过拟合。
通常,一次训练会输入一批样本(batch)进入神经网络。批规一化在神经网络的每一层,在网络(线性变换)输出后和激活函数(非线性变换)之前增加一个批归一化层(BN),BN层进行如下变换:
- 对该批样本的各特征量(对于中间层来说,就是每一个神经元)分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。从而使得每一批训练样本在每一层都有类似的分布。这一变换不需要引入额外的参数。
- 对上一步的输出再做一次线性变换,假设上一步的输出为Z,则Z1=γZ+β。这里γ、β是可以训练的参数。增加这一变换是因为上一步骤中强制改变了特征数据的分布,可能影响了原有数据的信息表达能力。增加的线性变换使其有机会恢复其原本的信息。
https://zhuanlan.zhihu.com/p/362759621
3.2.2 High resolution classifier(高分辨率图像分类器)
用于图像分类的训练样本很多,而标注了边框的用于训练目标检测的样本相比而言就少了很多,因为标注边框的人工成本比较高。所以目标检测模型通常都先用图像分类样本训练卷积层,提取图像特征,但这引出另一个问题,就是图像分类样本的分辨率不是很高。所以YOLOv1使用ImageNet的图像分类样本采用 224*224 作为输入,来训练CNN卷积层。然后在训练目标检测时,检测用的图像样本采用更高分辨率的 448*448 像素图像作为输入,但这样不一致的输入分辨率肯定会对模型性能有一定影响。
所以YOLOv2在采用 224*224 图像进行分类模型预训练后,再采用448*448 高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响,最终通过使用高分辨率,mAP提升了4%。
3.2.3 Convolution with anchor boxes(使用先验框)
YOLOv1包含有全连接层,从而能直接预测Bounding Boxes的坐标值。Faster R-CNN算法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值,YOLOv2作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。
借鉴Faster RCNN的做法,YOLOv2也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
之前YOLOv1并没有采用先验框,并且每个grid只预测两个bounding box,也就是整个图像只有98个bounding box。YOLOv2如果每个grid采用9个先验框,总共有13*13*9=1521个先验框。所以最终YOLOv2去掉了全连接层,使用Anchor Boxes来预测 Bounding Boxes。作者去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率,同时对网络结构进行收缩让其运行在416*416而不是448*448。
由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。YOLOv2的卷积层采用32这个值来下采样图片,所以通过选择416*416用作输入尺寸最终能输出一个13*13的Feature Map。使用Anchor Box会让精确度稍微下降,但用了它能让YOLOv2能预测出大于一千个框,同时recall达到88%,mAP达到69.2%。
召回率升高,mAP轻微下降的原因是: 因为YOLOV2不使用anchor boxes时,每个图像仅预测98个边界框。但是使用anchor boxes,YOLOV2模型预测了一千多个框,由于存在很多无用的框,这就导致了mAP值的下降。但是由于预测的框多了,所以能够预测出来的属于ground truth的框就多了,所以召回率就增加了。目标检测不是只以mAP为指标的,有些应用场景下要求召回率高。
3.2.4 Dimension clusters(聚类提取先验框的尺度信息)
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。YOLOv2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLOv2的做法是对训练集中标注的边框进行K-means聚类分析,以寻找尽可能匹配样本的边框尺寸。如果我们用标准的欧式距离的k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高IOU分数,这依赖于Box的大小,所以距离度量的使用:
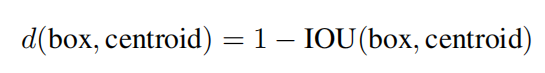
