目录
2-3树 的定义
2-3树 的结点
2-3树 的查找
参考代码
2-3树 的插入
向 2 结点中插入新结点
向 3 结点中插入新结点
图解过程:
参考代码:
2-3树 的删除
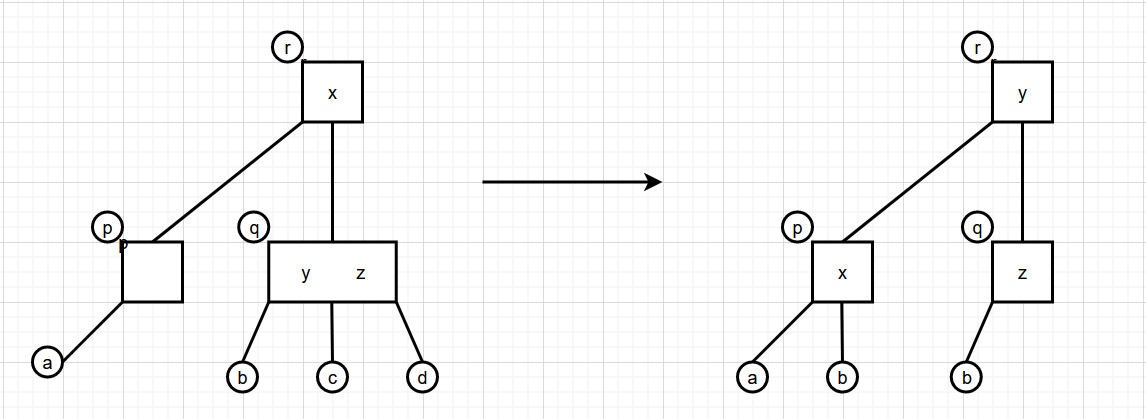
1.p是r的左结点
2.p是r的中结点
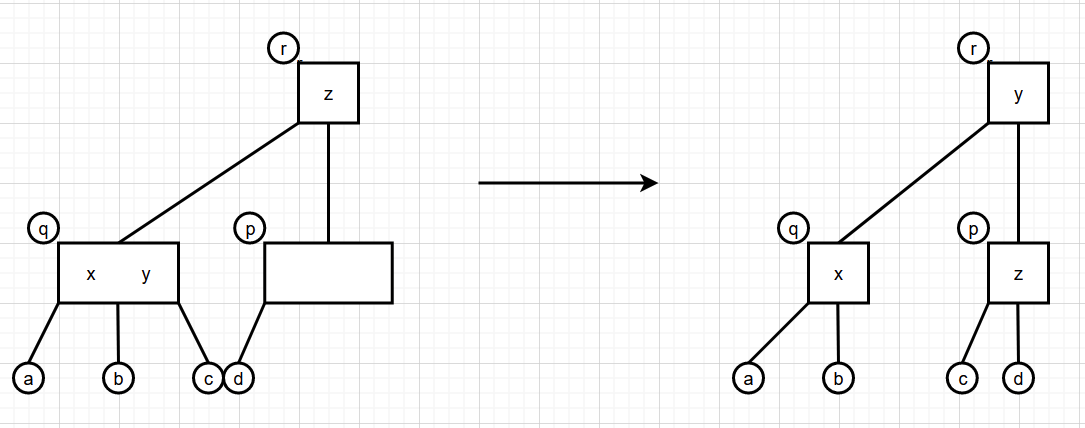
3.p是r的右结点

2-3树 的定义
Q:什么是二叉排序树
A:二叉排序树或者是一棵空树,或者是具有如下性质的二叉树
- 1)若它的左子树不空,则 左子树 上所有结点的值 均小于 它的根结点的值
- 2)若它的右子树不空,则 右子树 上所有结点的值 均大于 它的根结点的值
- 3)左、右子树也分别是一棵二叉排序树
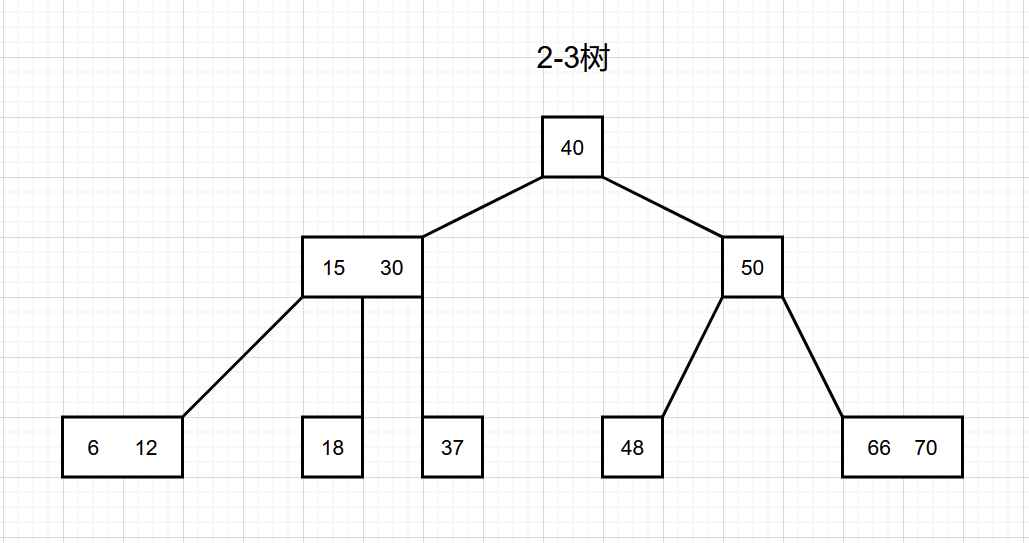
通过引入结点度大于 2 的排序树,可以得到一种插入算法和删除算法都比二叉排序树简单的树结构,且这些算法的时间复杂性仍是 O(logn) 。这种树结构称为2-3树。2-3树的名字反映出 2-3树 具有如下性质: 一棵 2-3树 中的每个内部结点的度或者是2,或者是3。其中度为2的结点称为 2结点,度为3的结点称为 3结点。
Q:什么是2-3树
A:一棵 2-3树(2-3 tree) 是一棵查找树,该查找树或者为空,或者满足如下性质:
- 1)每个内部结点或者是一个 2结点,或者是一个 3结点。一个 2结点 存放一个元素,而一个 3结点 存放两个元素。
- 2)令左孩子和中孩子表示 2结点 的两个儿子。以左孩子为根的子树中所有结点的关键字值都小于该结点元素的关键字,而以中孩子为根的子树中所有结点的关键字值都大于该结点元素的关键字。
- 3)令左孩子,中孩子和右孩子表示 3结点 的三个儿子。且有左孩子结点元素的关键字小于右孩子结点元素的关键字;以左孩子为根的子树中所有结点的关键字值都小于右孩子结点元素的关键字;以中孩子为根的子树中所有结点的关键字值都大于左孩子结点元素的关键字而小于右孩子结点元素的关键字;而以右孩子为根的子树中所有结点的关键字值都大于右孩子结点元素的关键字。
- 4)所有叶子点都在树的同一层。
一棵2-3树
2-3树 的结点
2-3树的结点如下所示:
