一、ES中文分词插件(es-ik)
在中文数据检索场景中,为了提供更好的检索效果,需要在ES中集成中文分词器,因为ES默认是按照英文的分词规则进行分词的,基本上可以认为是单字分词,对中文分词效果不理想。
ES之前是没有提供中文分词器的,现在官方也提供了一些,但是在中文分词领域,IK分词器是不可撼动的,所以在这里我们主要讲一下如何在ES中集成IK这个中文分词器。
1、下载
首先下载es-ik插件,需要到github上下载。
https://github.com/medcl/elasticsearch-analysis-ik
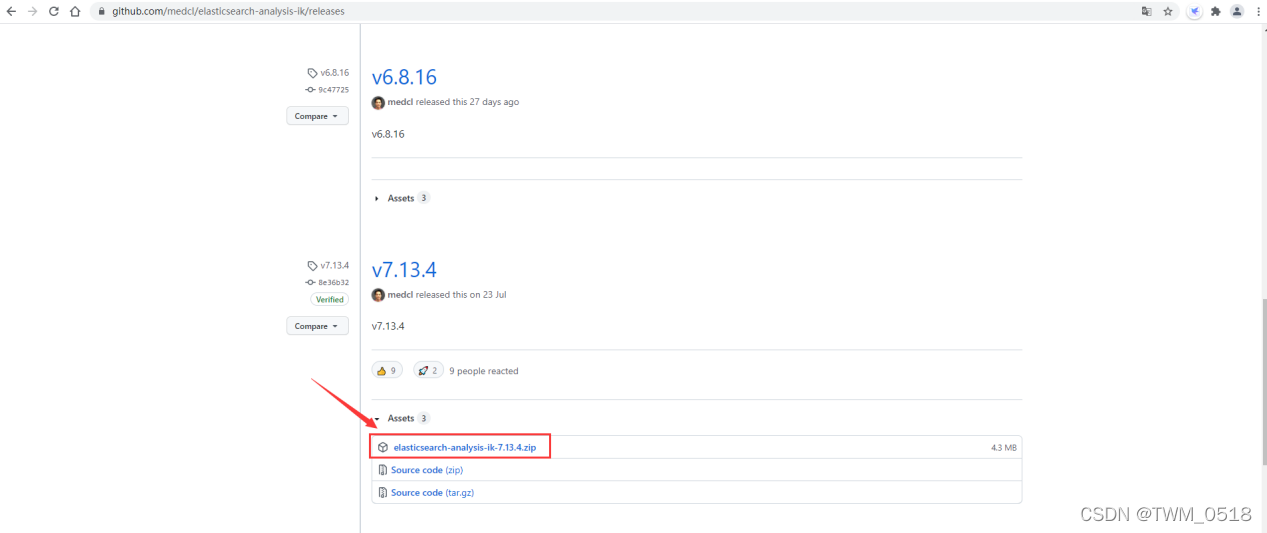
最终的下载地址为:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.4/elasticsearch-analysis-ik-7.13.4.zip
百度网盘地址:
链接:https://pan.baidu.com/s/1KgBGetSvLpIUPtDz5fUM5Q?pwd=eh35
提取码:eh35
注意:在ES中安装IK插件的时候,需要在ES集群的所有节点中都安装。
2、上传
将下载好的elasticsearch-analysis-ik-7.13.4.zip上传到bigdata01的/data/soft/ elasticsearch-7.13.4目录中。
[root@bigdata01 elasticsearch-7.13.4]# ll elasticsearch-analysis-ik-7.13.4.zip
-rw-r--r--. 1 root root 4504502 Sep 3 2021 elasticsearch-analysis-ik-7.13.4.zip
3、远程拷贝到其他节点
将elasticsearch-analysis-ik-7.13.4.zip远程拷贝到bigdata02和bigdata03上。
[root@bigdata01 elasticsearch-7.13.4]# scp -rq elasticsearch-analysis-ik-7.13.4.zip bigdata02:/data/soft/elasticsearch-7.13.4
[root@bigdata01 elasticsearch-7.13.4]# scp -rq elasticsearch-analysis-ik-7.13.4.zip bigdata03:/data/soft/elasticsearch-7.13.4
4、安装
在bigdata01节点离线安装IK插件。
[root@bigdata01 elasticsearch-7.13.4]# bin/elasticsearch-plugin install file:///data/soft/elasticsearch-7.13.4/elasticsearch-analysis-ik-7.13.4.zip
注意:在安装的过程中会有警告信息提示需要输入y确认继续向下执行。
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
最后看到如下内容就表示安装成功了。
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed
注意:插件安装成功之后在elasticsearch-7.13.4的config和plugins目录下会产生一个analysis-ik目录。
config目录下面的analysis-ik里面存储的是ik的配置文件信息。
[root@bigdata01 elasticsearch-7.13.4]# cd config/
[root@bigdata01 config]# ll analysis-ik/
total 8260
-rwxrwxrwx. 1 root root 5225922 Feb 27 20:57 extra_main.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word_full.dic
-rwxrwxrwx. 1 root root 10855 Feb 27 20:57 extra_single_word_low_freq.dic
-rwxrwxrwx. 1 root root 156 Feb 27 20:57 extra_stopword.dic
-rwxrwxrwx. 1 root root 625 Feb 27 20:57 IKAnalyzer.cfg.xml
-rwxrwxrwx. 1 root root 3058510 Feb 27 20:57 main.dic