其中,centroid是聚类时被选作中心的边框,box就是其它边框,d就是两者间的“距离”,IOU越大,“距离”越近。YOLOv2给出的聚类分析结果如下图所示,通过分析实验结果(Figure 2),在model复杂性与high recall之间权衡之后,选择聚类分类数K=5。
通过kmeans聚类的方法所获得的先验框显然会更适合于所使用的数据集,但这也会带来一个问题:
- 从A数据集聚类出的先验框显然难以适应新的B数据集。尤其A和B两个数据集中所包含的数据相差甚远时,这一问题会更加的严重。因此,当我们换一个数据集,如COCO数据集,则需要重新进行一次聚类,如果样本不够充分,这种聚类出来的先验框也就不够好,这也是YOLOv2以及后续的YOLO版本的潜在问题之一。
- 由聚类所获得的先验框严重依赖于数据集本身,倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。当然,即便是人工设计的先验框也有着类似的问题,甚至整个anchor-based模型都有这一类问题,所以才有了后来的anchorfree工作,这是后话,暂且不提。
3.2.5 Direct location prediction (约束预测边框的位置)
用Anchor Box的方法,会让model变得不稳定,尤其是在最开始几次迭代的时候。大多数不稳定因素产生自预测Box的(x,y)位置的时候。按照之前YOLOv1的方法,网络不会预测偏移量,而是根据YOLOv1中的网格单元的位置来直接预测坐标,这就让Ground Truth的值介于0到1之间。而为了让网络的结果能落在这一范围内,网络使用一个 Logistic Activation来对于网络预测结果进行限制,让结果介于0到1之间。 网络在每一个网格单元中预测出5个Bounding Boxes,每个Bounding Boxes有五个坐标值tx,ty,tw,th,t0,他们的关系见下图。假设一个网格单元对于图片左上角的偏移量是cx,cy,Bounding Boxes Prior的宽度和高度是pw,ph,那么预测的结果见下图右面的公式:
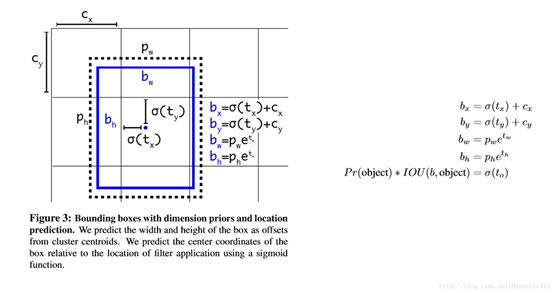
3.2.6 Fine-Grained Features (passthrough层检测细粒度特征)
目标检测面临的一个问题是图像中的需要检测的目标会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(比如YOLOv2中输入416*416经过卷积网络下采样最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。于是YOLOv2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26*26*512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
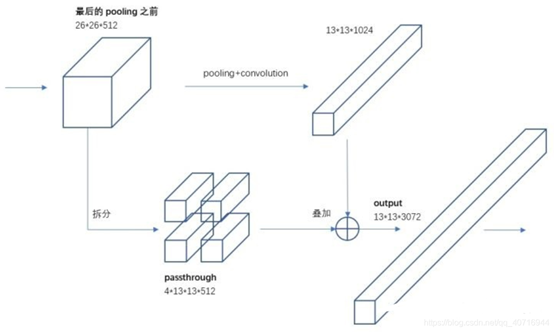
具体怎样将1个特征图拆成4个特征图,见下图,图中示例的是1个44拆成4个22,因为深度不变,所以没有画出来。
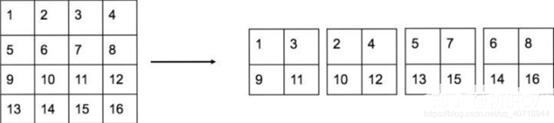
另外,根据YOLO2的代码,特征图先用11卷积从 2626512 降维到 2626*64,再做1拆4并passthrough。
3.2.7 Multi-ScaleTraining(多尺度图像训练)
作者希望YOLOv2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。
区别于之前的补全图片的尺寸的方法,YOLOv2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320*320,最大608*608,网络会自动改变尺寸,并继续训练的过程。
这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在YOLOv2的速度和精度上进行权衡。
因为YOLOV2调整网络结构后能够支持多种尺寸的输入图像。通常是使用416*416的输入图像,如果用较高分辨率的输入图像,比如544*544,则mAP可以达到78.6%,有1.8%的提升。
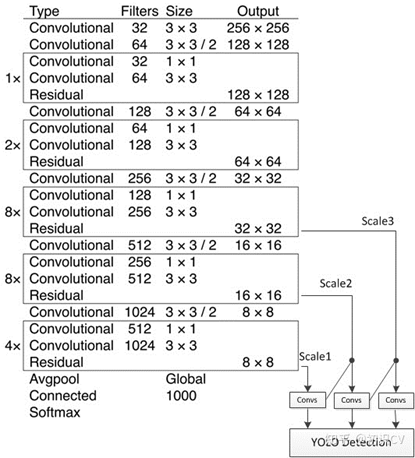
3.3 YOLOV2的网络结构
YOLOv1的backbone使用的是GoogleLeNet,速度比VGG-16快,YOLOv1完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69billion,但是YOLOv1精度稍低于VGG-16。
