论文名称:Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
论文下载:https://dl.acm.org/doi/abs/10.1145/3209978.3210006
论文年份:SIGIR 2018
论文被引:594(2022/04/21)
论文代码:https://github.com/laiguokun/LSTNet
论文数据:https://github.com/laiguokun/multivariate-time-series-data
ABSTRACT
Multivariate time series forecasting is an important machine learning problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. Temporal data arise in these real-world applications often involves a mixture of long-term and short-term patterns, for which traditional approaches such as Autoregressive models and Gaussian Process may fail. In this paper, we proposed a novel deep learning framework, namely Long- and Short-term Time-series network (LSTNet), to address this open challenge. LSTNet uses the Convolution Neural Network (CNN) and the Recurrent Neural Network (RNN) to extract short-term local dependency patterns among variables and to discover long-term patterns for time series trends. Furthermore, we leverage traditional autoregressive model to tackle the scale insensitive problem of the neural network model. In our evaluation on real-world data with complex mixtures of repetitive patterns, LSTNet achieved significant performance improvements over that of several state-of-the-art baseline methods. All the data and experiment codes are available online.
【现实意义】
多变量时间序列预测是跨多个领域的重要机器学习问题,包括太阳能发电厂能量输出、电力消耗和交通拥堵情况的预测。
【存在问题】
在这些实际应用中出现的时间数据通常涉及长期和短期模式的混合,对于这些模式,自回归模型和高斯过程等传统方法可能会失败。
【解决方案】
在本文中,我们提出了一种新颖的深度学习框架,即长期和短期时间序列网络 (Long- and Short-term Time-series network, LSTNet),以应对这一开放挑战。 LSTNet 使用卷积神经网络 (CNN) 和循环神经网络 (RNN) 来提取变量之间的短期局部依赖模式,并发现时间序列趋势的长期模式。此外,我们利用传统的自回归模型来解决神经网络模型的尺度不敏感问题。
