0.摘要
基于 3D视觉的新兴应用场景蓬勃发展,3D点云越来越受到人们的广泛关注。点云有着广泛的应用领域包括机器人技术、3D图形、自动驾驶、虚拟现实(AR/VR/MR)等。为了跟上不断增长的应用需要,研究和开发有效存储、处理的相关算法来处理点云的意义正显著上升。传统的分析算法处理点云,主要侧重于对点的局部几何特征进行编码。深度学习在图像数据处理领域取得了巨大的成功,这使得研究相应的点云神经网络结构有极其现实的迫切需求。当前的研究热点主要涉及发展用于各种点云处理任务的深度神经网络。
1. 3D点云数据
1.1 3D点云定义
3D数据的表述形式一般分为以下四种:
a) 点云:由N 个D维的点组成,当这个D =3的时候一般代表着(x,y,z)的坐标,当然也可以包括一些法向量、强度等别的特征。这是今天主要讲述的数据类型。
b) Mesh:由三角面片和正方形面片组成。
c) 体素:由三维栅格将物体用0和1表征。
d) 多角度的RGB图像或者RGB-D图像
3D 点云是三维空间中的点的数据集, 点云用来表示对象的 3D 表面。 每个点由三个坐标(X,YZ)组成唯一标识其相对于正交轴的位置。通常,R、G、B 颜色值和表面法线等附加信息也可以嵌入为点属性,具体取决于用于捕获点的传感器。 通常意义上的点云包含大量的点(成千上万甚至更多)。 与采用规则网格表示的 2D 图像不同,3D 点云是无组织的,没有特定的顺序。 这种无序的性质使得在处理点云和设计方法时需考虑其特殊性。
1.2 点云数据的获取
3D 点云的形成与 2D 图像的形成方式显著不同。 2D 图像是一种光学现象,对于来自环境的光线使用镜头捕获,该镜头在 2D 图像平面上产生倒置图像,然后调整形成正立图像。相比之下,通常使用 LiDAR 传感器获取 3D 点云。 激光雷达(LiDAR)代表光检测和测距。 与之类似的传感器有雷达和声纳。 雷达和声纳使用无线电波和声波,激光雷达则使用光波,通常使用近红外波段光,避开人肉眼可识别的可见光。 激光雷达由三个主要部件:发射器、旋转器和光电探测器组成,示意图如下。
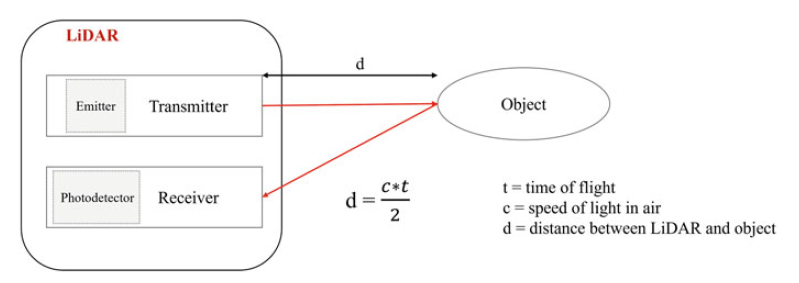
具体原理如下:激光雷达发射高密度的激光束,光束沿直行传播打到物体的表面,然后以相同的方向反射回去(忽略少量光线发生衍射现象),反射回去的光线由光电探测器(光敏传感器)检测收集,结合激光束往返传播的距离与方向信息就可以生成物体的3D几何形状。实际在使用过程中,激光发射器置于连续旋转的底座上,从而使得发射的激光束能以不同方向到达物体表面(前、后、左、右)。
1.3 3D点云数据主要特点
与传统2D图像数据相比,3D点云的主要特点对比如下。
| 2D 图像 | 3D点云 | |
| 表现形式 | 3D世界的2D投影,不包含Z值 | 3D数据,包含Z值 |
| 数据结构 | 有序,依次连接 | 各数据点无序 |
| 环境敏感性 | 对环境光照条件敏感 | 对环境光照条件不敏感 |
| 处理方法 | 直接使用CNN等 | 不能直接使用CNN |
2. 点云数据处理
对于点云数据的处理,主要涉及点云滤波、点云配准、点云分类、点云语义分割、点云目标识别等。
2.1 点云滤波(数据预处理)
点云滤波,顾名思义,就是滤掉噪声。原始采集的点云数据往往包含大量散列点、孤立点,比如下图为滤波前后的点云效果对比。

