该篇文章已经被专栏《从零开始学k8s》收录

k8s污点、容忍度和pod状态
- 污点容忍度
- Pod 常见的状态和重启策略
- 常见的 pod 状态
- pod 重启策略
- 写在最后
污点容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod
taints 是键值数据,用在节点上,定义污点
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点
pod 亲和性是 pod 属性;但是污点是节点的属性,污点定义在 nodeSelector 上
[root@k8smaster ~]# kubectl describe nodes k8smaster
Taints: node-role.kubernetes.io/master:NoSchedule
[root@k8smaster ~]# kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required-
Required. The effect of the taint on pods that do not tolerate the taint.
Valid effects are NoSchedule, PreferNoSchedule and NoExecute.
key <string> -required-
Required. The taint key to be applied to a node.
timeAdded <string>
TimeAdded represents the time at which the taint was added. It is only
written for NoExecute taints.
value <string>
The taint value corresponding to the taint key.
#taints 的 effect 用来定义对 pod 对象的排斥等级(效果)
NoSchedule:
仅影响 pod 调度过程,当 pod 能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的 pod 不能容忍了,那这个 pod 会怎么处理,对现存的 pod 对象不产生影响
NoExecute:
既影响调度过程,又影响现存的 pod 对象,如果现存的 pod 不能容忍节点后来加的污点,这个 pod 就会被驱逐
PreferNoSchedule:
最好不,也可以,是 NoSchedule 的柔性版本,如果没有定义容忍度会到这里
在 pod 对象定义容忍度的时候支持两种操作:
1.等值密钥:key 和 value 上完全匹配
2.存在性判断:key 和 effect 必须同时匹配,value 可以是空
在 pod 上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,每一个污点都能被容忍,才能完成调度,如果不能容忍怎么办,那就需要看 pod 的容忍度了
[root@k8smaster ~]# kubectl describe nodes k8smaster
查看 master 这个节点是否有污点,显示如下:

上面可以看到 master 这个节点的污点是 Noschedule
所以我们创建的 pod 都不会调度到 master 上,因为我们创建的 pod 没有容忍度
[root@k8smaster ~]# kubectl describe pods kube-apiserver-k8smaster -n kube-system
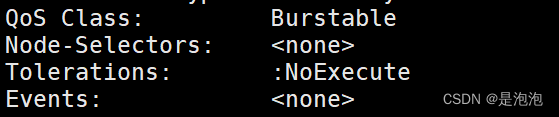
可以看到这个 pod 的容忍度是 NoExecute,则可以调度到 master1 上
#管理节点污点
[root@k8smaster ~]# kubectl taint --help
例:把 node2 当成是生产环境专用的,其他 node 是测试的
[root@k8smaster ~]# kubectl taint node k8snode2 nodetype=production:NoSchedule
node/k8snode2 tainted
给 node2 打污点,pod 如果不能容忍就不会调度过来
[root@k8smaster ~]# vim pod-taint.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat
imagePullPolicy: IfNotPresent
#yaml没有写污点容忍,所以调度不过去。
[root@k8smaster ~]# kubectl apply -f pod-taint.yaml
pod/taint-pod created
[root@k8smaster ~]# kubectl get pods -o wide
NAME READY STATUS NODE NOMINATED NODE
taint-pod 1/1 Running k8snode <none>
可以看到都被调度到 node1 上了,因为 node2 这个节点打了污点,而我们在创建 pod 的时候没有容忍度,所以 node2 上不会有 pod 调度上去的。
给 node1 也打上污点
[root@k8smaster ~]# kubectl delete -f pod-taint.yaml
[root@k8smaster ~]# kubectl taint node xianchaonode1 node-type=dev:NoExecute
[root@k8smaster ~]# kubectl get pods -o wide
显示如下:
[root@k8smaster node]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
taint-pod 0/1 Pending 0 37s <none> k8snode <none>
上面可以看到已经存在的 pod 节点都被撵走了
[root@k8smaster node]# vim pod-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: nginx
ports:
- name: http
containerPort: 80
tolerations:
- key: "node-type"
operator: "Equal"
value: "production"
effect: "NoExecute"
tolerationSeconds: 3600
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8smaster node]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy 0/1 Pending 0 16s
还是显示 pending,因为我们使用的是 equal(等值匹配),所以 key 和 value,effect 必须和node 节点定义的污点完全匹配才可以,把上面配置 effect: "NoExecute"变成 effect: "NoSchedule"成,tolerationSeconds: 3600 这行去掉.
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy2 created
[root@k8smaster node]# kubectl get pods
myapp-deploy 1/1 Running 0 17s k8snode2
上面就可以调度到 node2 上了,因为在 pod 中定义的容忍度能容忍 node 节点上的污点
#再次修改
tolerations:
- key: "node-type"
operator: "Exists"
value: ""
effect: "NoSchedule"
只要对应的键是存在的,exists,其值被自动定义成通配符
[root@k8smaster node]# kubectl delete -f pod-demo-1.yaml
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
[root@k8smaster node]# kubectl get pods
发现还是调度到 node2 上
myapp-deploy 1/1 Running 0 17s k8snode2
再次修改
tolerations:
- key: "node-type"
operator: "Exists"
value: ""
effect: ""
有一个 node-type 的键,不管值是什么,不管是什么效果,都能容忍
[root@k8smaster node]# kubectl delete -f pod-demo-1.yaml
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
[root@k8smaster node]# kubectl get pods -o wide
myapp-deploy 1/1 Running 0 17s k8snode
可以看到 node2 和 node 节点上都有可能有 pod 被调度
删除污点:
[root@k8smaster node]# kubectl taint nodes xianchaonode1 node-type:NoExecute-
[root@k8smaster node]# kubectl taint nodes xianchaonode2 node-type-
Pod 常见的状态和重启策略
常见的 pod 状态
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。熟悉 Pod 的各种状态对我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。
下面是 phase 可能的值,也就是 pod 常见的状态:
挂起(Pending): 我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成,处于 pending的状态会持续一段时间:包括调度 Pod 的时间和通过网络下载镜像的时间。
运行中(Running): Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded): Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed): Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
未知(Unknown): 未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的 kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上kubelet,得不到信息了,就会 Unknown
还有其他状态,如下
Evicted 状态: 出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker 镜像。
CrashLoopBackOff: 容器曾经启动了,但可能又异常退出了 看日志解决
Error 状态: Pod 启动过程中发生了错误
pod 重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据 RestartPolicy 的设置来进行相应的操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
Always:当容器失败时,由 kubelet 自动重启该容器。
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。
[root@xianchaomaster1 ~]# vim pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
spec:
restartPolicy: Always
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat
imagePullPolicy: IfNotPresent
写在最后
创作不易,如果觉得内容对你有帮助,麻烦给个三连关注支持一下我!如果有错误,请在评论区指出,我会及时更改!
目前正在更新的系列:从零开始学k8s
感谢各位的观看,文章掺杂个人理解,如有错误请联系我指出~