【实验结果】
在我们对具有重复模式的复杂混合的现实世界数据的评估中,LSTNet 比几种最先进的基线方法实现了显着的性能改进。所有数据和实验代码均可在线获取。
1 INTRODUCTION
【现实意义】
多元时间序列数据在我们的日常生活中无处不在,从股票市场的价格、高速公路上的交通流量、太阳能发电厂的输出、不同城市的温度等等,不一而足。在此类应用中,用户通常对基于对时间序列信号的历史观察预测新趋势或潜在危险事件感兴趣。例如,可以根据提前几个小时预测的交通拥堵模式制定更好的路线计划,通过对近期股市的预测获得更大的利润。
【存在问题】
多元时间序列预测经常面临一个重大的研究挑战,即如何捕捉和利用多个变量之间的动态依赖关系。具体来说,现实世界的应用程序通常需要混合使用短期和长期重复模式。
【举例说明】
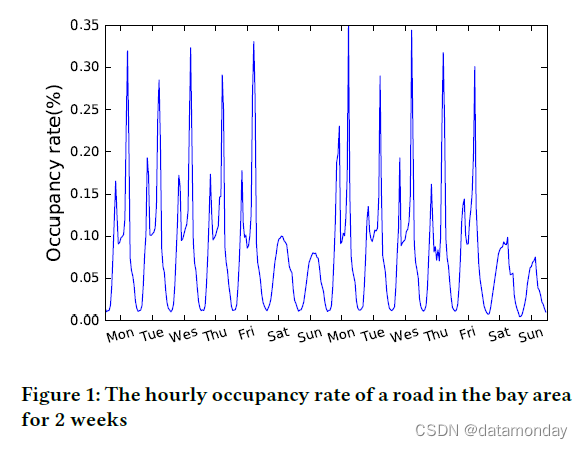
- 如图 1 所示,该图绘制了高速公路的每小时占用率。显然,有两种重复模式,每天和每周。前者描绘了早高峰与晚高峰,而后者则反映了工作日和周末的模式。一个成功的时间序列预测模型应该捕获这两种重复模式以进行准确的预测。
- 另一个例子,基于不同位置的大型传感器测量的太阳辐射来预测太阳能发电厂的输出的任务。长期模式反映白天与黑夜、夏季与冬季等之间的差异,短期模式反映云运动、风向变化等的影响。同样,没有考虑这两种循环模式,准确的时间序列预测是不可能的。
【已有研究的局限性】
然而,传统方法,如自回归方法 [2, 12, 22, 32, 35] 中的大量工作在这方面存在不足,因为它们中的大多数没有区分这两种模式,也没有明确和动态地模拟它们的交互。解决现有方法在时间序列预测中的这些局限性是本文的主要重点,为此我们提出了一个新的框架,该框架利用了深度学习研究的最新发展。
【从粗粒度上阐述与本文相关的工作,本文是RNN和CNN】
深度神经网络已在相关领域得到深入研究,并对广泛问题的解决产生了非凡的影响。例如,递归神经网络 (RNN) 模型 [9] 在最近的自然语言处理 (NLP) 研究中变得最流行。特别是 RNN 的两个变体,即长短期记忆 (LSTM) [15] 和门控循环单元 (GRU) [6],显着提高了机器翻译、语音识别和其他 NLP 任务,因为它们可以根据输入文档中单词之间的长期和短期依赖关系有效地捕捉单词的含义 [1, 14, 19]。在计算机视觉领域,再举一个例子,卷积神经网络(CNN) 模型 [19, 21] 通过从输入图像中成功提取各种粒度级别的局部和移位不变特征(有时称为“shapelets”),显示出出色的性能。
【进一步阐述RNN和CNN应用于时间序列领域(分类,回归)的研究】
深度神经网络在时间序列分析中也受到越来越多的关注。先前工作的很大一部分都集中在时间序列分类上,即自动将类标签分配给时间序列输入的任务。例如,RNN 架构已被研究用于从医疗保健序列数据中提取信息模式 [5, 23],并根据诊断类别对数据进行分类。 RNN 也被应用于移动数据,用于根据动作或活动对输入序列进行分类 [13]。 CNN 模型也被用于动作/活动识别 [13, 20, 31],用于从输入序列中提取移位不变的局部模式作为分类模型的特征。
深度神经网络也被研究用于时间序列预测 [8, 33],即使用过去观察到的时间序列来预测前瞻视野中的未知时间序列的任务——视野越大,越难预测。在这个方向上的努力范围从早期使用朴素 RNN 模型 [7] 和结合使用 ARIMA [3] 和多层感知器 (MLP) 的混合模型 [16, 34, 35] 到最近将 vanilla RNN 和时间序列预测中的动态玻尔兹曼机[8]。
【最后引出本文的解决方案及实验结果】
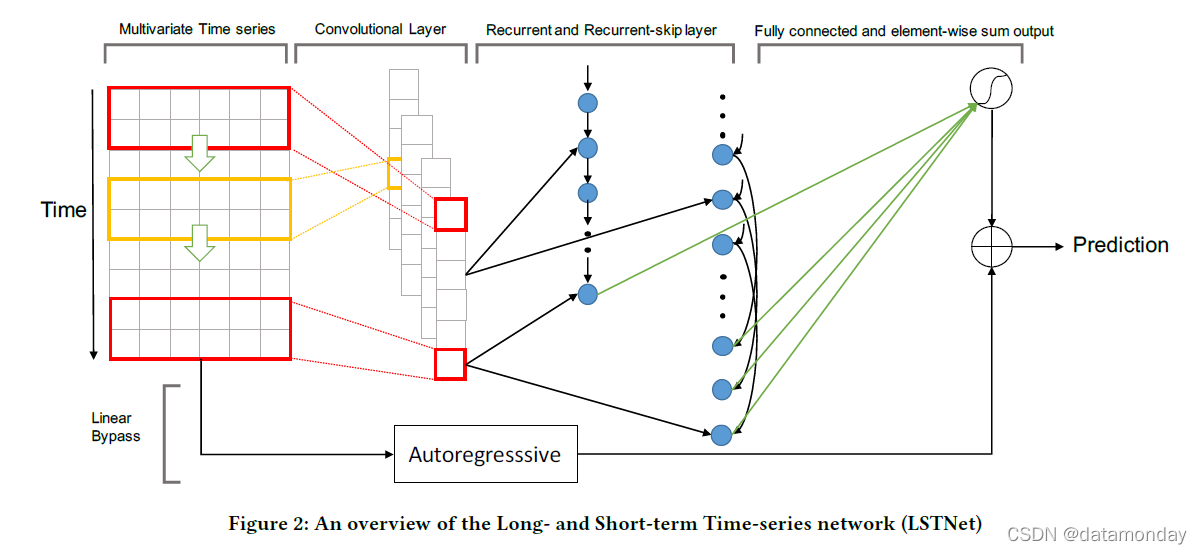