点云滤波的主要方法有:双边滤波、高斯滤波、条件滤波、直通滤波、随机采样一致滤波、VoxelGrid滤波等,这些算法都被封装在了PCL点云库中。
2.2 特征与特征描述
如果要对一个三维点云进行描述,光有点云的位置还不够,常常需要计算一些额外的参数,比如法线方向、曲率、文理特征等等。如同图像的特征一样,我们需要使用类似的方式来描述三维点云的特征。
常用的特征描述算法:法线和曲率计算及特征值分析、PFH、FPFH、3D Shape Context、Spin Image等。
PFH:点特征直方图描述子,FPFH:跨苏点特征直方图描述子,FPFH是PFH的简化形式。
2.3 点云关键点提取
在二维图像上,有Harris、SIFT、SURF、KAZE这样的关键点提取算法,将特征点的思想推广到三维空间。从技术上来说,关键点的数量相比于原始点云或图像的数据量减小很多,与局部特征描述子结合在一起,组成关键点描述子用来形成原始数据的表示,而且不失代表性和描述性,从而加快了后续的识别,追踪等对数据的处理速度,关键点技术成为在2D和3D 信息处理中非常关键的技术。
常见的三维点云关键点提取算法有一下几种:ISS3D、Harris3D、NARF、SIFT3D
这些算法在PCL库中都有实现,其中NARF算法应用较为常见。
2.4 点云配准
点云配准的概念也可以类比于二维图像中的配准,相比二维图像配准获取得到的是x,y,alpha,beta等放射变化参数,二三维点云配准可以模拟三维点云的旋转和移动,也就是会获得一个旋转矩阵和一个平移向量,通常表达为一个4×3的矩阵,其中3×3是旋转矩阵,1*3是平移向量。严格说来是6个参数,因为旋转矩阵也可以通过罗格里德斯变换转变成1*3的旋转向量。
常用的点云配准算法有两种:正太分布变换和著名的ICP点云配准,此外还有许多其它算法,列举如下:
ICP:稳健ICP、point to plane ICP、point to line ICP、MBICP、GICP
NDT 3D、Multil-Layer NDT
FPCS、KFPSC、SAC-IA
Line Segment Matching、ICL
2.5 点云分割与分类
点云的分割与分类处理比二维图像的处理复杂很多,点云分割又分为区域提取、线面提取、语义分割与聚类等。同样是分割问题,点云分割涉及面太广,一般说来,点云分割是目标识别的基础。
分割:区域声场、Ransac线面提取、NDT-RANSAC、K-Means、Normalize Cut、3D Hough Transform(线面提取)、连通分析
分类:基于点的分类,基于分割的分类,监督分类与非监督分类。
2.6 目标识别与检测
这是点云数据处理中一个偏应用层面的问题,简单说来就是Hausdorff距离常被用来进行深度图的目标识别和检测,现在很多三维人脸识别都采用这种技术。
2.7 SLAM图优化
SLAM技术中,在图像前端主要获取点云数据,而在后端优化主要就是依靠图优化工具。而SLAM技术近年来的发展也已经改变了这种技术策略。在过去的经典策略中,为了求解LandMark和Location,将它转化为一个稀疏图的优化,常常使用g2o工具来进行图优化。常用的工具和方法如下。
g2o、LUM、ELCH、Toro、SPA
SLAM方法:ICP、MBICP、IDC、likehood Field、 Cross Correlation、NDT
2.8 变化检测
