原文名称:Attention Is All You Need
原文链接:https://arxiv.org/abs/1706.03762
如果不想看文章的可以看下我在b站上录的视频:https://b23.tv/gucpvt
最近Transformer在CV领域很火,Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完
t
i
t_i
ti时刻后的数据才能计算
t
i
+
1
t_{i+1}
ti+1时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention,所以本文对Self-Attention以及Multi-Head Attention的理论进行详细的讲解。在阅读本文之前,建议大家先去看下李弘毅老师讲的Transformer的内容。本文的内容是基于李宏毅老师讲的内容加上自己阅读一些源码进行的总结。
文章目录
- 前言
- Self-Attention
- Multi-Head Attention
- Self-Attention与Multi-Head Attention计算量对比
- Positional Encoding
- 超参对比
前言
如果之前你有在网上找过self-attention或者transformer的相关资料,基本上都是贴的原论文中的几张图以及公式,如下图,讲的都挺抽象的,反正就是看不懂(可能我太菜的原因)。就像李弘毅老师课程里讲到的"不懂的人再怎么看也不会懂的"。那接下来本文就结合李弘毅老师课上的内容加上原论文的公式来一个个进行详解。
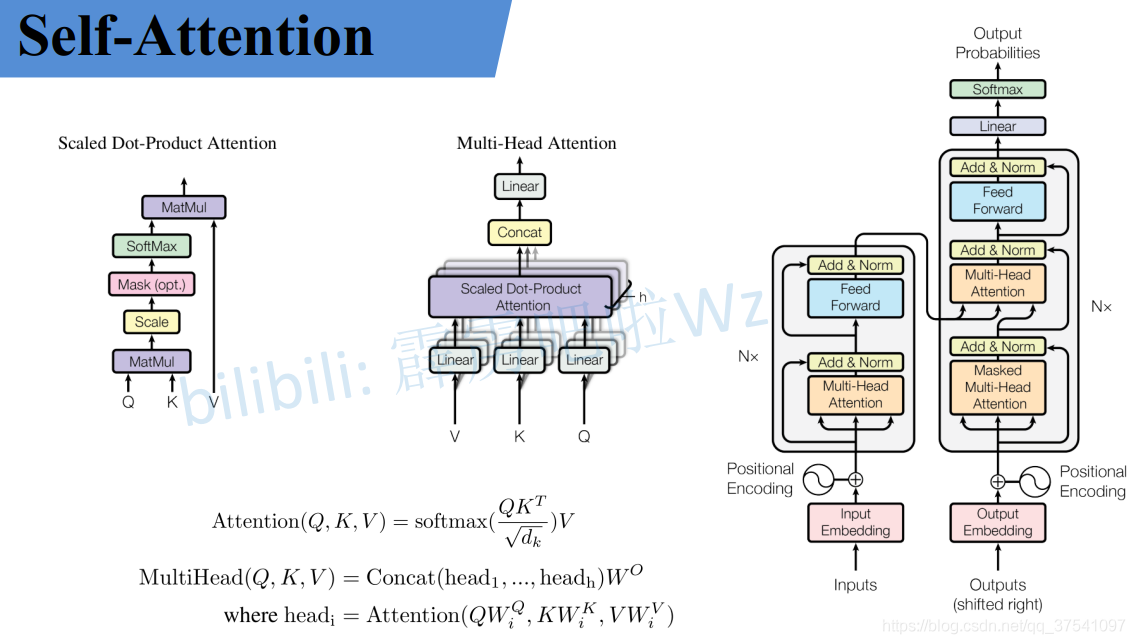
Self-Attention
下面这个图是我自己画的,为了方便大家理解,假设输入的序列长度为2,输入就两个节点 x 1 , x 2 x_1, x_2 x1,x2,然后通过Input Embedding也就是图中的 f ( x ) f(x) f(x)将输入映射到 a 1 , a 2 a_1, a_2 a1,a2。紧接着分别将 a 1 , a 2 a_1, a_2 a1,a2分别通过三个变换矩阵 W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv(这三个参数是可训练的,是共享的)得到对应的 q i , k i , v i q^i, k^i, v^i qi,ki,vi(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)。
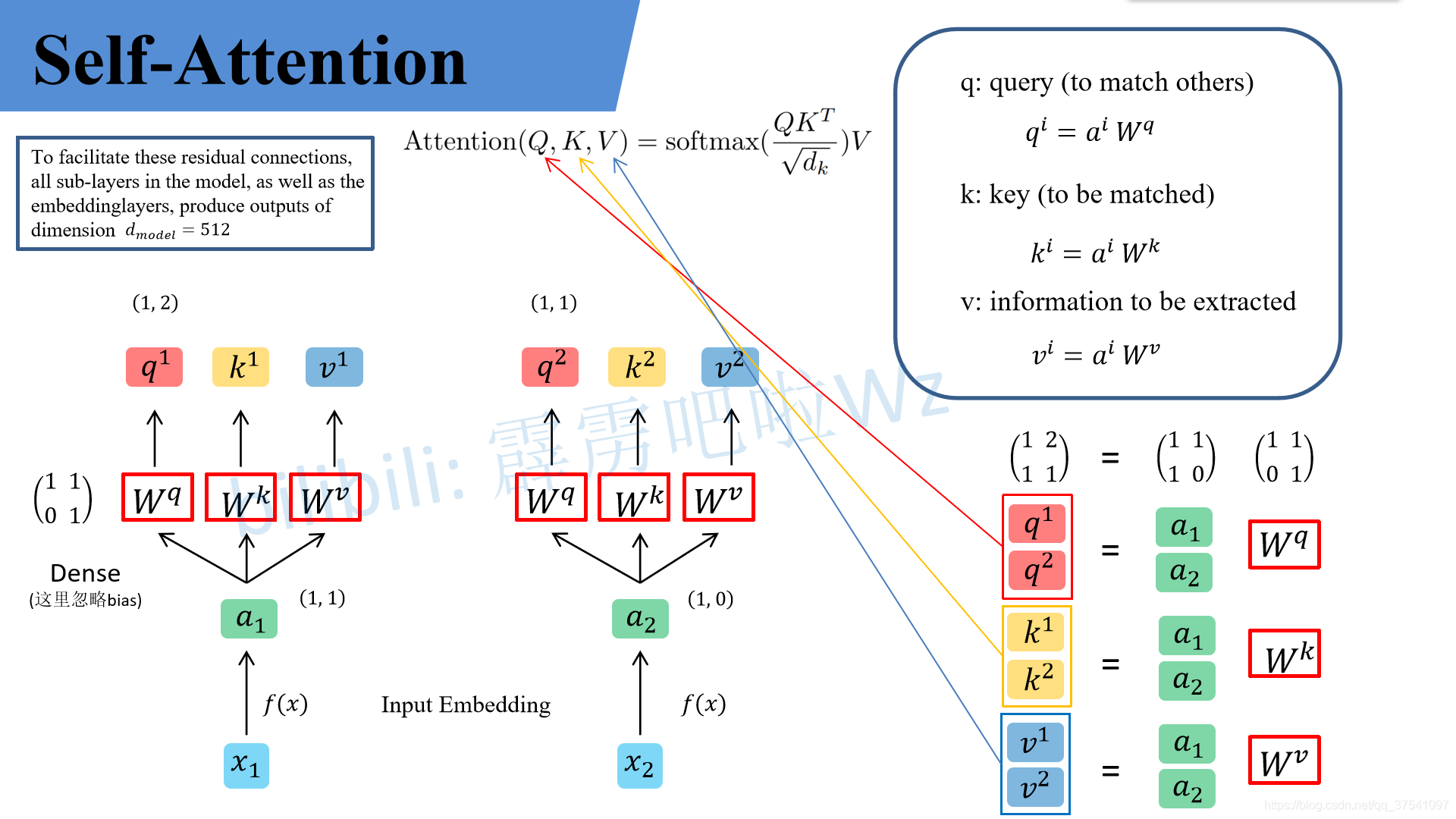
其中
- q q q代表query,后续会去和每一个 k k k进行匹配
- k k k代表key,后续会被每个 q q q匹配
- v v v代表从 a a a中提取得到的信息
- 后续 q q q和 k k k匹配的过程可以理解成计算两者的相关性,相关性越大对应 v v v的权重也就越大