在本文中,我们提出了一个为多元时间序列预测设计的深度学习框架,即长期和短期时间序列网络 (LSTNet),如图 2 所示。
- 利用两个卷积层的优势来发现局部多维输入变量和循环层之间的依赖模式,以捕获复杂的长期依赖关系。
- 一种新颖的循环结构 Recurrent-skip,旨在捕获非常长期的依赖模式,并使优化更容易,因为它利用了输入时间序列信号的周期性属性。
- 最后,LSTNet 将传统的自回归线性模型与非线性神经网络部分并行合并,使得非线性深度学习模型对于违反尺度变化的时间序列更加鲁棒。
在真实世界季节性时间序列数据集的实验中,我们的模型始终优于传统的线性模型和 GRU 递归神经网络。
【本文剩余部分内容的组织】
本文的其余部分安排如下。第 2 节概述了相关背景,包括具有代表性的自回归方法和高斯过程模型。第 3 节描述了我们提出的 LSTNet。第 4 节报告了我们模型的评估结果,并与真实数据集上的强基线进行了比较。最后,我们在第 5 节总结我们的发现。
2 RELATED BACKGROUND
【ARIMA模型家族的优缺点】
自回归综合移动平均 (autoregressive integrated moving average , ARIMA) 模型:最突出的单变量时间序列模型之一。
优点:其统计特性以及模型选择过程中著名的 Box-Jenkins 方法 [2]。 ARIMA 模型不仅适用于各种指数平滑技术 [25],而且足够灵活,可以包含其他类型的时间序列模型,包括:
- 自回归 (autoregression, AR)
- 移动平均 (moving average, MA)
- 自回归移动平均 (Autoregressive Moving Average, ARMA)
缺点:ARIMA 模型,包括它们用于建模长期时间依赖关系的变体 [2],由于其高计算成本而很少用于高维多元时间序列预测。
【VAR模型家族的优缺点】
向量自回归 (vector autoregression, VAR):由于其简单性,是多元时间序列 [2, 12, 24] 中使用最广泛的模型。 VAR 模型自然地将 AR 模型扩展到多变量设置,它忽略了输出变量之间的依赖关系。
近年来,各种 VAR 模型取得了重大进展,包括:
- elliptical VAR model [27]:用于长尾时间序列
- structured VAR model [26]:用于更好地解释高维变量之间依赖关系
然而,VAR 的模型容量在时间窗口大小上呈线性增长,在变量数量上呈二次方增长。这意味着,在处理长期时间模式时,继承的大模型容易过拟合。为了缓解这个问题,[32] 提出将原始高维信号减少为低维隐藏表示,然后应用 VAR 进行预测,并选择多种正则化。
【线性回归+正则化的模型的优缺点】
时间序列预测问题也可以被视为具有时变参数的标准回归问题。因此,可以很自然地将具有不同损失函数和正则化项的各种回归模型应用于时间序列预测任务。例如:
- 线性支持向量回归 (SVR) [4, 17] 基于回归损失学习最大边距超平面,其中超参数 ϵ 控制预测误差的阈值。
- 岭回归(Ridge regression)可以通过将 ϵ 设置为零来从 SVR 模型中恢复。
- [22] 应用 LASSO 模型来鼓励模型参数的稀疏性,以便可以显示不同输入信号之间的有趣模式。
由于机器学习社区中有高质量的现成求解器,这些线性方法实际上对于多变量时间序列预测更有效。尽管如此,与 VAR 一样,这些线性模型可能无法捕捉多元信号的复杂非线性关系,从而以牺牲效率为代价导致性能下降。
【高斯过程的优缺点】
高斯过程 (GP) 是一种用于对函数连续域上的分布进行建模的非参数方法。这与由诸如 VAR 和 SVR 等参数化函数类定义的模型形成对比。
- [28] 中GP 可以应用于多元时间序列预测任务,并且可以用作贝叶斯推理中函数空间的先验。