struct two_three { element data_l, data_r; two_three *left_child; two_three *middle_child; two_three *right_child; };假设任何元素的关键字值都不等于 INT_MAX ,并且 2结点 的 data_r.key=INT_MAX ,其唯一的元素存放在 data_l 域中,其 left_child 域和 middle_child 域分别指向它的两个儿子,将right_child 域置为 NULL。
2-3树 的查找
2-3 树 的查找类似二叉平衡树的查找过程。
假设我们在 2-3树 t 上查找元素的关键字值等于 x 的结点,假定关键字值为整数。在进行查找时,一共有四种情况:
- 1)x 小于第一个关键字。
- 2)x 位于第一个关键字和第二个关键字之间。
- 3)x 大于第二个关键字。
- 4)x 等于结点中某个关键字
参考代码
two_three *search23(two_three *t, element x) { while(t) { if (x data_l) { t = t->left_child; } else if (x > t->data_l && x data_r) { t = t->middle_child; } else if (x > t->data_r) { t = t->right_child; } else { return t; } } return NULL; }
通过分析,可以发现 while 循环的重复次数不会超过 2-3树的高度。因此,如果树 t 包含 n 个结点,则函数 search23 的时间复杂度为O(logn)。
2-3树 的插入
若原 2-3树 为空,则直接插入结点,若原 2-3树 非空,在插入之前需要对带插入的结点进行一次查找操作。若树中已经有此结点则不进行插入操作。若没有此结点,进行插入操作,此时插入有两种情况。
- 1)向 2 结点的树中插入新结点
- 2)向 3 结点的树中插入新结点
向 2 结点中插入新结点
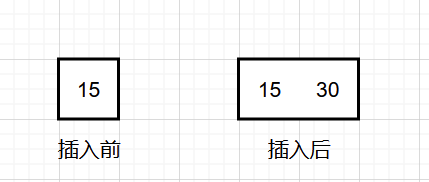
此时叶子结点里面就只有一个元素,那么插入之后正好两个元素,符合 2-3 树 的要求,直接插入。
插入关键字值为 30 的元素。
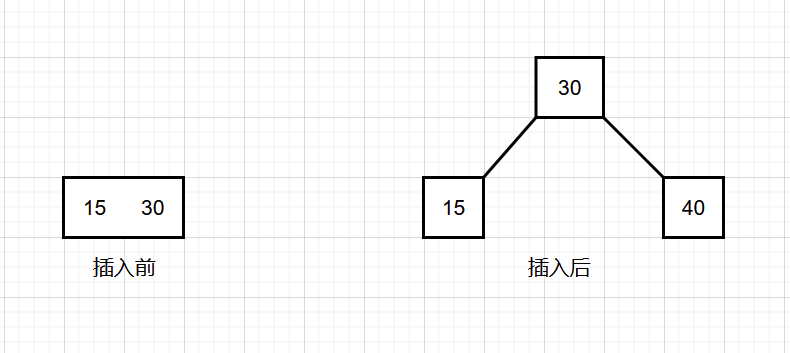
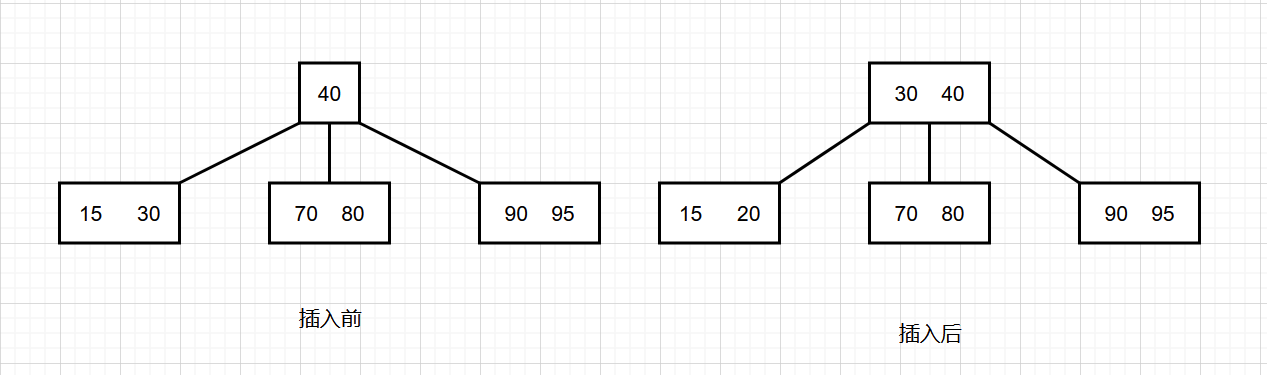
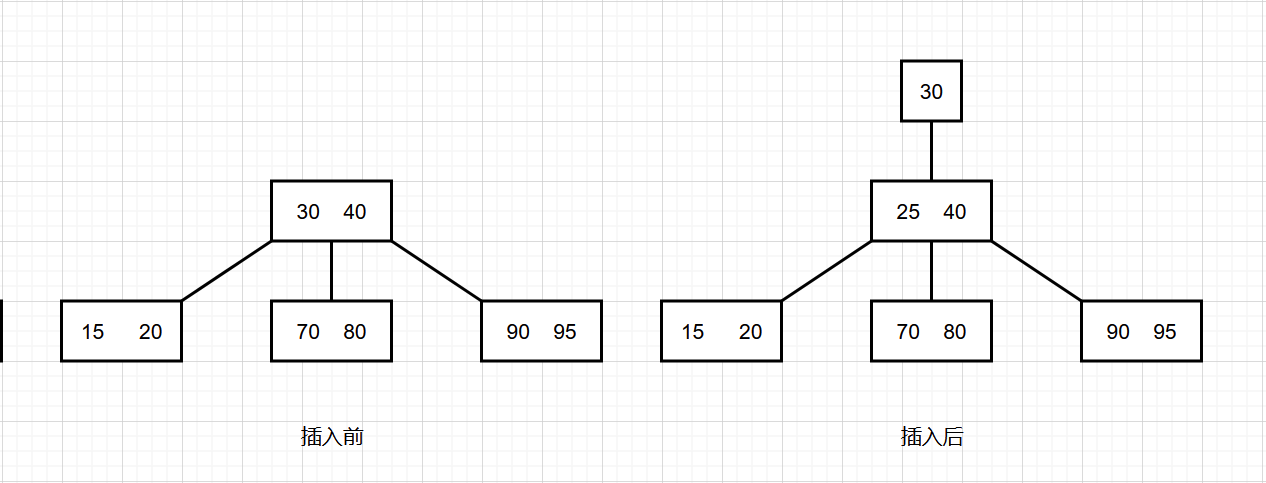