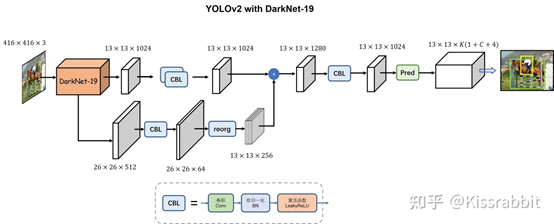
https://zhuanlan.zhihu.com/p/432343631
3.3.1 Draknet19
YOLOv2基于一个新的分类model,有点类似与VGG。YOLOv2使用3*3filter,每次Pooling之后都增加一倍Channels的数量。YOLOv2使用全局平均池化(Global Average Pooling),使用Batch Normilazation来让训练更稳定,加速收敛,使model规范化。最终的model–Darknet19,有19个卷积层和5个maxpooling层,处理一张图片只需要5.58 billion次运算,在ImageNet上达到72.9%top-1精确度,91.2%top-5精确度。
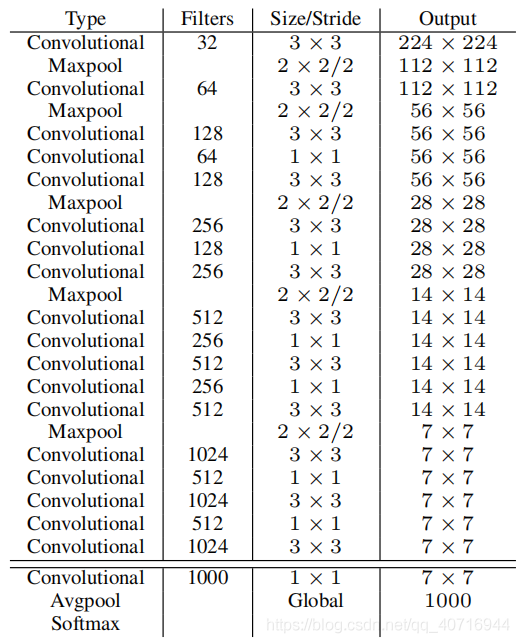
3.3.2 Training for classification
网络训练在 ImageNet 1000类分类数据集上训练了160epochs,使用随机梯度下降,初始学习率为0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9 。
训练期间使用标准的数据扩大方法:随机裁剪、旋转、变换颜色(hue)、变换饱和度(saturation), 变换曝光度(exposure shifts)。
在训练时,把整个网络在更大的448*448分辨率上Fine Turnning 10个 epoches,初始学习率设置为0.001,这种网络达到达到76.5%top-1精确度,93.3%top-5精确度。
3.3.3 Training for detection
网络去掉了最后一个卷积层,而加上了三个3*3卷积层,每个卷积层有1024个Filters,每个卷积层紧接着一个1*1卷积层。
对于VOC数据,网络对每个网格单元预测五个Bounding Boxes,每个Bounding Boxes预测5个坐标和20类,所以一共125个Filters,增加了Passthough层来获取前面层的细粒度信息,网络训练了160epoches,初始学习率0.001,数据扩大方法相同,对COCO与VOC数据集的训练对策相同。
3.3.4 Hierarchical classification(分层分类)
作者提出了一种在分类数据集和检测数据集上联合训练的机制。使用检测数据集的图片去学习检测相关的信息,例如bounding boxes 坐标预测,是否包含物体以及属于各个物体的概率。使用仅有类别标签的分类数据集图片去扩展可以检测的种类。
作者通过ImageNet训练分类、COCO和VOC数据集来训练检测,这是一个很有价值的思路,可以让我们达到比较优秀的效果。通过将两个数据集混合训练,如果遇到来自分类集的图片则只计算分类的Loss,遇到来自检测集的图片则计算完整的Loss。
但是ImageNet对应分类有9000种,而COCO则只提供80种目标检测,作者使用multi-label模型,即假定一张图片可以有多个label,并且不要求label间独立。通过作者Paper里的图来说明,由于ImageNet的类别是从WordNet选取的,作者采用以下策略重建了一个树形结构(称为分层树):
- 遍历Imagenet的label,然后在WordNet中寻找该label到根节点(指向一个物理对象)的路径;
- 如果路径直有一条,那么就将该路径直接加入到分层树结构中;
- 否则,从剩余的路径中选择一条最短路径,加入到分层树。
这个分层树我们称之为 WordTree,作用就在于将两种数据集按照层级进行结合。比如在coco数据集有一个类别是airplane,在ImgNet数据集下有biplane、jet、airbus等多种飞机类型,这样就将airplane作为一个父节点,然后biplane这些作为airplane的子节点。在进行计算时,p(jet)=p(jet|airplane)*p(airplane)
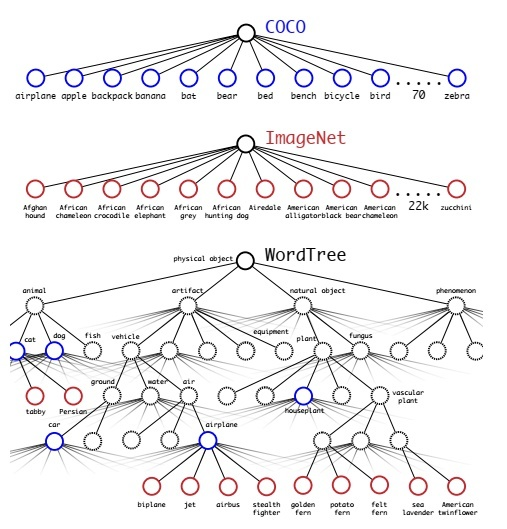
分类时的概率计算借用了决策树思想,某个节点的概率值等于该节点到根节点的所有条件概率之积。最终结果是一颗 WordTree (视觉名词组成的层次结构模型)。用WordTree执行分类时,预测每个节点的条件概率。如果想求得特定节点的绝对概率,只需要沿着路径做连续乘积。例如,如果想知道一张图片是不是“Norfolk terrier ”需要计算:

另外,为了验证这种方法作者在WordTree(用1000类别的ImageNet创建)上训练了Darknet-19模型。为了创建WordTree1k,作者天添加了很多中间节点,把标签由1000扩展到1369。训练过程中ground truth标签要顺着向根节点的路径传播。例如,如果一张图片被标记为“Norfolk terrier”,它也被标记为“dog” 和“animal”等。为了计算条件概率,模型预测了一个包含1369个元素的向量,而且基于所有“同义词集”计算softmax,其中“同义词集”是同一概念的下位词。
softmax操作也同时应该采用分组操作,下图上半部分为ImageNet对应的原生Softmax,下半部分对应基于WordTree的Softmax
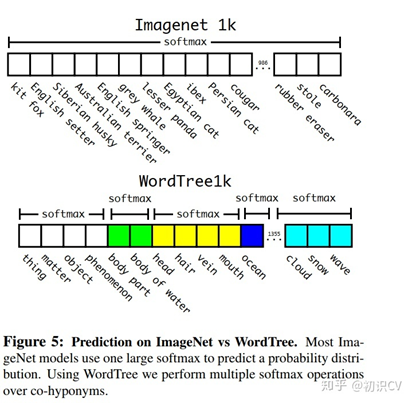
通过上述方案构造WordTree,得到对应9418个分类,通过重采样保证Imagenet和COCO的样本数据比例为4:1。
四、YOLOV3
在上一章的最后,我们提到不论是YOLOv1,还是YOLOv2,都有一个共同的致命缺陷:只使用了最后一个经过32倍降采样的特征图(简称C5特征图)。尽管YOLOv2使用了passthrough技术将16倍降采样的特征图(即C4特征图)融合到了C5特征图中,但最终的检测仍是在C5尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差。
为了解决这一问题,YOLO作者做了第三次改进,主要如下:
- 使用了更好的主干网络:DarkNet-53
- 使用了FPN技术与多级检测方法,相较于YOLO的前两代,YOLOv3的小目标的检测能力提升显著。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
4.1更好的backbone:Darknet53
- 采用了更深的网络,53层替换19层
- 使用残差网络Resnet中的残差连接结构
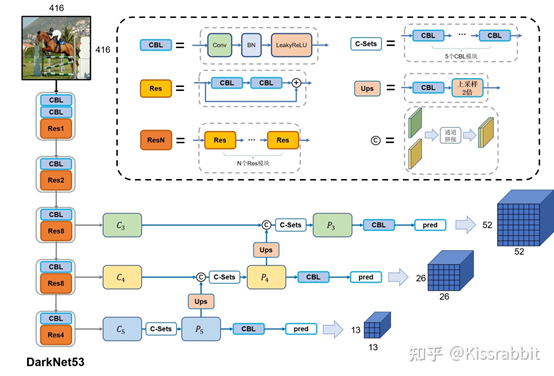
YOLOv3的第一处改进便是换上了更好的backbone网络:DarkNet53。相较于YOLOv2中所使用的DarkNet19,新的网络使用了更多的卷积——53层卷积,同时,添加了残差网络中的残差连结结构,以提升网络的性能。DarkNet53的具体结构如图2所示,注意,DarkNet53网络中的降采样操作没有使用Maxpooling层,而是由stride=2的卷积来实现。卷积层仍旧是线性卷积、BN层以及LeakyReLU激活函数的串联组合。
4.2使用FPN与多级检测
YOLOv3的关键改进便是使用了FPN结构与多级检测方法。YOLOv3在3个尺度上去进行预测,分别是经过8倍降采样的特征图C3、经过16倍降采样的特征图C4和经过32倍降采样的特征图C5。
随着网络深度的加深,降采样操作的增多,细节信息不断被破坏,致使小物体的检测效果逐渐变差,而大目标由于像素较多,仅靠网络的前几层还不足以使得网络能够认识到大物体(感受野不充分),但随着层数变多,网络的感受野逐渐增大,网络对大目标的认识越来越充分,检测效果自然会更好。于是,一个很简单的解决方案便应运而生:**浅层网络负责检测较小的目标,深层网络负责检测较大的目标。**考虑识别物体的类别依赖于语义信息,因此将深层网络的语义信息融合到浅层网络中去是个很自然的想法。
FPN工作的出发点便是如此,提出了一个行之有效的网络结构,如图4所示。其基本思想便是对深层网络输出的特征图使用上采样操作,然后与浅层网络进行融合,使得来自于不同尺度的细节信息和语义信息得到了有效的融合。
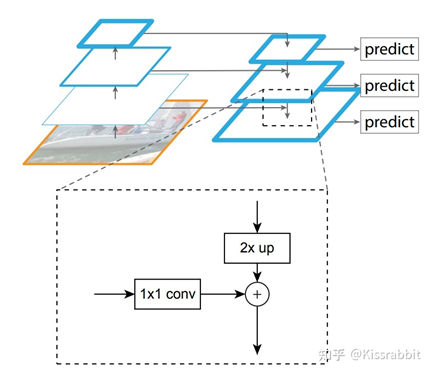
4.3 预测原理
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。YOLOv3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255,这个255就是这么来的。
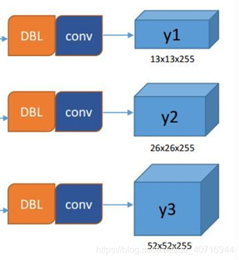
网络中作者进行了三次检测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟SSD有点像。在网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小,因此YOLOv3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
作者通过上采样将深层特征提取,其维度是与将要融合的特征层维度相同的(channel不同)。如下图所示,85层将13×13×256的特征上采样得到26×26×256,再将其与61层的特征拼接起来得到26×26×768。为了得到channel255,还需要进行一系列的3×3,1×1卷积操作,这样既可以提高非线性程度增加泛化性能提高网络精度,又能减少参数提高实时性。52×52×255的特征也是类似的过程。