-rwxrwxrwx. 1 root root 123 Feb 27 20:57 preposition.dic
-rwxrwxrwx. 1 root root 1824 Feb 27 20:57 quantifier.dic
-rwxrwxrwx. 1 root root 164 Feb 27 20:57 stopword.dic
-rwxrwxrwx. 1 root root 192 Feb 27 20:57 suffix.dic
-rwxrwxrwx. 1 root root 752 Feb 27 20:57 surname.dic
plugins目录下面的analysis-ik里面存储的是ik的核心jar包。
[root@bigdata01 elasticsearch-7.13.4]# cd plugins/
[root@bigdata01 plugins]# ll analysis-ik/
total 1428
-rwxrwxrwx. 1 root root 263965 Feb 27 20:56 commons-codec-1.9.jar
-rwxrwxrwx. 1 root root 61829 Feb 27 20:56 commons-logging-1.2.jar
-rwxrwxrwx. 1 root root 54626 Feb 27 20:56 elasticsearch-analysis-ik-7.13.4.jar
-rwxrwxrwx. 1 root root 736658 Feb 27 20:56 httpclient-4.5.2.jar
-rwxrwxrwx. 1 root root 326724 Feb 27 20:56 httpcore-4.4.4.jar
-rwxrwxrwx. 1 root root 1807 Feb 27 20:56 plugin-descriptor.properties
-rwxrwxrwx. 1 root root 125 Feb 27 20:56 plugin-security.policy
5、在bigdata02节点离线安装IK插件
[root@bigdata02 elasticsearch-7.13.4]# bin/elasticsearch-plugin install file:///data/soft/elasticsearch-7.13.4/elasticsearch-analysis-ik-7.13.4.zip
6、在bigdata03节点离线安装IK插件
[root@bigdata03 elasticsearch-7.13.4]# bin/elasticsearch-plugin install file:///data/soft/elasticsearch-7.13.4/elasticsearch-analysis-ik-7.13.4.zip
7、如果集群正在运行,则需要停止集群
在bigdata01上停止。
[root@bigdata01 elasticsearch-7.13.4]# jps
1680 Elasticsearch
2047 Jps
[root@bigdata01 elasticsearch-7.13.4]# kill 1680
在bigdata02上停止。
[root@bigdata02 elasticsearch-7.13.4]# jps
1682 Elasticsearch
1866 Jps
[root@bigdata02 elasticsearch-7.13.4]# kill 1682
在bigdata03上停止。
[root@bigdata03 elasticsearch-7.13.4]# jps
1683 Elasticsearch
1803 Jps
[root@bigdata03 elasticsearch-7.13.4]# kill 1683
8、修改目录权限
修改elasticsearch-7.13.4的plugins目录下analysis-ik子目录的权限
直接修改elasticsearch-7.13.4目录的权限即可。
在bigdata01上执行。
[root@bigdata01 elasticsearch-7.13.4]# cd ..
[root@bigdata01 soft]# chmod -R 777 elasticsearch-7.13.4
在bigdata02上执行。
[root@bigdata02 elasticsearch-7.13.4]# cd ..
[root@bigdata02 soft]# chmod -R 777 elasticsearch-7.13.4
在bigdata03上执行。
[root@bigdata03 elasticsearch-7.13.4]# cd ..