向 3 结点中插入新结点
此时这个叶子结点里面已经有两个元素了,插入后就有三个元素,那么就把叶子结点中间的元素传给父结点,自己分裂成两个结点。再看父结点,如果接收之后父结点也变成了 3结点,那么就一直重复这个过程,直到根结点。
插入关键字值为 35 的元素。
插入关键字值为 20 的元素。
插入关键字值为 25 的元素。
图解过程:
这样文字描述很难了解插入的过程,我用画图的方法展示一下向 2-3树 中插入 0-9 的过程。
参考代码:
two_three_ptr search23(two_three_ptr t,element x) { while(t){ switch(compare(x,t)){// 比较大小,返回情况1,2,3,4 case 1:t=t->left_child; break; case 2:t=t->middle_child; break; case 3:t=t->right_child; break; case 1:return t; } } return NULL: } void insert23 (two_three_ptr *t,element y) { two_three_ptr q,p,temp; if(!(*t))//如果树为空 new_root(t,y,NULL); else{ p=find_node(*t,y); if(!p){ cout<<"该结点在树中"<data_r.key==INT_MAX){//二结点 put_in(&p,y,q); break; } else{//三结点 split(p,&y,&q); if(p==*t){ new_root(t,y,q); break; } else{ p=s->pop(); } } } } }该函数调用了以下几个函数:
- 1)new_root:输入新根的左子树,新根存放的单个元素和新根的中子树,返回指向新根的指针。
void new_root(two_three *&left, element y, two_three *middle) { two_three *p = new two_three; p->left_child = left; p->middle_child = middle; p->right_child = NULL; p->data_l = y; p->data_r = MAX; left = p; }