4.3 bounding box prediction
YOLOv3的Bounding Box由YOLOv2又做出了更好的改进。在YOLOv2和YOLOv3中,都采用了对图像中的object采用k-means聚类。feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:
- 每个框的位置(4个值,中心坐标tx和ty,框的高度bh和宽度bw)
- 一个objectness prediction
- N个类别,coco数据集80类,voc20类。
三次检测,每次对应的感受野不同,
- 32倍降采样的感受野最大,适合检测大的目标,所以在输入为
416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。 - 16倍适合一般大小的物体,anchor box为
(30,61); (62,45); (59,119)。 - 8倍的感受野最小,适合检测小目标,因此anchor box为
(10,13); (16,30); (33,23)。
所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。
4.4 loss function
YOLO v3中主要包含三种损失,即坐标的损失,置信度的损失、分类的损失。
为了实现多标签分类,模型不再使用softmax函数作为最终的分类器,而是使用logistic作为分类器,使用 binary cross-entropy作为损失函数(使用sigmoid计算的xy, 物体置信度、类别置信度中均使用了交叉熵)
4.5 改进总结
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
- Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
五、YOLOV4
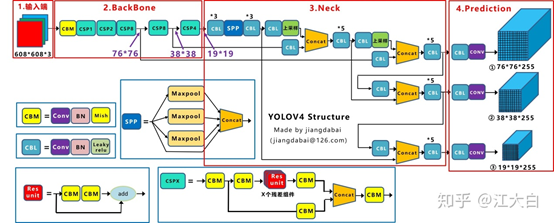
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
5.1 输入端改进
5.1.1 mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
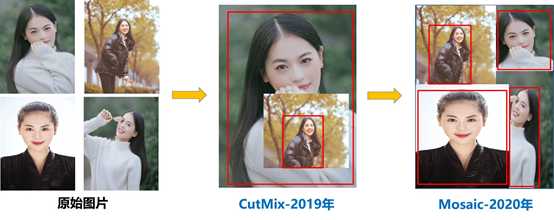
- **丰富数据集:**随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- **减少GPU:**可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
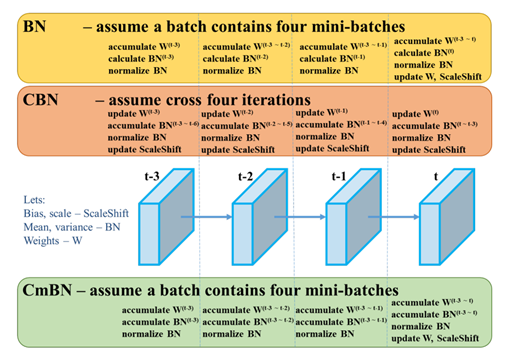
5.1.2 cmBN
BN就是仅仅利用当前迭代时刻信息进行norm,而CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些,比GN还慢。
CmBN是CBN的改进版本,其把大batch内部的4个mini batch当做一个整体,对外隔离。CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,不再滑动cross,其仅仅在mini batch内部进行汇合操作,保持BN一个batch更新一次可训练参数。
5.1.2自对抗训练(SAT)
SAT为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
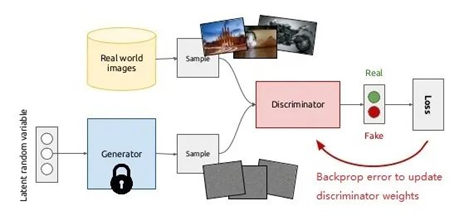
Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。 使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。
5.2 BackBone主干网络
5.2.1 CSPDarknet53
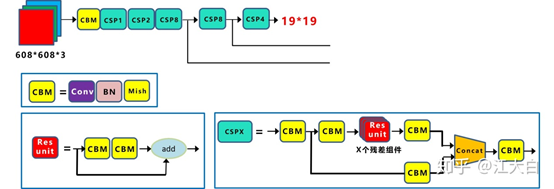
每个CSP模块前面的卷积核的大小都是3*3,stride=2,因此可以起到下采样的作用。
因为Backbone有5个CSP模块,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19,经过5次CSP模块后得到19*19大小的特征图。
而且作者只在Backbone中采用了Mish激活函数,网络后面仍然采用Leaky_relu激活函数。
*我们再看看下作者为啥要参考2019年的CSPNet,采用CSP模块?