- [10] 提出了一种具有 GP 先验的完全贝叶斯方法,用于非线性状态空间模型,能够捕捉复杂的动态现象。
然而,高斯过程的性能以高计算复杂度为代价。由于核矩阵的矩阵求逆,多变量时间序列预测的高斯过程的直接实现在观测数上具有三次复杂度。
3 FRAMEWORK
在本节中,我们首先制定时间序列预测问题,然后在下一部分讨论所提出的 LSTNet 架构(图 2)的细节。最后,我们介绍了目标函数和优化策略。
3.1 Problem Formulation
在本文中,我们对多元时间序列预测的任务感兴趣。更正式地说,给定一系列完全观察到的时间序列信号 Y = y 1 , y 2 , . . . , y T Y = {y_1,y_2, ...,y_T } Y=y1,y2,...,yT 其中 y t ∈ R n y_t ∈ R^n yt∈Rn, n n n 是变量维度,我们旨在以滚动预测方式预测一系列未来信号。话虽如此,为了预测 y T + h y_{T +h} yT+h,其中 h h h 是当前时间戳之前的理想范围,我们假设 { y 1 , y 2 , . . . , y T } {y_1,y_2, . . . ,y_T} {y1,y2,...,yT} 可用。同样,为了预测下一个时间戳 y T + h + 1 y_{T+h+1} yT+h+1 的值,我们假设 { y 1 , y 2 , . . . , y T , y T + 1 } {y_1,y_2, . . . ,y_T ,y_{T +1}} {y1,y2,...,yT,yT+1} 可用。因此,我们将时间戳 T T T 处的输入矩阵表示为 X T = { y 1 , y 2 , . . . , y T } ∈ R n × T X_T = {y_1,y_2, . . . ,y_T } ∈ R^{n×T} XT={y1,y2,...,yT}∈Rn×T。
在大多数情况下,预测任务的范围是根据环境设置的要求来选择的,例如对于流量使用,感兴趣的范围从几小时到一天不等;对于股市数据,即使是提前几秒/分钟的预测对于产生回报也很有意义。
图 2 概述了建议的 LSTnet 架构。 LSTNet 是一个深度学习框架,专为混合长期和短期模式的多变量时间序列预测任务而设计。在接下来的部分中,我们将详细介绍 LSTNet 的构建块。
3.2 Convolutional Component
LSTNet 第一层是一个没有池化的卷积网络,旨在提取时间维度上的短期模式以及变量之间的局部依赖关系。卷积层由多个宽度为 ω 和高度为 n 的滤波器组成(高度设置为与变量个数相同)。第 k 个滤波器扫描输入矩阵 X 并产生
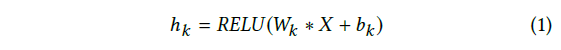
其中 * 表示卷积运算,输出 hk 将是一个向量,RELU 函数为 RELU (x) = max(0, x)。我们通过在输入矩阵 X 的左侧进行零填充来使每个向量 hk 的长度为 T 。卷积层的输出矩阵大小为 dc × T,其中 dc 表示滤波器的数量。
3.3 Recurrent Component
卷积层的输出同时被馈送到 Recurrent 组件和 Recurrent-skip 组件(将在 3.4 小节中描述)。循环组件是一个带有门控循环单元 (GRU) [6] 的循环层,并使用 RELU 函数作为隐藏更新激活函数。在时间 t 的循环单元的隐藏状态计算为:
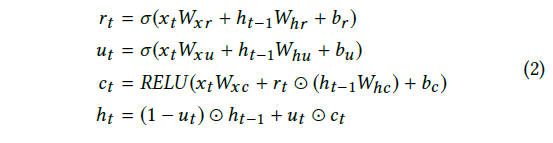
其中 ⊙ 是元素乘积(element-wise product),σ 是 sigmoid 函数,xt 是该层在时间 t 的输入。该层的输出是每个时间戳的隐藏状态。虽然研究人员习惯于使用 tanh 函数作为隐藏更新激活函数,但我们凭经验发现 RELU 导致更可靠的性能,通过它梯度更容易反向传播。
3.4 Recurrent-skip Component