- 2)find_node:在一棵非空的 2-3树 t 中查找关键字值为 y. key 的元素。如果 t 中存在关键字值为 y. key 的元素,则返回 NULL,否则返回查找过程中遇到的叶结点 p。此外, find_node还会创建一个全局的栈结构,以便得到从叶结点 p 到根结点 t 的路径上所有 p 的祖先结点。这个栈结构依次保存从最近祖先结点到最远祖先结点的结点表。由于在拆分结点时需要访问拆分结点的父结点,所以要使用这个结点表。
two_three *find_node(two_three *t, element x, stack *&s) { while(t) { s->push(t); if (x data_l && t->left_child) { t = t->left_child; } else if (x > t->data_l && x data_r && t->middle_child) { t = t->middle_child; } else if (x > t->data_r && t->right_child) { t = t->right_child; } else if (x == t->data_l || x == t->data_r) { return NULL; } else { return s->pop(); } } }
- 3)put_in:该函数将元素 y 插到只包含一个元素的结点 p 中,并将子树 q 直接放在 y 的右侧。因此,如果 y 变为 data_l,则 q 就变为 middle_child ,原来的 data_l 和 middle child 分别右移变成 data_r 和 right_child。如果 y 变为 data_r,则 q 就变成right_child。
void put_in(two_three *p, element x, two_three *q) { if(p->data_l data_r = x; p->right_child = q; } else { p->right_child = p->middle_child; p->middle_child = q; p->data_r = p->data_l; p->data_l = x; } }