*
CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。
因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点:
- 增强CNN的学习能力,使得在轻量化的同时保持准确性。
- 降低计算瓶颈
- 降低内存成本
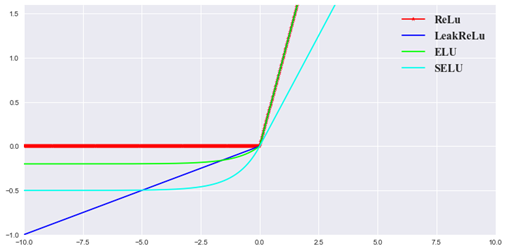
5.2.2 Mish 激活函数
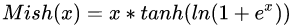
- Mish是一个平滑的曲线,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化;
- 在负值的时候并不是完全截断,允许比较小的负梯度流入。
5.2.3 DropBlock正则化
- 原始输入图像。
- 绿色部分表示激活的特征单元,b图表示了随机dropout激活单元,但是这样dropout后,网络还会从drouout掉的激活单元附近学习到同样的信息。
- 绿色部分表示激活的特征单元,c图表示本文的DropBlock,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗的别的部位的特征,来实现正确分类,从而表现出更好的泛化。
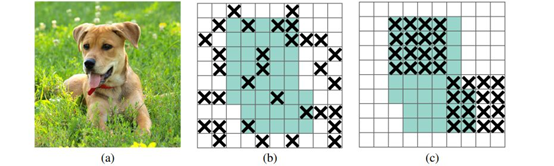
5.2.4 label smoothing标签平滑
通常YOLO模型中,80个分类标签都是使用0或1进行描述,在训练过程中,如果认为属于第n个分类,则该位置输出1(这种分类标签编码形式也称为one hot编码,即一位(独热)编码)。在数据集为无穷的情况下,可以对所有分类进行训练和标记,但是数据集不可能是无穷,尤其是当数据集量并不太大的时候,训练次数过多,很容易造成过拟合。采用Label Smoothing的技巧可以将标签的确定性减弱,从而降低过拟合的可能性。
https://blog.csdn.net/qq_41736617/article/details/115338124
5.3Neck部分
目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如SPP模块、FPN+PAN模块,用来融合不同尺寸特征图的特征信息。
5.3.1空间金字塔池化SPP模块
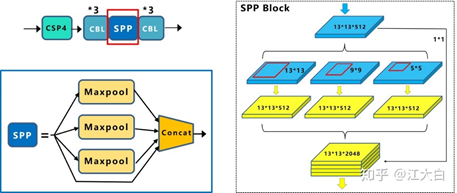
V3中为了更好的满足不同输入的大小,训练时要改变输入数据的大小。SPP其实就是对任意尺寸的特征图通过最大池化来满足最终输入特征一致。
常见的池化核有(1,1)(5,5)(9,9)(13,13)
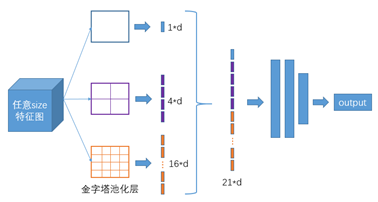
如上图,以3个尺寸的池化为例,对特征图进行一个最大值池化,即一张特征图得取其最大值,得到1*d(d是特征图的维度)个特征;对特征图进行网格划分为2x2的网格,然后对每个网格进行最大值池化,那么得到4*d个特征;同样,对特征图进行网格划分为4x4个网格,对每个网格进行最大值池化,得到16*d个特征。 接着将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。用到这里是为了增加感受野。
原文链接:https://blog.csdn.net/x454045816/article/details/109759989
5.3.2 FPN+PAN结构
YOLOv4的第二处改进便是采用了PAN(Path Aggregation Network)结构。原先的YOLOv3仅使用了top-down(上采样)结构的FPN,而PAN是在此基础上加了bottom-up(下采样)的结构。
由下图可以看到,主要用到两次PAN,第一次是在76*76那层,有一个指向下面的箭头,该箭头为一次下采样,同样的在38*38那一层也进行了一次PAN。
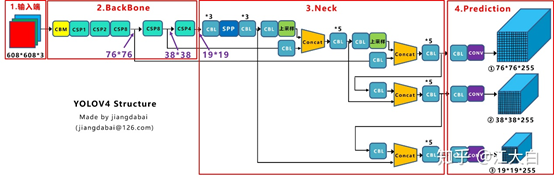
FPN和PAN都是通过融合不同尺度的特征,提高模型对不同尺寸目标的检测能力。
5.4检测头部分
5.4.1 C-IOU损失函数
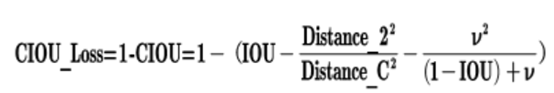
考虑到了detect与gt之间的重叠面积、中心点距离和长宽比
L=1-重叠面积+中心点距离+长宽比
5.4.2 非极大值抑制DIOU-NMS
DIoU(前面讨论过的) 被用作非最大值抑制(NMS)的一个因素。该方法在抑制冗余框的同时,采用IoU和两个边界盒中心点之间的距离。这使得它在有遮挡的情况下更加健壮。
六、YOLOV5
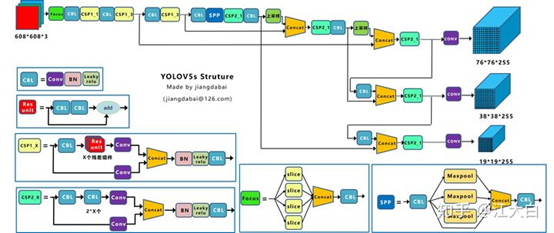
Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。模型文件只有24M