当无序点云在连续变化中,八叉树算法常常被用于检测变化,这种算法需要和关键点提取技术结合起来,八叉树算法也算是经典中的经典了。
2.9 三维重建
获取到的点云数据都是一个个孤立的点,从一个个孤立的点得到整个曲面就是三维重建的问题。
直接采集到的点云是充满噪声和孤立点的,三维重建算法为了重构出曲面,常常要应对这种噪声,获得看上去很光滑的曲面。
常用的三维重建算法和技术有:
泊松重建、Delauary triangulatoins
表面重建,人体重建,建筑物重建,输入重建
实时重建:重建纸杯或者龙作物4D生长台式,人体姿势识别,表情识别
3. 点云数据集
已有的3D点云数据集主要有ModelNet40,ShapeNet,S3DIS,3D Match,KITTI,其中前3者主要应用于CAD模型,室内建筑物分割,室内场景配准等,KITTI数据集主要应用于自动驾驶、ADAS、外部场景视觉SLAM等。
4. 基于点云数据的目标识别
针对当前视觉SLAM采集的数据,下文重点对比点云数据的目标识别方法,包括传统方法和深度学习方法。
4.1 传统方法
1) 基于边缘的方法
检测点强度快速变化的边缘。这些边通常是点云中不同区域的边界。因此,点云的区域被分割。
2) 基于区域的方法
首先搜索邻域。附近的点具有相似模式的区域被组合成孤立区域,然后是发现不同区域之间的差异。
3)基于属性的方法
首先计算点云数据的属性,然后基于属性对点云进行聚类。
4.基于模型的方法
该方法是纯几何的。相同的点数学表示为几何形状,如球体、圆锥体、平面和圆柱体被分组为一个段。
5) 基于图的方法
将点云视为图。一个简单的模型是每个顶点对应一个点,边连接到特定的点与邻近点。
一般来说,分割点云有两个传统的分支。这个首先涉及纯数学模型和几何推理技术比如区域生长或模型拟合。第二个是3D图像的提取,使用特征描述符的特征和使用机器的对象类别分类学习技巧。
第一种方法提供了更快的计算速度,但它只适用于简单的场景。因此,第二种方法更为有效通常在实践中使用,通常表现更好。考虑到第二种方法,分割通常被表述为逐点分类问题。每个点首先由特征描述符描述例如FPFH或SHOT,它们依靠手工设计特征和点的局部几何特性。然后,提取特征被连接到特征向量并输入到分类器中,如支持向量机机器(SVM)和随机森林(RF)。
4.2深度学习方法
目前对于点云数据的分类与分割,深度学习方法已经成为主流。比较常用的有PointNet,PointNet++, DGCNN, PointCNN, PointSIFT, Point Transformer, and RandLANet等。其中以前两者应用居多。
1)PointNet
PointNet 网络结构如下所示。
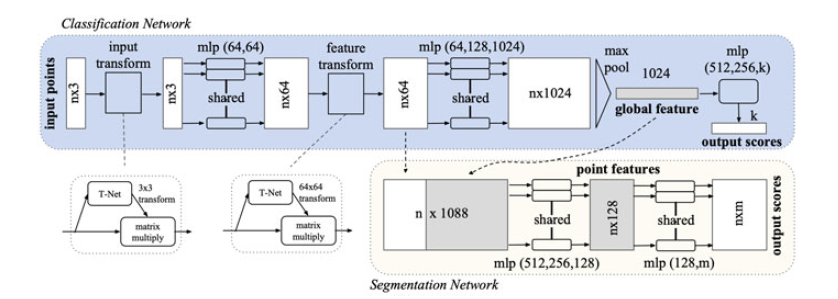
由图可以看出,由于点云的旋转非常的简单,只需要对一个N×D的点云矩阵乘以一个D×D的旋转矩阵即可,因此对输入点云学习一个3×3的矩阵,即可将其矫正;同样的将点云映射到K维的冗余空间后,再对K维的点云特征做一次校对,只不过这次校对需要引入一个正则化惩罚项,希望其尽可能接近于一个正交矩阵。
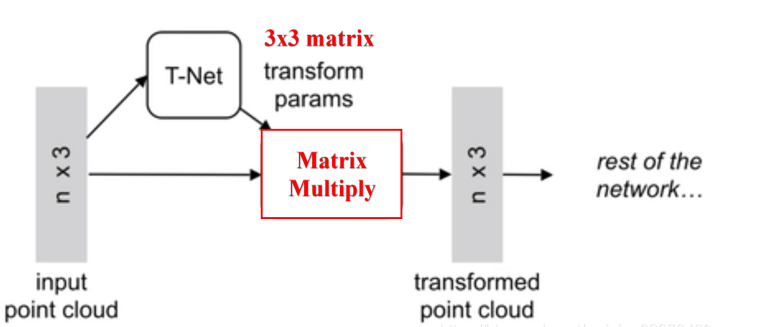
具体来说,对于每一个N×3的点云输入,对应于原始N个点的3D坐标信息,网络先通过一个T-Net将其在空间上对齐(旋转到正面),其中T-Net就像一个迷你型-point-net网络,可学习得到3×3仿射变换矩阵。再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的1×1024的向量就是N个点云的全局特征。