- 4)split:该函数的输入为包含两个元素的结点 p,其功能是创建一个新结点 q。新结点 q 将存放 p 中原来的两个元素与元素 y 三者中关键字值最大的元素。三者中关键字值最小的元素将成为 p 中的唯一元素。p 中原有的三个子树指针和指针 q 分别存放在 p 结点和新建结点的四个儿子域中。函数返回时,y 为关键字值处于中间大小的元素,q 为指向新建结点的指针。
void split(two_three *p, element &x, two_three *&q) { element min, max; if(x data_l) { min = x; max = p->data_r; x = p->data_l; } else if (x > p->data_r) { min = p->data_l; max = x; x = p->data_r; } else { min = p->data_l; max = p->data_r; } two_three *n = new two_three; n->data_l = max; n->data_r = MAX; n->left_child = p->right_child; n->middle_child = q; n->right_child = NULL; p->data_l = min; p->data_r = MAX; p->right_child = NULL; q = n; }
2-3树 的删除
在删除之前需要对要删除的结点进行一次查找操作。若树中没有此结点则不进行删除操作。
如果要删除的元素不在叶子结点中,可以用一个叶子结点中的适当元素与待删除元素进行交换,从而将该删除操作转换成在叶结点上的删除操作。一般情况下,可以用被删除元素左子树中的关键字值最大的元素或者右子树中关键字值最小的元素与该元素进行交换。
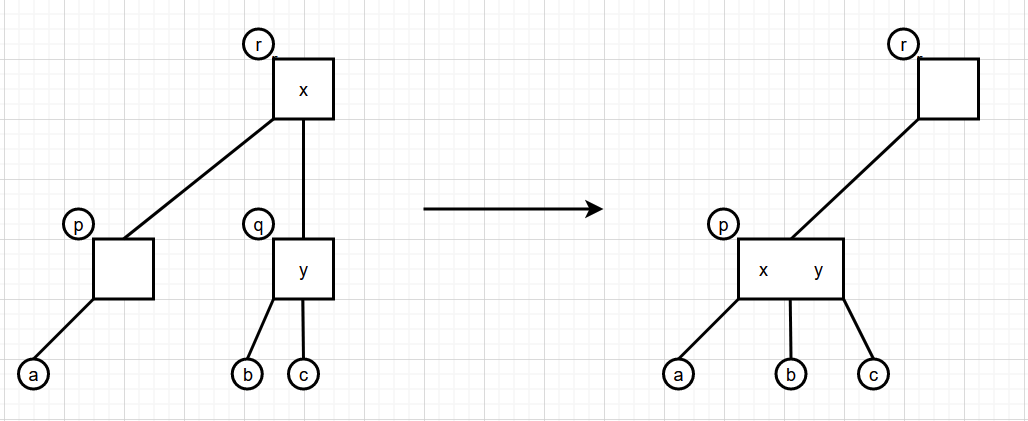
如果要删除的叶子结点是 3结点 ,直接把元素删除了就可以了,不会破坏2-3 B树的任何性质。如果要删除的叶子结点是 2结点 ,直接删除的话就不符合 2-3树 的性质了。类似于平衡二叉树(AVL),此时就需要进行旋转或合并操作了。
根据要删除结点 p 是父结点 f 的左孩子,中间孩子还是右孩子,旋转,合并可以分为六种情况。
1.p是r的左结点旋转
2.p是r的中结点旋转
3.p是r的右结点旋转
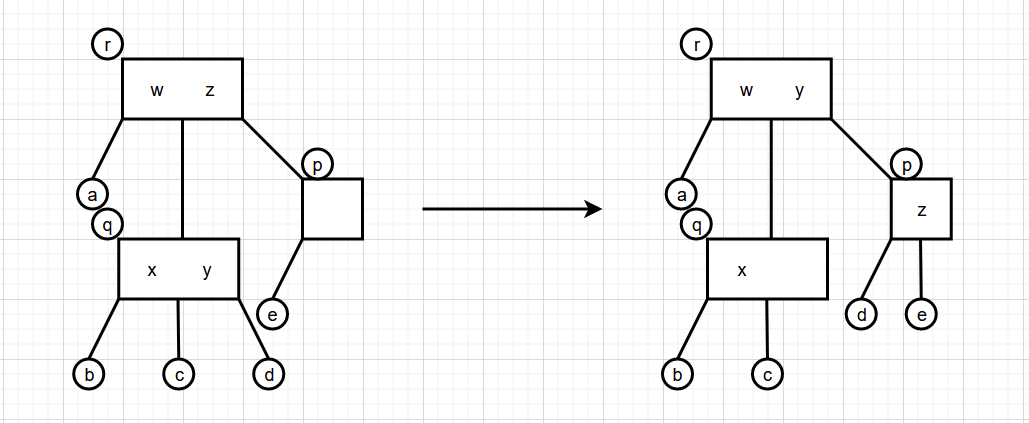
4.p是r的左结点合并
中结点和右结点的合并也差不多,这里就不在详细描述了。