1、自适应锚框
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
2、自适应图片缩放
缩放时由原来的固定尺寸变为以添加最少黑边为原则。
3、损失函数
定位部分的损失函数使用了GIOU函数
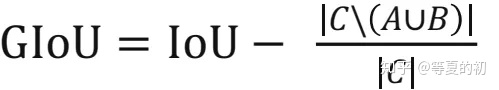
意思将两个任意框A,B,我们找到一个最小的封闭形状C,让C可以把A,B包含在内,接着计算C中没有覆盖A和B的面积占C总面积的比值,然后用A与B的IoU减去这个比值
七、名词解释
1、批量归一化Batch Normalization
内部协变量偏移问题(Internal Covariate Shift,ICS)
随着训练的进行,网络中的参数也随着梯度下降在不停更新。一方面,当底层网络中参数发生微弱变化时,由于每一层中的线性变换(网络训练)与非线性激活映射(激活函数),这些微弱变化随着网络层数的加深而被放大(类似蝴蝶效应);另一方面,参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难。
Batch Normalization的原论文作者给了Internal Covariate Shift一个较规范的定义:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
https://www.zhihu.com/question/38102762/answer/607815171
Batch Normalization原理
通常,一次训练会输入一批样本(batch)进入神经网络。批规一化在神经网络的每一层,在网络(线性变换)输出后和激活函数(非线性变换)之前增加一个批归一化层(BN),BN层进行如下变换:
①对该批样本的各特征量(对于中间层来说,就是每一个神经元)分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。从而使得每一批训练样本在每一层都有类似的分布。这一变换不需要引入额外的参数。
②对上一步的输出再做一次线性变换,假设上一步的输出为Z,则 Z1=γZ + β。这里γ、β是可以训练的参数。增加这一变换是因为上一步骤中强制改变了特征数据的分布,可能影响了原有数据的信息表达能力。增加的线性变换使其有机会恢复其原本的信息。
https://zhuanlan.zhihu.com/p/362759621
总结:
- batch normalization的提出是为了解决ICS问题,即在深层网络训练过程中,由于网络参数的变化引起内部节点数据分布发生变化,导致梯度下降变慢和网络收敛速度变慢;
- 在神经网络中引入BN,对分布差异较大的数据进行归一化,让数据特征具有相同的分布,而且保留了输入数据的表达能力。
- 在神经网络中引入BN,使得在训练时网络模型对学习率、初始化方法等参数的敏感度降低。例如,当学习率设置太高时,会使得参数更新步伐过大,容易出现震荡和不收敛,当对权重进行缩放时,经过BN后缩放因子会被消去;而且在求偏导时,缩放因子越大,梯度变化就越小,避免了学习率的大小变化带来的影响。
- BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题。在不使用BN层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过normalize操作可以让激活函数的输入数据落在梯度非饱和区,缓解梯度消失的问题;另外通过自适应学习λ与β又让数据保留更多的原始信息。
- 正则化效果: 在Batch Normalization中,由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
- 另外,原作者通过也证明了网络加入BN后,可以丢弃Dropout,模型也同样具有很好的泛化效果。
2、梯度消失和梯度爆炸
深度学习网络在训练时,最终是求得让损失函数达到收敛的一组权重参数,这就需要进行迭代。假设这个网络共有三层,在计算得到一次训练的误差之后,为了更新网络第一层参数,需要使用这个误差对第一层权重求偏导,根据链式法则,误差需要先对第三层求偏导然后对第二层求偏导然后对第一层求偏导
(1) 梯度消失(gradient vanishing problem)
我们知道神经网络在进行反向传播(BP)的时候会对参数W进行更新,梯度消失就是靠后面网络层(如layer3)能够正常的得到一个合理的偏导数,但是靠近输入层的网络层,计算的到的偏导数近乎零,W几乎无法得到更新。
(2)梯度爆炸(gradient exploding problem)
梯度爆炸的意思是,靠近输入层的网络层,计算的到的偏导数极其大,更新后W变成一个很大的数(爆炸)。
https://www.jianshu.com/p/3f35e555d5ba