带有 GRU [6] 和 LSTM [15] 单元的循环层经过精心设计,可以记住历史信息,从而了解相对长期的依赖关系。然而,由于梯度消失,GRU 和 LSTM 在实践中通常无法捕捉到非常长期的相关性。我们建议通过一种新颖的循环跳过组件来缓解这个问题,该组件利用现实世界集中的周期性模式。例如,每天的用电量和交通使用量都呈现出明显的规律。如果我们想预测今天 2 点的用电量,季节性预测模型中的一个经典技巧是利用历史日期中的 2 点记录,以及最近的记录。由于一个周期(24 小时)的长度极长以及随后的优化问题,这种类型的依赖关系很难被现成的循环单元捕获。受此技巧有效性的启发,我们开发了一种具有时间跳跃连接的循环结构,以扩展信息流的时间跨度,从而简化优化过程。具体来说,在当前隐藏单元和相邻周期中相同阶段的隐藏单元之间添加跳跃链接。更新过程可以表述为:
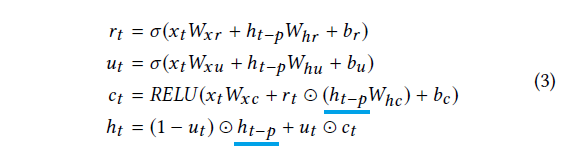
其中该层的输入是卷积层的输出,p 是跳过的隐藏单元的数量。对于具有明确周期性模式的数据集(例如,对于每小时用电量和交通使用数据集,p = 24),p 的值可以很容易地确定,并且必须进行调整。在我们的实验中,我们凭经验发现,即使在后一种情况下,经过良好调整的 p 也可以显着提高模型性能。此外,LSTNet 可以很容易地扩展为包含跳跃长度 p 的变体。
我们使用全连接层来组合 Recurrent 和 Recurrent-skip 组件的输出。全连接层的输入包括:
-
Recurrent 组件在时间戳 t 的隐藏状态,用 h t R h^R_t htR 表示,
-
从时间戳 t − p + 1 t - p + 1 t−p+1 到 t t t 的 Recurrent-skip 组件的 p 个隐藏状态,用 h t − p + 1 S , h t − p + 2 S , . . . , h t S h^S_{t-p+1},h^S_{t-p+2},. . . ,h^S_t ht−p+1S,ht−p+2S,...,htS 表示 。
全连接层的输出计算为:
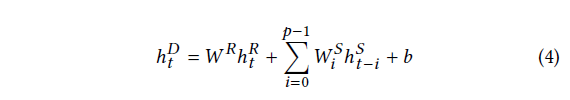
其中 h t D h^D_t htD 是图 2 中神经网络(上)部分在时间戳 t t t 处的预测结果。
3.5 Temporal Attention Layer
然而,Recurrent-skip 层需要一个预定义的超参数 p,这在非季节性时间序列预测中是不利的,或者其周期长度随时间变化。为了缓解这个问题,我们考虑了另一种方法,注意力机制[1],它在输入矩阵的每个窗口位置学习隐藏表示的加权组合。具体来说,当前时间戳 t 处的注意力权重 α t ∈ R q α_t ∈ R^q αt∈Rq 计算为
α t = A t t n S c o r e ( H t R , h t − 1 R ) α_t = AttnScore(H^R_t ,h^R_{t−1}) αt=AttnScore(HtR,ht−1R)
其中 H t R = [ h t − q R , . . . , h t − 1 R ] H^R_t = [h^R_{t−q}, . . . ,h^R_{t−1}] HtR=[ht−qR,...,ht−1R] 是按列堆叠 RNN 的隐藏表示的矩阵,AttnScore 是一些相似函数,例如点积、余弦或由简单的多层感知器参数化。
时间注意层的最终输出是加权上下文向量 c t = H t α t c_t = H_t α_t ct=Htαt 和最后一个窗口隐藏表示 h t − 1 R h^R_{t-1} ht−1R 的连接,以及线性投影操作
h t D = W [ c t ; h t − 1 R ] + b . h^D_t = W [c_t ;h^R_{t−1}] + b. htD=W[ct;h