假设
a
1
=
(
1
,
1
)
,
a
2
=
(
1
,
0
)
,
W
q
=
(
1
,
1
0
,
1
)
a_1=(1, 1), a_2=(1,0), W^q= binom{1, 1}{0, 1}
a1=(1,1),a2=(1,0),Wq=(0,11,1)那么:
q
1
=
(
1
,
1
)
(
1
,
1
0
,
1
)
=
(
1
,
2
)
,
q
2
=
(
1
,
0
)
(
1
,
1
0
,
1
)
=
(
1
,
1
)
q^1 = (1, 1) binom{1, 1}{0, 1} =(1, 2) , q^2 = (1, 0) binom{1, 1}{0, 1} =(1, 1)
q1=(1,1)(0,11,1)=(1,2), q2=(1,0)(0,11,1)=(1,1)
前面有说Transformer是可以并行化的,所以可以直接写成:
(
q
1
q
2
)
=
(
1
,
1
1
,
0
)
(
1
,
1
0
,
1
)
=
(
1
,
2
1
,
1
)
binom{q^1}{q^2} = binom{1, 1}{1, 0} binom{1, 1}{0, 1} = binom{1, 2}{1, 1}
(q2q1)=(1,01,1)(0,11,1)=(1,11,2)
同理我们可以得到
(
k
1
k
2
)
binom{k^1}{k^2}
(k2k1)和
(
v
1
v
2
)
binom{v^1}{v^2}
(v2v1),那么求得的
(
q
1
q
2
)
binom{q^1}{q^2}
(q2q1)就是原论文中的
Q
Q
Q,
(
k
1
k
2
)
binom{k^1}{k^2}
(k2k1)就是
K
K
K,
(
v
1
v
2
)
binom{v^1}{v^2}
(v2v1)就是
V
V
V。接着先拿
q
1
q^1
q1和每个
k
k
k进行match,点乘操作,接着除以
d
sqrt{d}
d得到对应的
α
alpha
α,其中
d
d
d代表向量
k
i
k^i
ki的长度,在本示例中等于2,除以
d
sqrt{d}
d的原因在论文中的解释是“进行点乘后的数值很大,导致通过softmax后梯度变的很小”,所以通过除以
d
sqrt{d}
d来进行缩放。比如计算
α
1
,
i
alpha_{1, i}
α1,i:
α
1
,
1
=
q
1
⋅
k
1
d
=
1
×
1
+
2
×
0
2
=
0.71
α
1
,
2
=
q
1
⋅
k
2
d
=
1
×
0
+
2
×
1
2
=
1.41
alpha_{1, 1} = frac{q^1 cdot k^1}{sqrt{d}}=frac{1times 1+2times 0}{sqrt{2}}=0.71 \ alpha_{1, 2} = frac{q^1 cdot k^2}{sqrt{d}}=frac{1times 0+2times 1}{sqrt{2}}=1.41
α1,1=dq1⋅k1=21×1+2×0=0.71