https://blog.csdn.net/qq_40765537/article/details/106063941
3、特征金字塔FPN
FPN的最早是在2017年的CVPR会议上提出的,其创新点在于提出了一种自底向上(bottom-up)的结构,融合多个不同尺度的特征图去进行目标预测。FPN工作认为网络浅层的特征图包含更多的细节信息,但语义信息较少,而深层的特征图则恰恰相反。原因之一便是卷积神经网络的降采样操作,降采样对小目标的损害显著大于大目标,直观的理解便是小目标的像素少于大目标,也就越难以经得住降采样操作的取舍,而大目标具有更多的像素,也就更容易引起网络的“关注”,在YOLOv1+和YOLOv2+的工作中我们也发现了,相较于小目标,大目标的检测结果要好很多。
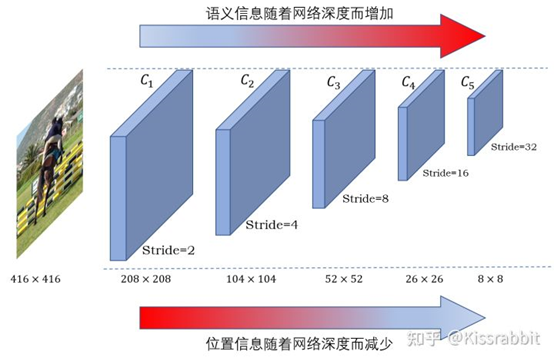
随着网络深度的加深,降采样操作的增多,细节信息不断被破坏,致使小物体的检测效果逐渐变差,而大目标由于像素较多,仅靠网络的前几层还不足以使得网络能够认识到大物体(感受野不充分),但随着层数变多,网络的感受野逐渐增大,网络对大目标的认识越来越充分,检测效果自然会更好。于是,一个很简单的解决方案便应运而生:浅层网络负责检测较小的目标,深层网络负责检测较大的目标。考虑识别物体的类别依赖于语义信息,因此将深层网络的语义信息融合到浅层网络中去是个很自然的想法。
FPN工作的出发点便是如此,提出了一个行之有效的网络结构,如图4所示。其基本思想便是对深层网络输出的特征图使用上采样操作,然后与浅层网络进行融合,使得来自于不同尺度的细节信息和语义信息得到了有效的融合。
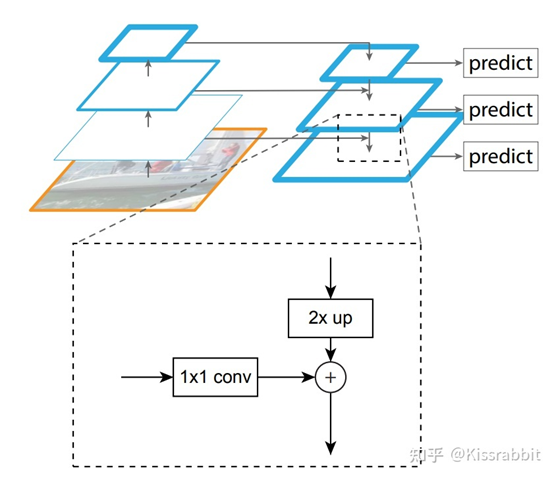
从网格的角度来看,越浅层的网格,划分出的网格也越精细,以416的输入尺寸为例,经过8倍降采样得到的特征图C3相当于是一个 的网格,这要比经过32倍降采样得到的特征图C5所划分的 的网格精细得多,也就更容易去检测小物体。同时,更加精细的网格,也就更能避免先前所提到的“语义歧义”的问题。
既然,FPN将不同尺度的特征图的信息进行了一次融合,那么一个很自然的方法也就应运而生:多级检测(multi-level detection)。最早,多级检测方法可以追溯到SSD网络,SSD正是使用不同大小的特征图来检测不同尺度的目标,这一方法的思想内核便是“分而治之”,即不同尺度的物体由不同尺度的特征图去做检测,而不是像YOLOv2那样,都堆在最后的C5特征图上去做检测。而FPN正是在这个基础上,让不同尺度的特征图先融合一遍,再去做检测。FPN的这一强大特性,使得它称为了“分而治之”检测方法的重要模块。也为后续许多的特征融合工作带去了启发,如PAN和BiFPN。
这里强调一下,“分而治之”方法的内核不是FPN,而是多级检测。FPN不过是锦上添花,即使我们不做特征融合,依旧可以做多级检测,如SSD。只是,使用特征融合手段,可以让检测的效果更好罢了。
多说一句,既然有“分而治之”,便也应有“合而治之”,所谓“合而治之”,是指所有物体我们都在一个特征图上去检测,换言之,就是“单级检测”(single-level detection),比如早期的YOLOv1和YOLOv2,便是最为经典的单级检测工作。只不过,主流普遍认为这种只在C5特征图上去单级检测的检测器,小目标检测效果是不行的,尽管这一点被ECCV2020的DeTR和CVPR2021的YOLOF工作否决了,却依旧难以扭转这一根深蒂固的观念,前者似乎只被关注了Transformer这一点上,而后者似乎被认为是“开历史倒车”。无数的历史已证明,根深蒂固的观念是很难被改变,而一旦被改变的那一天,便是一场旧事物的大毁灭与新事物的大喷发……
不过,还有一类单级检测工作则另辟蹊径,借鉴人体关键点检测工作的思想,使用高分辨率的特征图如只经过4倍降采样得到的特征图C2来检测物体,典型的工作包括CornerNet和脍炙人口的CenterNet。以512的输入尺寸为例,只经过4倍降采样得到的特征图C2相当于是一个128×128的网格,要比C5的16×16精细的多,然后再将所有尺度的信息都融合到这一张特征图来,使得这样一张具有精细的网格的特征图既具备足够的细节信息,又具备足够的语义信息。不难想象,这样的网络只需要一张特征图便可以去检测所有的物体。这一类工作具有典型的encoder和decoder的结构,通常encoder由常用的ResNet组成,decoder由简单的FPN结构或者反卷积组成,当然,也可以使用Hourglass网络。这一类的单级检测很轻松的得到了研究学者们的认可,毕竟,相较于在粗糙的C5上做检测,直观上便很认同分辨率高得多的C2特征图检测方式。只不过,C2特征图的尺寸太大,会带来很大的计算量,但是,这类工作不需要诸如800×1333的输入尺寸,仅仅512×512的尺寸便可以达到与之相当的性能