如果做的是分类的问题,直接将这个全局特征再进过MLP去输出每一类的概率即可;但如果是分割问题,由于需要输出的是逐点的类别,因此其将全局特征拼接在了点云64维的逐点特征上,网络能够同时利用局部和全局特征的几何和全局语义,最后通过MLP,输出逐点的分类概率。
2)PointNet++
从很多实验结果都可以看出,PointNet对于场景的分割效果十分一般,由于其网络直接暴力地将所有的点最大池化为了一个全局特征,因此局部点与点之间的联系并没有被网络学习到。在分类和物体的Part Segmentation中,这样的问题还可以通过中心化物体的坐标轴部分地解决,但在场景分割中,这就导致效果十分一般了。
进一步地研究人员提出了一个分层特征学习框架PointNet++来解决这个问题,从而改善PointNet的一些局限性。分层学习过程是通过一系列设定的抽象级别。每个集合抽象级别由一个采样组层、分组层和PointNet层。PointNet++网络结构
如下所示。
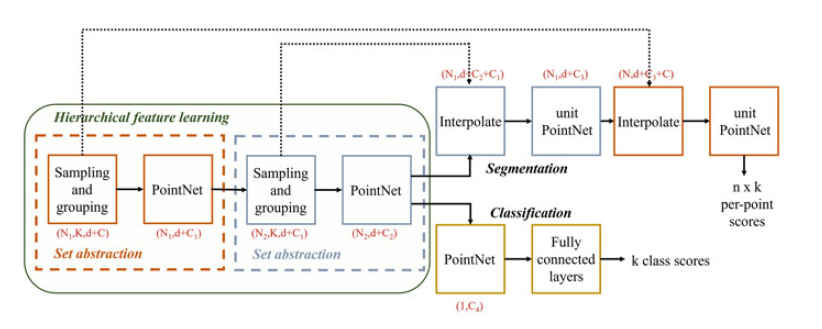
PointNet++中主要借鉴了CNN的多层感受野的思想。CNN通过分层不断地使用卷积核扫描图像上的像素并做内积,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。而PointNet++就是仿照了这样的结构,具体如下:
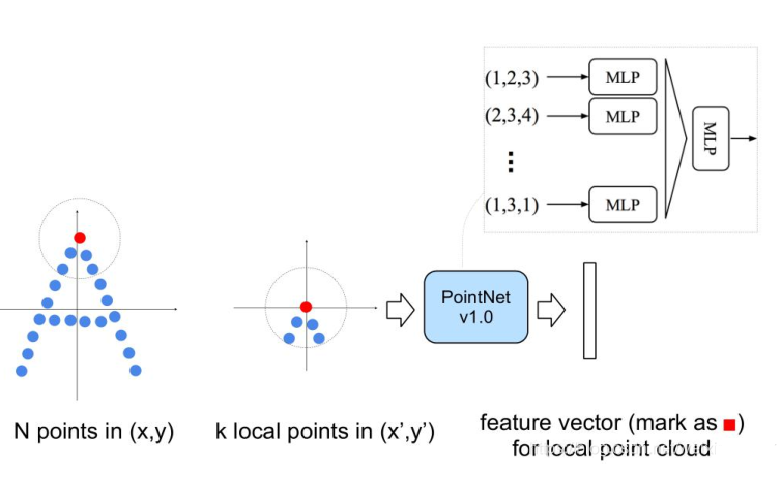
其先通过在整个点云的局部采样并划一个范围,将里面的点作为局部的特征,用PointNet进行一次特征的提取。因此,通过了多次这样的操作以后,原本的点的个数变得越来越少,而每个点都是有上一层更多的点通过PointNet提取出来的局部特征,也就是每个点包含的信息变多了。文章将这样的一个层成为Set Abstraction。
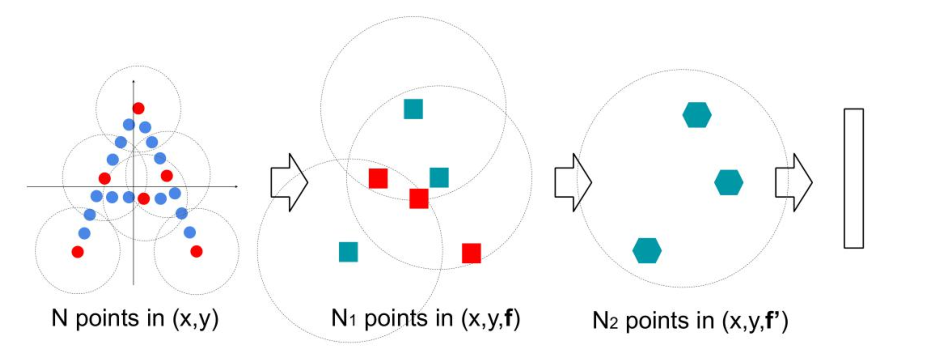
一个Set Abstraction主要由三部分组成:
- Sampling:利用FPS(最远点采样)随机采样点
- Grouping:利用Ball Query划一个R为半径的圈,将每个圈里面的点云作为一簇
- PointNet: 对Sampling+Grouping以后的点云进行局部的全局特征提取
3)DGCNN
4)PointCNN
5)PointSIFT
6) Point Transformer
7)RandLANet
5. 参考文献
1.3D Point Cloud Analysis_ Traditional, Deep Learning, and Explainable Machine Learning Methods
2.A comprehensive survey on point cloud registration
3.PointNet-Deep Learning on Point Sets for 3D Classification and Segmentation
4.RandLA-Net Efficient Semantic Segmentation of Large-Scale Point Clouds