[root@bigdata03 soft]# chmod -R 777 elasticsearch-7.13.4
9、重新启动ES集群
在bigdata01上执行。
[root@bigdata01 soft]# su es
[es@bigdata01 soft]$ cd /data/soft/elasticsearch-7.13.4
[es@bigdata01 elasticsearch-7.13.4]$ bin/elasticsearch -d
在bigdata02上执行。
[root@bigdata02 soft]# su es
[es@bigdata02 soft]$ cd /data/soft/elasticsearch-7.13.4
[es@bigdata02 elasticsearch-7.13.4]$ bin/elasticsearch -d
在bigdata03上执行。
[root@bigdata03 soft]# su es
[es@bigdata03 soft]$ cd /data/soft/elasticsearch-7.13.4
[es@bigdata03 elasticsearch-7.13.4]$ bin/elasticsearch -d
10、验证IK的分词效果
首先使用默认分词器测试中文分词效果。
[root@bigdata01 soft]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/emp/_analyze?pretty' -d '{"text":"我们是中国人"}'
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "们",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "",
"position" : 2
},
{
"token" : "中",
"start_offset" : 3,
"end_offset" : 4,
"type" : "",
"position" : 3
},
{
"token" : "国",
"start_offset" : 4,
"end_offset" : 5,
"type" : "",
"position" : 4
},
{
"token" : "人",
"start_offset" : 5,
"end_offset" : 6,
"type" : "",
"position" : 5
}
]
}
然后使用IK分词器测试中文分词效果。
[root@bigdata01 soft]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/emp/_analyze?pretty' -d '{"text":"我们是中国人","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "我们",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 4
}
]
}
在这里我们发现分出来的单词里面有一个 是,这个单词其实可以认为是一个停用词,在分词的时候是不需要切分出来的。
在这被切分出来了,那也就意味着在进行停用词过滤的时候没有过滤掉。
针对ik这个词库而言,它的停用词词库里面都有哪些单词呢?
[root@bigdata01 elasticsearch-7.13.4]# cd config/analysis-ik/
[root@bigdata01 analysis-ik]# ll
total 8260
-rwxrwxrwx. 1 root root 5225922 Feb 27 20:57 extra_main.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word.dic
-rwxrwxrwx. 1 root root 63188 Feb 27 20:57 extra_single_word_full.dic
-rwxrwxrwx. 1 root root 10855 Feb 27 20:57 extra_single_word_low_freq.dic
-rwxrwxrwx. 1 root root 156 Feb 27 20:57 extra_stopword.dic
-rwxrwxrwx. 1 root root 625 Feb 27 20:57 IKAnalyzer.cfg.xml
-rwxrwxrwx. 1 root root 3058510 Feb 27 20:57 main.dic
-rwxrwxrwx. 1 root root 123 Feb 27 20:57 preposition.dic
-rwxrwxrwx. 1 root root 1824 Feb 27 20:57 quantifier.dic
-rwxrwxrwx. 1 root root 164 Feb 27 20:57 stopword.dic
-rwxrwxrwx. 1 root root 192 Feb 27 20:57 suffix.dic
-rwxrwxrwx. 1 root root 752 Feb 27 20:57 surname.dic
[root@bigdata01 analysis-ik]# more stopword.dic
a
an
and
are
as
at
be
but
by
for
if
in
into
is
it
no
not
of
on
or
ik的停用词词库是stopword.dic这个文件,这个文件里面目前都是一些英文停用词。
我们可以手工在这个文件中把中文停用词添加进去,先添加 是 这个停用词。
[root@bigdata01 analysis-ik]# vi stopword.dic
.....
是
然后把这个文件的改动同步到集群中的所有节点上。
[root@bigdata01 analysis-ik]# scp -rq stopword.dic bigdata02:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
[root@bigdata01 analysis-ik]# scp -rq stopword.dic bigdata03:/data/soft/elasticsearch-7.13.4/config/analysis-ik/
重启集群让配置生效。
先停止bigdata01、bigdata02、bigdata03上的ES服务。
[root@bigdata01 analysis-ik]# jps
3051 Elasticsearch
3358 Jps
[root@bigdata01 analysis-ik]# kill 3051
[root@bigdata02 analysis-ik]$ jps
2496 Elasticsearch
2570 Jps
[root@bigdata02 analysis-ik]$ kill 2496
[root@bigdata03 analysis-ik]$ jps
2481 Jps
2412 Elasticsearch
[root@bigdata03 analysis-ik]$ kill 2412
启动bigdata01、bigdata02、bigdata03上的ES服务。
[es@bigdata01 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata02 elasticsearch-7.13.4]$ bin/elasticsearch -d
[es@bigdata03 elasticsearch-7.13.4]$ bin/elasticsearch -d
再使用IK分词器测试一下中文分词效果。
[root@bigdata01 analysis-ik]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test/_analyze?pretty' -d '{"text":"我们是中国人","tokenizer":"ik_max_word"}'
{
"tokens" : [
{
"token" : "我们",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国人",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中国",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "国人",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
}
]
}
此时再查看会发现没有"是" 这个单词了,相当于在过滤停用词的时候把它过滤掉了。




